Our guide to creating your own incident management software stack
October 17, 2022 — 10 min read

Things have changed!
When we wrote this, incident.io relied on integrations with tools like PagerDuty and Statuspage to provide a complete incident management experience.
Now, we do it all.
We’re fortunate enough to speak to a huge number of companies about their incident management processes. In doing so, we’ve noticed an emergent trend in how modern companies are using software to support their incident management processes, and a common set of challenges faced by them too.
When it comes to functionality, there’s a small number of key activities that most businesses need to consider:
- Collaborating internally as part of your incident response
- Getting escalations and notifications to the right people
- Communicating with customers in real-time
- Having a consistent way to track follow-up work
- Documenting processes and learnings so others in the organization can benefit
For each of these activities, there's a number of available tools to support, but the stack we're seeing more often than any other uses:
- Slack for collaboration
- PagerDuty for escalations
- Statuspage.io for customer comms
- Jira for follow-up work
- Google docs for writing and collaborating on incident debriefs.
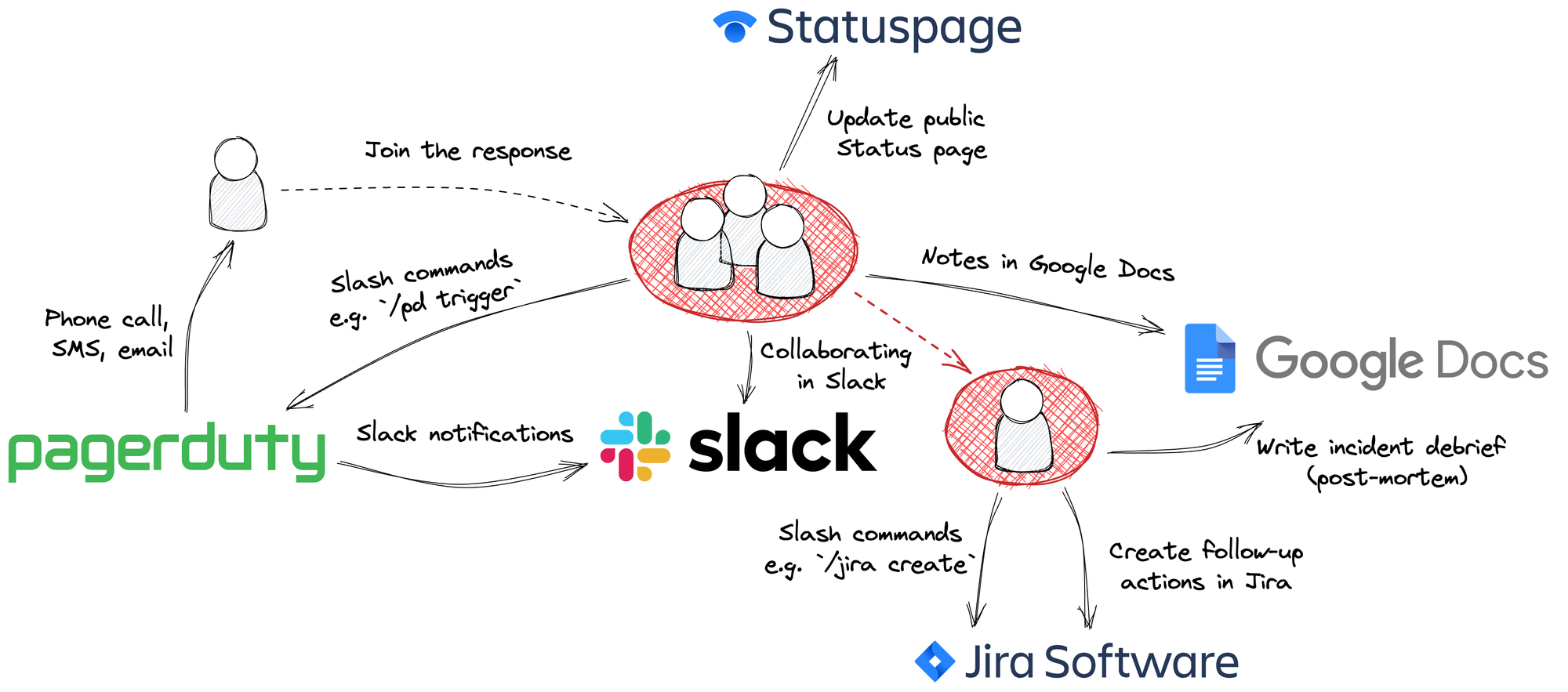
Whilst this is by far the most common stack we see across organizations today, it’s not hitting the mark. In this post, we’ll go a little deeper on how each of these tools fit within the broader incident management picture, outline the pain points felt by those using this combination of products, and discuss how incident.io can bring them together in way that makes them far more powerful than the sum of their parts.
