What is incident management? Understanding this critical business function.
December 9, 2022 — 11 min read

For many SMB and enterprise businesses, the approach to incident management is akin to an oil change—you know how important they are but usually wait until it’s too late to get one done.
But as businesses become more and more complex in their product offerings and the depth of their engineering, their approach to incident management can make or break them. In reality, incident management should be taken as seriously as your search for a payroll provider, executive hire, accounting tool, or CMS.
Unfortunately, this reactive approach leaves well-meaning businesses vulnerable to haphazard and frantic incident responses that can crush customer trust, industry rapport, and above all, your bottom line. But what exactly is incident management and why can it be so impactful?
Here, we'll give you a primer on the incident response lifecycle, the processes involved, how different incidents are categorised and more. We’ll also explain how incident.io can help with automated workflows, easy adoption, and integrations including slack-native incident response that can make your next incident response smooth.
What is incident management?
Behind any good incident is an incident management process. But to optimize for the latter, you need to have a good understanding of the former. Getting a grip on what an incident is (and isn’t) is the first step in bringing people into your company incident response process.
Internally, we like to define an incident as:
Anything that takes you away from planned work with a degree of urgency.
And while this exact definition can vary from organization to organization, the general sentiment remains the same: an occurrence that negatively affects either internal or worse, external functionalities.
Example: a monthly newsletter that only gets sent out on the last Friday of each month is being sent repeatedly throughout the day. This would likely qualify as an incident. Company ending? Not so much. Annoying to customers? You bet. Either way it’s best to address it and figure out what the root cause was.
But how severe is this example incident exactly?
Within incidents, there can be varying severity levels. This can mean setting thresholds so that only the most severe events are called incidents.
However, there is value in smaller, less consequential incidents and there's significant value to be obtained by lowering your threshold for an incident. Smaller incidents are a great way to learn about the failure cases of systems and provide an opportunity for teams to practice response to larger issues.
Whichever categorization you use for individual incident severities, the fact remains the same: incident management absolutely should not be overlooked. Without it, major incidents have the potential to end your business for good, while smaller incidents compound over time and escalate into large issues.
Why is it important to have an incident management process?
Whether you have a 10 person seed-stage company or a 500+ employee post-IPO enterprise, process means everything. This is especially important with incident management. With a dedicated process (and incident response team) in place, you can ensure that:
- Incidents get declared consistently. If people aren’t sure, they’ll often err on the side of not declaring one, and response suffers.
- Everyone’s talking the same language, so they can collaborate efficiently across functions
Without a dedicated process and responders, you can bet on chaotic responses to even the most simple incidents.
What does the incident management process typically look like?
Put simply, the incident management process is a sequence of steps to respond to any unplanned events and outages which disrupt the usual running of your service.
At incident.io, we consider the incident lifecycle to start when an issue is detected and an alert triggered. This lifecyle runs until the moment an incident is closed, meaning normal service is resumed, and a post-mortem process has taken place to identify the root causes of your incident.
This differs slightly from the ITIL model (a best practice framework for ITSM), which differentiates incident management (resuming normal service operation) from problem management (running root cause analysis on incidents to reduce recurrence of future incidents). We think these processes come hand-in-hand so our model brings them together as part of one incident lifecycle.
