ITIL, ITSM and incident management. What are they and how do they fit together?
October 18, 2022 — 10 min read

You’ve probably heard the terms ITIL and ITSM, but the distinction between the two can be a little unclear. Throw incident management into the mix, and the whole thing can feel pretty confusing. This article aims to explain what they are, the differences between the three, and importantly how they fit together.
First, let’s establish what each of the terms actually mean.
So what is ITSM?
ITSM stands for IT Service Management. It’s basically an umbrella term for all the activities an IT team does to manage and improve the end-to-end delivery of its IT services to customers in order to meet business objectives. That includes planning, designing, building, implementing, deployment, improvement and support.
Cool. How is that different to ITIL? I hear you ask…
ITIL (which stands for IT Infrastructure Library) is a widely accepted set of best practices to deliver ITSM. Call it a playbook, framework or set of guidelines, whichever you prefer - but in a nutshell it tells you how to implement ITSM activities to the highest possible standard.
There are lots of component parts to the ITIL certification (side note, there's also an ITSM certification as well.). We’re focussing on incident management, so we won’t go into every detail in this article. However, it is contextually useful to be familiar with ITIL’s “service value system” framework which demonstrates how all the components and activities of an organization can come together to create value.
The service value system, or SVS, is made up five elements:
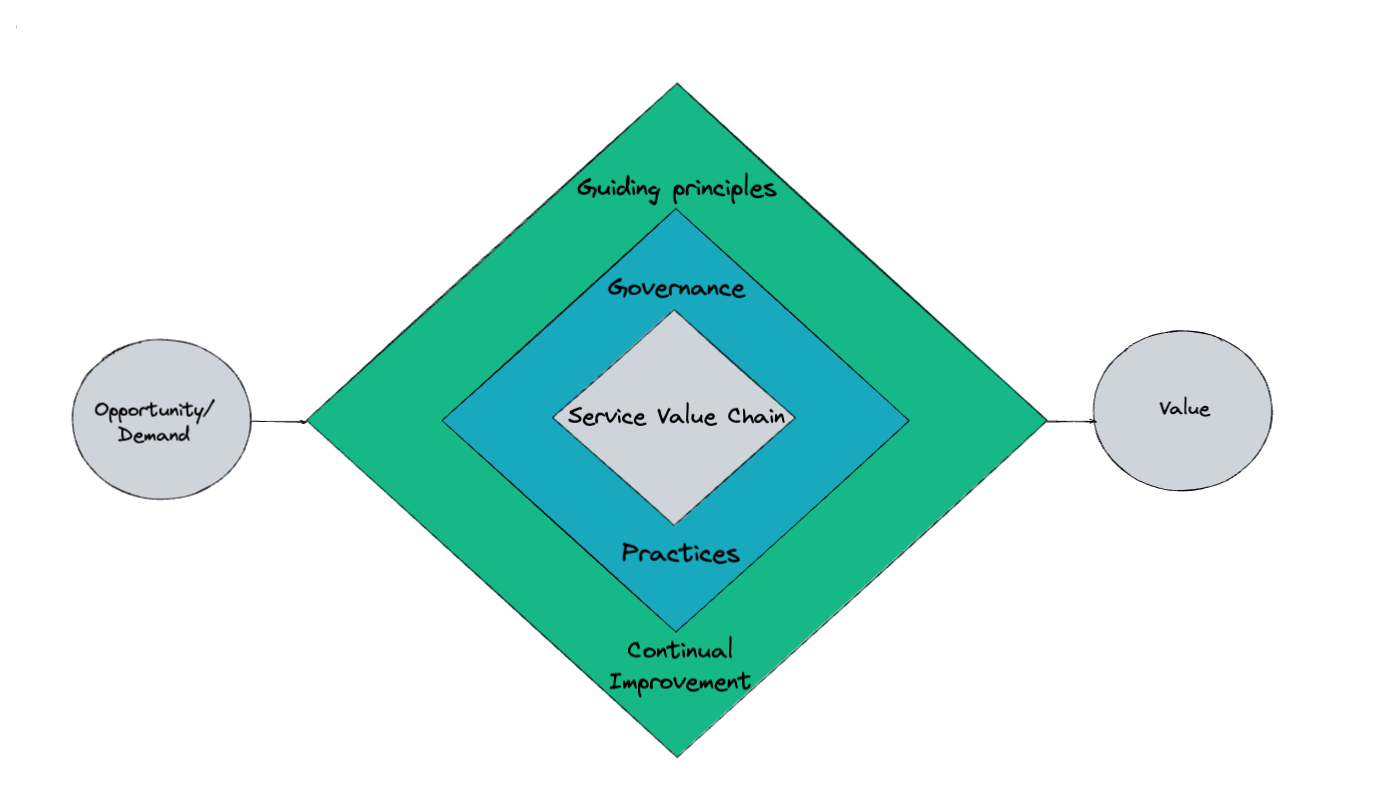
| Element | ITIL definition | Simplified |
|---|---|---|
| The service value chain | A set of interconnected activities that an organisation performs in order to deliver a valuable product or service to its consumers and to facilitate value realisation. | How things come together to deliver value. |
| Practices | Sets of organisation resources designed for performing work or accomplishing an objective. | Practical activities and tools you can use to deliver value |
| Governance | The means by which an organisation is directed and controlled. | How activities in the organisation are overseen, evaluated and directed |
| Guiding principles | Recommendations that can guide an organisation in all circumstances, regardless of changes in goals, strategies, types of work or management structures. | Foundational ways of working |
| Continual improvement | A recurring organisation activity performed at all levels to ensure that an organisation’s performance is always aligned to changing stakeholder expectations. | Does what is says on the tin, always be looking for ways to improve your service to deliver more value, more effectively. |
The part of the system we particularly care about for the purposes of this article are the “practices”, of which there are 34, including “Incident management”…
And incident management practice is defined as…?
