How to choose incident management software
April 9, 2026 — 23 min read
Choosing the best software for incident management isn't about picking the tool with the longest feature list. It's about finding the platform that fits your team's workflows, integrations, and compliance requirements. Incident management software is a platform that centralizes alerting, on-call scheduling, escalations, and postmortems to help teams detect, respond to, and learn from service disruptions in a coordinated way. Before evaluating any vendor, standardize your incident response process to get full value from whatever tool you adopt. This guide provides a repeatable selection methodology that engineering leaders, SREs, and IT operations teams can apply immediately to make a confident, defensible purchasing decision.
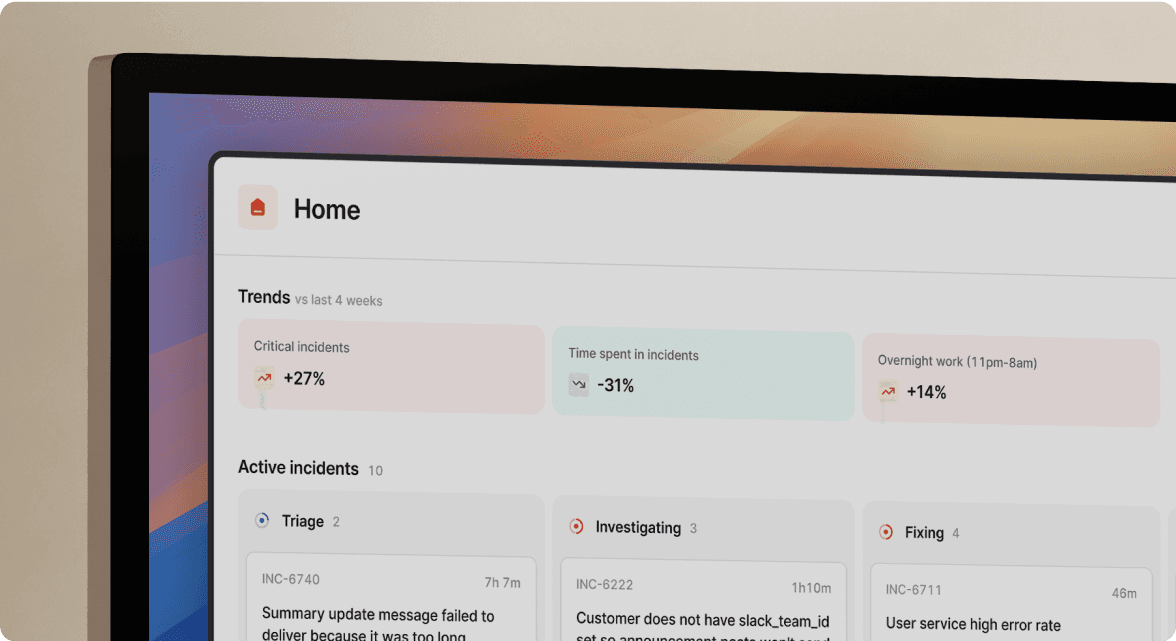
incident.io is an example of a Slack-native incident management platform built to centralize these capabilities and keep responders working in a single communication context.
Criterion
What it measures
Why it matters
Alert routing and noise reduction
Deduplication, correlation, prioritization
Prevents alert fatigue and surfaces real issues
On-call management and escalation
Rotation fairness, escalation clarity, shift swaps
Ensures the right person responds quickly
Incident lifecycle management
End-to-end tracking from declaration to resolution
Maintains visibility and accountability
Postmortem and action tracking
Structured templates, action-item sync
Drives organizational learning and prevents recurrence
AI-powered context and root cause analysis
Automated log/metric surfacing, suggested causes
Reduces mean time to resolution
Automated workflows and runbooks
Triggered automation, reduced manual steps
Speeds response during high-pressure incidents
Real-time collaboration and ChatOps
Native Slack/Teams integration
Keeps responders in their natural workflow
Reporting and analytics
Trend dashboards, KPI tracking
Enables continuous improvement
Compliance and audit support
Exportable logs, RBAC, evidence exports
Satisfies regulatory requirements
Customization and workflow flexibility
Configurable forms, templates, dashboards
Adapts to your processes without engineering effort
Understand your incident management needs
Before evaluating any vendor, document your current incident landscape. This foundation prevents costly mis-purchases and accelerates shortlisting. Start by mapping your team size, on-call patterns, existing monitoring and ticketing tools, SLOs, and compliance obligations. These factors determine which platform will actually fit your organization rather than which one looks best in a demo.