Remember: this exact process can vary from company to company but the gist remains the same.
Here’s what the actual process looks like for us at incident.io:
- Incident triage and alerting: the point at which an issue is identified. This could be through monitoring tools, a customer complaint or a bug picked up by a member of the IT team. Once an issue is identified, someone will be alerted using an alerting system, such as PagerDuty or Opsgenie.
- Declaring an incident: if the issue meets the organization criteria, an incident will be declared by the incident response team (this could be a dedicated service desk or SRE team, or through an on-call rota within individual product teams). This process is sometimes referred to as “incident logging”.
- Incident response: at this stage, the team starts to diagnose the problem. You’ll need to understand what the issue is and what’s causing it, so you can begin to mitigate and seek resolution. This stage involves multiple actions, including:
- Categorization: ensuring that your incident is clearly categorized by the type of incident and severity, so the team can prioritize effectively against other issues. This helps make sure that major incidents are addressed first.
- Escalation: don’t suffer alone! Sometimes you won’t be the right person to solve the problem, or you might just need back up. Escalating at the right time is important to resolving the incident effectively. Make sure the right people are brought in at the right time.
- Communication: a rapid incident response fails if you don’t communicate successfully with stakeholders. Keeping internal stakeholders and customers in the loop with real-time updates is important to your response.
- Incident closure: once an incident resolution is reached, you need to close the incident. Don’t leave it hanging! A closed incident means that the immediate impact has been mitigated and any further follow-ups will be scheduled as part of ordinary work amongst your teams.
- Post-incident review: after closing an incident, there are important steps that need to be taken before you can finally take your foot off the gas. Teams should complete an incident report, including a post-mortem and incident timeline, ensure that any follow-up actions are completed and run a de-brief. A thorough post-incident process can help you to root cause your incidents, so you can reduce recurring incidents and ultimately decrease outages in your organization.
Who should be involved in the incident management process?
Many organizations view incidents as a solely engineering concern, traditionally the domain of SRE, DevOps and IT operations teams. Our experience is the polar opposite. Incidents often start in product or engineering, but they usually require people from around the organization to form a temporary team to collaborate, communicate and solve a problem. For example, if there is a data breach, your incident response will need to involve multiple team members such as security, legal, customer support.
Building an incident response process that is accessible to the wider organization will help you make sure you have the right people on hand, improving cross-team collaboration and ultimately helping to reduce response time.
What makes our approach to incident management different?
At incident.io, we know how consequential incidents can be for growing businesses. We also realize that the processes surrounding managing incidents can be time-consuming, redundant, and hard to navigate.
That’s why we created a tool that’s primarily focused on automating a whole host of manual processes. We also integrate with tools you already use, such as Slack and Pagerduty, to create an efficient process end-to-end. Here’s what you can count on by adopting incident.io
Automated workflows
Your most valuable asset as a growing business is time. That’s what why created incident.io with automation in mind. Following incident management best practices, you can set up automated workflows through code-free, pre-built incident templates. This allows all designated members of your org to create incidents even if they aren't engineers. A win-win for everyone involved.
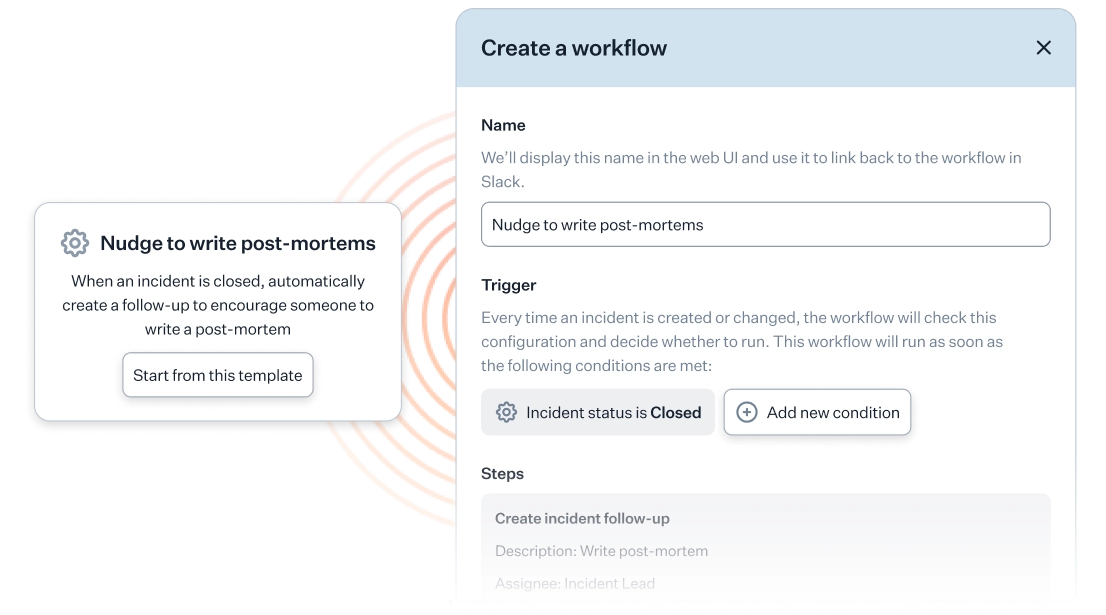
SaaS integrations
To make adoption smooth, we integrate with dozens of tools that you’re already using such as Slack, Asana, Pagerduty, and more. Through these integrations, you can be confident that your incident management doesn’t live in a silo.