💼 The process of logging, recording and resolving unplanned interruptions that disrupt normal delivery of a service.
The goal here is to reach incident resolution as quickly as possible so you can resume normal service operation and minimise any negative impact on your business.
What is the ITIL incident management process?
Lots of organizations use ITIL to inform how they run their incident management process. According to ITIL:
Incidents need to be logged, prioritised, and resolved within agreed timescales. They might be escalated to a support team for resolution, depending on the product or service affected and how quickly the resolution is required. Incident management needs to include quality, timely updates to the affected user(s) which requires a high level of collaboration between teams.
Confession: okay, the heading of this section is a little misleading because, unlike previous versions of ITIL, ITIL 4 doesn’t define a prescriptive incident management process. The good news is it’s a little more flexible than that, recognising that different organizations will require different approaches. It is also more customer-centric than earlier “ITILs”. It pays more attention to user satisfaction and the human side of incidents, like culture and communications. It does, however, provide some core principles for incident management practice activities, including:
- Designing an incident management practice which reacts differently to different incident types, depending on the impact. Our take: We agree! There’s no one size fits all approach to incidents. Responses are likely to need some variation based on (amongst other things) the team or product impacted, and the severity of the incident. These factors will influence lots of parts of the response, including the people who need to be involved in the response (e.g. customer support staff, legal, security), what external communications are required, and which Service Level Agreements (SLA’s) need to be met. The need to flex your approach according to incident categorization is likely to become increasingly relevant as organizations grow and become more complex.
- Prioritising incidents, agreeing classifications and timescales to response with customers up front to ensure those with the highest impact are resolved first. Our take: Having clearly defined incident severities (or “classifications”) is important to any good incident response process. Ideally, we’d recommend having one set of severity levels for your whole organization, so everyone can understand the urgency of an issue. It’s useful to provide clear, concise guidance to your teams on how to triangulate and categorize the severity of an incident. As a rule of thumb, we’d say 3-5 severity levels (described in plain English, e.g. High, Medium, Low) is the best way to go. Having clarity on these definitions helps your team prioritize major incidents and outages, so you can minimise the worst impact of incidents on your business.