Understand the distinction between incident response and incident management. Incident response covers immediate tactical actions like detection, triage, and containment. Incident management encompasses long-term coordination, communication, and organizational learning. The NIST incident response framework provides a useful mental model with its four phases: Preparation; Detection and Analysis; Containment, Eradication, Recovery; and Post-Incident Activity. Different tools emphasize different phases, so knowing where your gaps are helps focus your evaluation.
Consider whether your organization follows ITIL or SRE practices, as this shapes which features matter most. ITIL-aligned teams typically prioritize governance and change management workflows. SRE teams weight SLO tracking, automated runbooks, and observability depth more heavily. Neither approach is wrong, but the mismatch between your methodology and your tooling creates friction.
Inventory your observability sources using the MELT framework: Metrics, Events, Logs, and Traces. This comprehensive approach to observability helps you evaluate integration depth accurately during vendor comparisons.
Needs-mapping checklist:
- Team size and geographic distribution
- On-call rotation model (follow-the-sun, weekly, hybrid)
- Compliance frameworks (SOC2, ISO 27001, HIPAA)
- Current monitoring tools (Datadog, Prometheus, Grafana, others)
- Communication platforms (Slack, Microsoft Teams)
- Ticketing systems (Jira, ServiceNow, Linear)
- SLO targets and current performance against them
For a deeper look at how response and management capabilities fit together, see the modern incident management software stack.
Evaluate core incident management features
With your requirements documented, you can now evaluate vendors against a structured feature framework. This transforms vague feature comparison into a weighted, actionable scoring exercise. The following ten criteria should form the backbone of your evaluation.
1. Alert routing and noise reduction Look for deduplication, correlation, and prioritization capabilities that reduce alert noise and prevent fatigue. A good platform groups related alerts, suppresses duplicates, and helps responders focus on what actually matters.
2. On-call management and escalation: Effective on-call management enforces fair rotations, clear escalation paths, and simple shift swaps. The tool should make it obvious who is responsible and automatically escalate when acknowledgment windows expire.
3. Incident lifecycle management End-to-end tracking from declaration through resolution keeps everyone aligned. Look for automated status page updates and stakeholder communication that doesn't require manual effort during response.
4. Postmortem and action tracking The best tools include structured postmortem templates and action-item tracking integrated with Jira or GitHub. Without this integration, action items get lost and the same incidents recur.
5. AI-powered context and root cause analysis: AI-driven incident tools surface related logs, metrics, and dependencies while suggesting potential root causes.This capability is increasingly critical for reducing mean time to resolution, especially as systems grow more complex.
6. Automated workflows and runbooks Runbook-triggered automation cuts manual steps and speeds response during high-pressure incidents. Evaluate what automations are available out of the box versus what requires custom scripting.
7. Real-time collaboration and ChatOps Native ChatOps integrations with Slack and Microsoft Teams keep responders in their natural workflow. Bolted-on chat features that require context switching defeat the purpose.
8. Reporting and analytics Dashboards for trends and KPIs like mean time to acknowledge (MTTA), mean time to resolve (MTTR), and incident frequency drive continuous improvement. Without visibility into patterns, you can't improve systematically.
9. Compliance and audit support: Exportable logs, role-based access control, and evidence exports for SOC2 and ISO audits are non-negotiable for regulated industries. Even if you're not regulated today, these capabilities become important as you scale.
10. Customization and workflow flexibility Look for customization options including forms, workflows, notification templates, and dashboards that adapt to your processes without requiring engineering effort.
Weight these criteria based on your organizational priorities. A regulated fintech will weight compliance higher, while a fast-moving startup may prioritize speed and ChatOps. Create a simple scorecard where you rate each vendor 1-5 across all ten criteria, then multiply by your priority weights.
For a broader view of available options, see the overview of nine incident management solutions (including incident.io).
Assess integrations with your existing tools
Integration quality matters more than integration quantity. A platform with 700 connectors that only sync one-way is less valuable than one with 50 deep, bi-directional integrations. Pre-built connectors that handle edge cases are better than generic APIs that require custom development to be useful.
Organize your integration evaluation into four categories:
Category
Key tools
What to verify
Observability
Datadog, Grafana, Prometheus, New Relic
Bi-directional alert sync, metric context in incidents
Communication
Slack, Microsoft Teams
Native workflows, not just notification webhooks
Ticketing and project management
Jira, ServiceNow, Linear, Asana
Two-way sync of status, assignees, and comments
Source control and CI/CD
GitHub, GitLab, deployment tools
Linking incidents to code changes and deploys
Don't just verify that integrations exist on a features page. Test them during your trial. Confirm that alerts, incidents, and tickets stay in sync without manual copying. Check whether context from your monitoring tools actually appears in the incident timeline or whether responders still need to switch tabs.
incident.io's Slack-native approach exemplifies deep integration versus bolted-on chat features. Rather than sending notifications to Slack, the entire incident workflow happens within Slack, eliminating context switching. For more on this approach, see the guide to Slack-native incident management platforms.