Slack for collaborating across incidents
Slack has fast become the most important component of organizations' incident response processes. It’s one of the few tools that exist universally across an entire organization, irrespective of department or job function. Since the best run incidents are founded on rock-solid communication, it follows that Slack is so prevalent.
When we look at how Slack is used in the overall picture of incident response, it’s most commonly integrated through the use of dedicated incident channels created as part of a manual workflow or through some automation.
Since Slack also has a rich app ecosystem, it’s common to find folks using Slash commands with individual tools. Whilst it's great to be able to use these tools without leaving Slack, their interfaces are inconsistent, hard to remember, and as a result often confined to power users. Very few non-engineers are using /pd to trigger incidents, or /jira to log important follow-up work.
Top alternatives: Microsoft teams, Discord
PagerDuty for on-call notifications and escalations
PagerDuty is the de facto standard for notification infrastructure. Once an organization has decided they need round-the-clock on-call cover, PagerDuty is the tool that allows them to set up on-call schedules and escalation policies, and plug them into their automated monitoring systems.
Few companies we speak to use PagerDuty outside of an engineering context, so it’s involvement in incidents tends to stop once a person has been ‘paged’ – i.e. getting a phone call, SMS or push notification on your mobile app.
The incident management tools offered by PagerDuty don’t appear to be commonly used, with many folks citing the overly engineering focused user experience and the fact that they’re communicating inside Slack as the main reasons.
When it comes to scheduling people to be on-call and reliably making phones make noises, PagerDuty has earned its place on the top spot.
Top alternatives: Opsgenie, VictorOps/Splunk On-call
Statuspage for communicating incidents to your customers
For many organizations, sharing real-time updates on incidents with their customers is either an afterthought, or not something they think about at all. There’s a common perception that talking publicly about your incidents will lead to lack of customer trust, when in our experience, and the experience of many of our customers, it’s exactly the opposite.
For those that are thinking about public comms, Atlassian’s Statuspage is the clear winner. Head to almost any company's status page – like status.incident.io – and you’ll see they’re using this product!
In the context of incidents, organizations are using Statuspage and their associated dashboards to communicate live status updates on an incident. The result? Happy customers who don’t leave angry messages with your customer support team!
Top alternatives: BetterUptime, Status.io
Jira for incident tracking and follow-up work
Whether it’s during the incident response process, or as part of the output of an incident debrief, team members involved in the incident need a place to log any post-incident work that needs to be done.
Whilst there’s a number of new kids on the block (we use and love Linear 😉) Jira, remains the most commonly used issue tracker. Whether you’re using their cloud-based SaaS offering or running on-premises, Jira is the issue tracking tool where teams are organising their work.
Aside from tracking work, we also see Jira being used for incident tracking, running help desks, and by IT teams as part of their overall ITSM process. It turns out when you’re product is based on moving tickets through a workflow, you can use it to cater for pretty much anything! We’ll reserve commenting on how end-users talk about their love of the product though.
Top alternatives: Github Issues, Linear, Shortcut, Asana, ServiceNow
Google docs for incident post-mortems
When the dust has settled and you’ve managed to get things back online, it’s common for organizations to run an incident debrief process. For many this looks like digging into contributing factors (aka root causes) and facilitating a learning process.
The common approach we see is to have a template in a Google doc that gets re-used for each new incident. This’ll include key incident information, commentary on the lifecycle of the incident, metrics and visualizations, and anything else that helps folks to understand what went on.
Top alternatives: Confluence, Notion, Slab
Connecting the stack
What’s interesting here is the absence of ergonomic connectivity between these tools. You can connect PagerDuty to Slack, and have Jira auto-escalate to PagerDuty, but there’s a missing substrate here that joins up the various software solutions. This results in one of two things happening:
- Organizations writing their own tooling to bring them together. This is rarely an active decision made by the organization, and as a result these projects end up heavily relied upon as critical infrastructure, whilst simultaneously being chronically understaffed.
- Humans being forced to absorb the complexity and pull the tools together following a process defined on paper. As you might expect, this approach rarely produces consistent results, and puts additional pressure on individuals when it’s least helpful.
How a modern incident management tool like incident.io can help
incident.io is a collaboration tool that exists within Slack during your incident response process. We natively integrate with the entire stack outlined above (plus many other products!) in a way that allows the entire organization to engage with the process. Incidents, after all, aren’t confined to engineers, and with more people engaging in the process we can leverage more expertise and experience to resolve things faster and more easily.