- Using an incident management tool for logging and managing incidents. Our take: In our experience, relying on written documentation to follow during an incident is challenging and comes with a number of flaws. The documentation rapidly becomes out of date (particularly in fast moving products, where things are constantly evolving) but rarely do people remember to update it. It’s understandable. Incidents tend not to be top of mind… until they are. Having specific tooling available to help guide you through incidents can help bring consistency, improve visibility and help you to reach incident resolution more effectively whilst giving confidence to your team. You can do this either through buying a ready made tool, using open source or building yourself from scratch - we’ve written some of the pros and cons of these approaches here.
Incident management vs. Problem management
One final curveball! It’s worth also being aware of “Problem management” which is another of ITIL’s 34 management practices. Although closely related, it differs from ITIL’s “Incident management” because it refers to finding the root cause of one or more incidents.
The purpose of problem management practice is to reduce the likelihood and impact of incidents by identifying actual and potential causes of incidents and managing workarounds and known errors.
This is the stage after an incident is resolved and usual operations have been restored, where teams can dig deeper into the underlying causes and seek to fix them to avoid future recurrence of incidents and deliver service improvement.
Recommended activities for problem management include:
- Trend analysis of data including incident records
- Detection of recurring issues
- Problem analysis prioritisation and management based on risk
- Documenting work arounds and known errors
- Identifying potential permanent solutions
How can we help?
incident.io is here to help you meet the best practice standards for an incident management process as set out in ITIL. We empower teams to manage the end-to-end incident lifecycle with confidence. Our product is designed to be used across business functions, so an incident can be quickly declared (by anyone, not just those with specialist knowledge!). Our best practice nudges and process automation to help your team through the most stressful times so you can rapidly fix and learn from incidents, build more resilient products and achieve your business objectives.
Some of the key features we provide to help you easily meet ITIL best practice standards include:
- Response foundations Our product guides you through the basics of incident response, from declaring an incident, assigning incident management roles and actions, and setting severities and statuses, through to closing the incident and generating a postmortem. We provide you with the foundations you need to consistently and accurately log your incidents and respond to them effectively so you can rapidly return to normal service delivery.
- Incident types We enable you to encode different response steps for different types of incident, so that your response can be tailored to the issue at hand. By automating these processes, your team is always guided through the most appropriate actions which will help resolve the incident the in best possible way. You can also apply “Policies” to your incident types, helping you make sure that SLA’s for different types of incident are met.
- Escalation An effective incident management process requires the right people in the room at the right time. With incident.io you can escalate to the right person directly through using our integrations with the most popular escalation systems (including PagerDuty and Opsgenie). Use our workflows to set up automated escalation based on the criteria that are relevant to your business and the incident type.
- Communications Quality, timely updates are critical to incident management. No matter how quick your fix, your response fails if you don’t clearly communicate to customers and stakeholders. incident.io encodes best practices into your communication tools, allowing you to keep internal parties updated via Slack and external parties updated via integrations with shortcuts to tools such as Statuspage (and more).
📌 An added bonus: We believe that Incident Management and Problem Management should work hand in hand. With incident.io, all your incident activities are captured in a dashboard, where you’ll find incident insights to help you identify and analyse recurring pain points. This means you can quickly create an incident report and understand patterns in your incidents, helping you to prioritize areas to focus on for more permanent solutions.
Our customers have found that using incident.io has helped them to improve incident logging and prioritization, improve communication with stakeholders, and ultimately reduce downtime so they can restore normal service operation faster. If you’re looking for help to deliver your ITIL incident management, check out our Practical Guide to Incident Management or install us today!

Katie Hewitt
Business Operations
See related articles

What is ITSM? Understanding the world of service management
ITSM can help businesses improve efficiency, reduce costs, and improve service quality. If you're curious to know more about ITSM, check out this guide.
 Luis Gonzalez
Luis GonzalezJanuary 3, 2023

What is ITSM certification?
In this article, we break down the various ITSM certification options for IT professionals looking to level up their skills and be more attractive options for employers.
Luis GonzalezJanuary 4, 2023
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