Test usability and team workflow fit
A user-friendly interface ensures fast adoption during crises. But you can't evaluate usability in a calm demo environment. You need to test under simulated incident pressure, because a tool that's hard to use during a 2 a.m. incident will be abandoned regardless of its feature set.
Evaluate these usability dimensions:
Time to first incident: How quickly can a new on-call engineer declare and manage an incident without documentation? If they need to read a manual or ask for help, adoption will suffer.
Cognitive load during response: Does the tool surface the right context automatically, or does the responder have to hunt for information across multiple screens? The best platforms reduce cognitive load through automation, context surfacing, and clear communication channels.
Mobile accessibility: Can responders acknowledge and manage incidents from mobile devices? On-call engineers aren't always at their desks when alerts fire.
Onboarding curve: How long does it take a new team member to become proficient? Look for training videos, guided tours, and templates that accelerate learning.
Involve actual on-call engineers in the evaluation, not just managers. The people who will use the tool at 3 a.m. have different priorities than those who will review reports on Monday morning. Run the tool through a realistic scenario: a P1 incident at off-hours with an engineer who wasn't part of the evaluation process. Their experience reveals the true usability of the platform.
For guidance on what new on-call engineers need from their tools, see incident management tools for new on-call engineers.
Validate compliance, governance, and audit capabilities
Skipping compliance validation can result in expensive rework when you discover gaps during an actual audit. Especially in regulated industries, confirm that your chosen platform meets requirements before you commit.
Being audit-ready in the context of incident management means having platforms with audit logs, templated postmortems, and SOC2 or ISO exports. Verify these specific capabilities:
Audit logs: Immutable, timestamped records of all incident actions and decisions. You need to show auditors exactly who did what and when during every incident.
Role-based access control: Ensure security and compliance through RBAC that limits who can declare incidents, modify configurations, and access sensitive information. This isn't just about security; it's about demonstrating proper controls.
Evidence exports: The ability to export complete incident timelines, communications, and postmortems as audit artifacts. Manual compilation of this evidence is time-consuming and error-prone.
Structured documentation: Incident management must support structured documentation, task tracking, and evidence exports that satisfy audit requirements without additional effort.
Compliance checklist:
- [ ] SOC2 Type II certification or attestation
- [ ] ISO 27001 compliance support
- [ ] HIPAA capabilities (for healthcare-adjacent teams)
- [ ] GDPR data residency options
- [ ] FedRAMP authorization (for government work)
Compliance is not just about the tool. It's about the process the tool enforces. The best platforms make compliant behavior the default, not an extra step that responders skip under pressure.
For enterprise-specific considerations, see incident management tools for enterprise.
Consider scalability, customization, and automation
What works for a 10-person team may collapse at 100. Consider scalability and performance so the platform grows with your business rather than becoming a bottleneck.
Scalability Evaluate how the platform handles increasing alert volumes, larger on-call rotations, and multi-team coordination. Does it support multiple teams, services, and severity levels? Can it handle enterprise-scale alert volumes without performance degradation? Ask vendors specifically about their largest customers and how they handle peak load.
Customization Can workflows, incident forms, notification templates, and dashboards be tailored without engineering effort? Look for no-code or low-code configuration that lets operations teams adapt the tool to evolving processes. If every change requires a support ticket or custom development, you'll outgrow the tool quickly.
Automation Key incident system features include real-time alerts, automated response plans, and robust communication capabilities. Evaluate runbook automation, auto-escalation, automated status page updates, and AI-assisted triage. The more you can automate, the faster you respond and the less you depend on tribal knowledge.
Ask vendors these specific questions during demos:
- How do you handle multi-team incidents with different escalation policies?
- Can we create custom workflows without developer involvement?
- What automation triggers are available out of the box versus requiring custom scripting?
For teams running complex infrastructure, see incident management tools for DevOps, Kubernetes, and microservices.
Analyze total cost of ownership and ROI
A cheaper tool that doesn't reduce mean time to resolution is more expensive than a premium one that does. Move beyond sticker price to understand the full financial picture.
Total cost of ownership includes:
- Licensing or subscription fees (per-seat, per-incident, or flat-rate models)
- Migration and implementation costs (data migration, integration setup, process redesign)
- Training and onboarding time (both initial and ongoing for new hires)
- Ongoing maintenance and administration overhead
- Opportunity cost of downtime during migration
ROI centers on measurable incident management metrics:
- MTTR reduction: Quantify the cost of downtime per minute and project savings from faster resolution. If your downtime costs $10,000 per minute and a new tool reduces MTTR by 15 minutes per incident, the math becomes clear quickly.