When it’s 2am and the your service is offline, nobody wants to be scrabbling around for their login details to access an unfamiliar system, and nor do they want to use a myriad of complicated Slash commands to run each tool individually through Slack.
With incident.io you can:
- Have anyone in your Slack organization kick off an incident in seconds with a single command.
- Get the right people in the room using PagerDuty, whether by manual escalation from within Slack, or as part of a custom automated workflow.
- Log corrective actions and follow-ups into Jira in seconds, without leaving the conversation.
- Update your customers in real-time using our native Statuspage integration. Moreover, you can optimize your process and configure automated nudges to remind you to do this on a regular basis.
- Gather evidence including messages, dashboards and visualizations and use them to build a timeline of the incident that can be exported to Google docs with a single click.
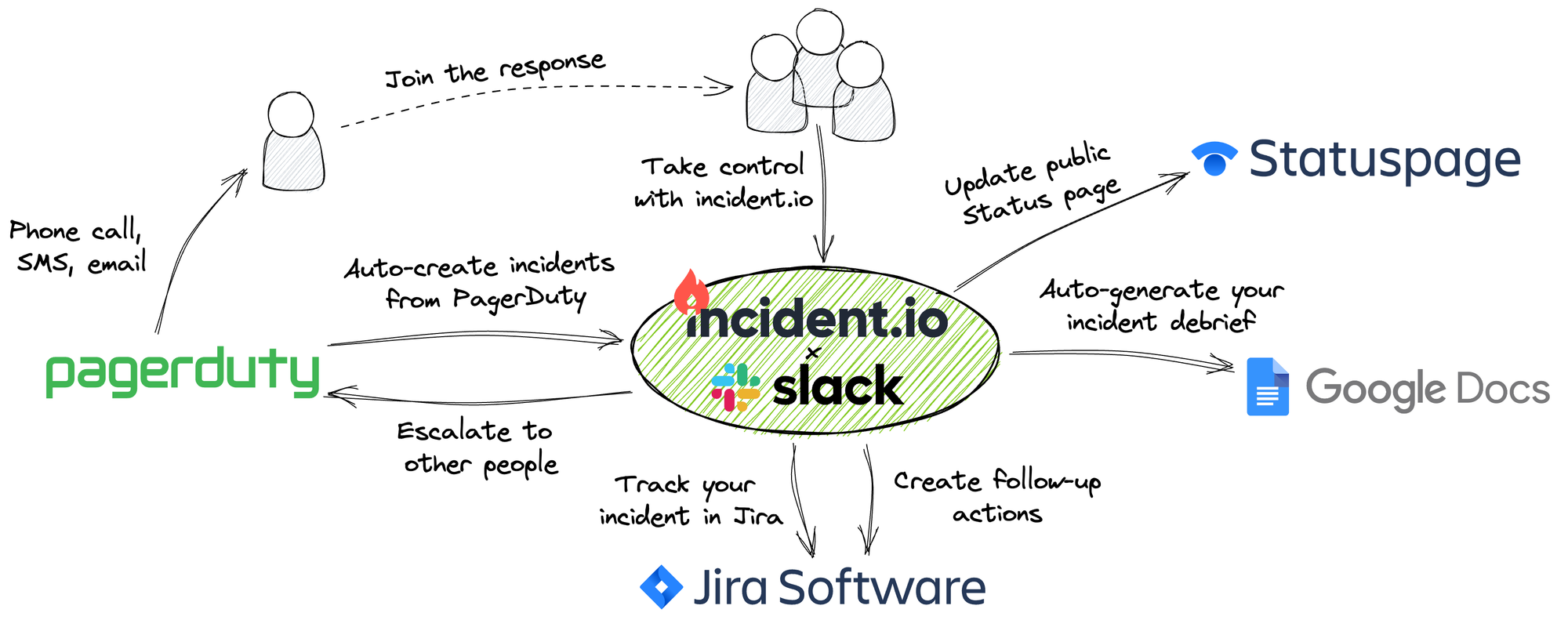
Once you’ve run an incident with incident.io, you’ll realise just how enjoyable it can be to have things going wrong in your organization. Ok, enjoyable might be stretch, but they’ll certainly require less effort whilst also delivering higher quality and more consistent output!
Don’t believe us, see what our customers are saying instead!

Chris Evans
Co-Founder & Field CTO
I'm one of the co-founders, and Field CTO here at incident.io.
See related articles


So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