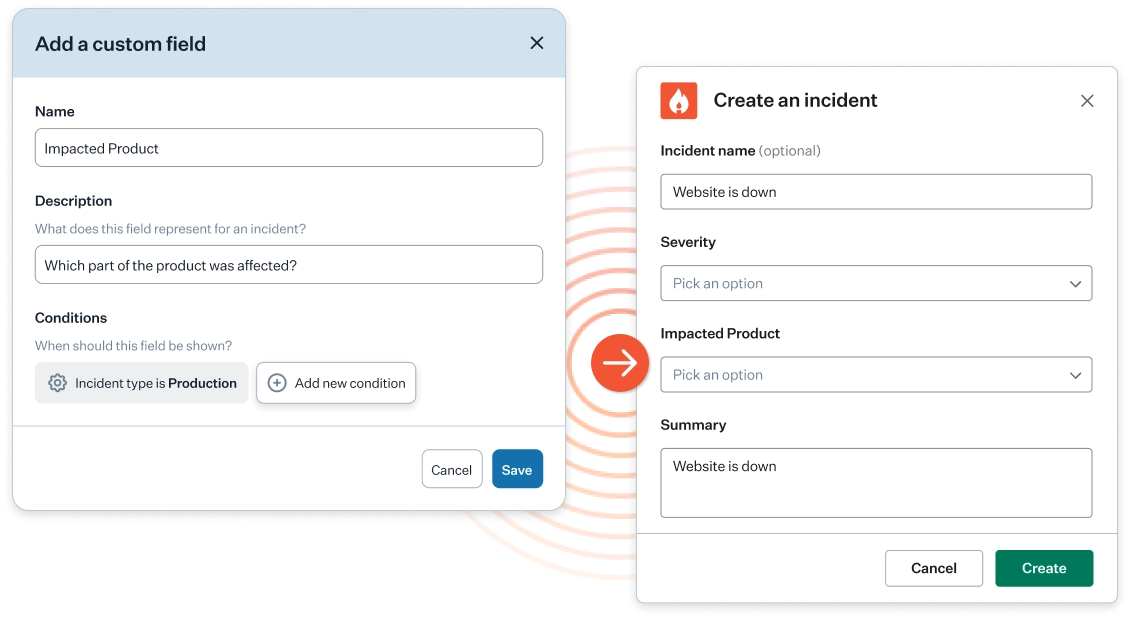
Robust controls
All companies will have their own approach to incident management. That’s why our tool allows you to create your own custom controls and fields. This includes roles, severities, privacy settings and more.
Ready to learn more? Book a demo
Incident management and response is a necessary tool for any company’s tech stack. Ready to experience why companies such as Ramp, Loom, Vanta, and others have decided to use incident.io? Sign up for our demo today.
In today's fast-paced world, having an integrated system is crucial for achieving a smooth workflow. By unifying different processes, businesses can ensure an effective and streamlined operation.
A unified approach not only saves time but also enhances productivity.
Unified Systems FAQs

Katie Hewitt
Business Operations
See related articles

Don't add a read replica until you've read this
Our learnings from implementing a product-wide read replica migrations, including some useful patterns for routing queries to replica and primary
 Johanna Larsson
Johanna LarssonJuly 21, 2026

We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete HamiltonMarch 17, 2026

Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherNovember 14, 2025
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