- Reduced repeat incidents: Effective postmortem tracking with action items synced to Jira or GitHub means fixes actually land, reducing recurrence.
- Engineer productivity: Less time spent on manual alerting, status updates, and report generation frees engineers for higher-value work.
- Compliance cost avoidance: Automated audit trails reduce the labor cost of preparing for SOC2 and ISO audits.
Simple ROI calculation framework:
``` ROI = (Cost of downtime saved + Engineer hours recovered + Compliance labor saved) - TCO ```
Watch for hidden fees during vendor negotiations. Per-integration charges, overage costs, and premium support tiers can significantly increase actual spend beyond the quoted price. Include migration effort, training, and long-term pricing as explicit line items in any TCO analysis.
Conduct real-world trials and tabletop drills
A structured trial prevents the common mistake of choosing software based on a polished sales demo. Run a two to three week trial with real on-call traffic before committing. This means routing actual alerts, using real on-call schedules, and running through the full incident lifecycle.
Step-by-step trial protocol:
- Set up real integrations: Connect to your actual monitoring, chat, and ticketing tools, not sandbox versions. If the integrations don't work with your real data, you'll discover problems before you've committed.
- Run with live alerts: Route production alerts through the platform for at least two full on-call rotations. This reveals how the tool handles your actual alert volume and patterns.
- Conduct a tabletop drill: Simulate a P1 incident with a cross-functional team. Observe how the tool handles escalation, communication, and handoffs. Note where responders get confused or frustrated.
- Complete a full postmortem: Use the platform's postmortem workflow to document the drill and assign action items. Evaluate template quality and Jira or GitHub sync.
- Validate observability and AI features: Confirm access to MELT data and any automated context or analysis capabilities during the trial. Features that don't work with your specific stack are features you don't have.
- Collect team feedback: Survey all participants on usability, information quality, and pain points. Quantify sentiment so you can compare across vendors.
The trial should verify both technical fit and human factors. Test with engineers who weren't involved in the selection process to surface adoption friction that insiders might overlook. Document trial outcomes in a structured comparison matrix aligned with the ten criteria from the feature evaluation section.
Make a final decision based on team feedback and metrics
Synthesize trial data, team sentiment, and business requirements into a confident purchasing decision. Gather structured feedback from three stakeholder groups:
On-call engineers: Focus on usability, cognitive load, mobile experience, and alert quality. These are the people who will use the tool under pressure.
Engineering managers: Evaluate reporting, postmortem quality, and integration with project management tools. They need visibility and accountability.
Security and compliance leads: Verify audit capabilities, RBAC, and evidence export quality. They're accountable for regulatory requirements.
Consolidate feedback into the feature evaluation scorecard, with weighted scores reflecting organizational priorities. Then work through the final decision checklist:
- [ ] Trial completed with real alerts and on-call rotations
- [ ] Postmortem workflow tested end-to-end
- [ ] Compliance requirements validated with security team
- [ ] Integration depth confirmed (not just existence)
- [ ] TCO and ROI model reviewed with finance
- [ ] Team adoption sentiment is positive across roles
- [ ] Vendor support responsiveness verified during trial
Choose the platform that best reduces cognitive load during incidents, enforces consistent processes, and generates actionable learning. The best software for incident management isn't the one with the most features on a comparison page. It's the one that fits your team's actual workflow and helps you get better at responding to incidents over time.
For examples of how organizations have successfully implemented incident management software, see incident.io customer stories.
Frequently asked questions
What are the essential features to look for in incident management software?
The essential features include automated alert routing and noise reduction, on-call scheduling with fair rotations, real-time collaboration via ChatOps, structured postmortem templates with action tracking, and AI-powered root cause analysis to reduce mean time to resolution.
How important are integrations with monitoring and communication tools?
Integrations are critical. Incident management software should offer deep, bi-directional connectors with your observability stack, communication platforms like Slack or Microsoft Teams, and ticketing systems like Jira to eliminate manual data copying and context switching.
How can incident management software improve response times?
The right software reduces response times by automating alert correlation and escalation, surfacing relevant context instantly, and keeping all responders coordinated in a single communication channel so no time is lost switching between tools. Slack-native platforms like incident.io help keep coordination in one place.
What should I consider for compliance and audit requirements?
Look for immutable audit logs, role-based access control, templated postmortems, and the ability to export complete incident timelines as evidence for frameworks like SOC2, ISO 27001, or HIPAA to ensure you're always audit-ready.
How do I evaluate the scalability and support for growing teams?
Test whether the platform handles increasing alert volumes, supports multiple teams with different escalation policies, and offers customizable workflows without requiring engineering effort. Verify that vendor support is responsive during your trial period, not just during the sales process.

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

