Incident management tools for new on-call engineers: Onboarding & training
January 19, 2026 — 18 min read
Updated January 19, 2026
TL;DR: Traditional on-call onboarding takes several weeks of shadowing because junior engineers juggle multiple tools while trying to remember complex runbooks. Tool-enabled onboarding can cut this significantly by providing Slack-native guardrails that surface context automatically. Instead of memorizing procedures under stress, new engineers learn by doing with automated timelines, embedded service catalogs, and AI assistance. Teams using this approach reduce MTTR by up to 80% while building confident on-call rotations faster.
Your junior engineer's first production page shouldn't feel like trial by fire. Yet most teams force new hires to juggle PagerDuty alerts, Datadog metrics, and scattered runbooks while production burns. By the time they find the right Confluence page and figure out who owns the payment service, 15 minutes have evaporated and customers are complaining on social media.
This pattern repeats because traditional on-call onboarding takes weeks at minimum, with full proficiency often requiring several months. The bottleneck isn't technical skill. Your tools force engineers to memorize processes, hunt for context, and coordinate across five applications during high-stress incidents. Better documentation won't fix this. You need tools that provide guardrails, not more reading material.
Why traditional on-call shadowing fails (and burns out juniors)
Most teams follow a standard playbook: three weeks of shadowing senior engineers, reading outdated runbooks, and hoping muscle memory kicks in before the first solo page. Research confirms this approach produces suboptimal results because it "presumes many aspects can be taught strictly by doing, rather than by reasoning."
The core problem is passive observation. Junior engineers watch seniors navigate incidents but don't internalize the decision tree. When their turn comes, they freeze because watching someone fix a database failover is completely different from executing it yourself at 3 AM while half-asleep.
Your team faces measurable cognitive overload during incidents. Engineers simultaneously:
- Hunt for documentation scattered across Confluence, Notion, or Google Docs where runbooks become outdated and impossible to find under pressure
- Identify service owners without a centralized directory
- Coordinate response by manually creating channels and assembling context
- Switch between tools constantly, where a single context switch consumes 20% of cognitive capacity and it takes 23 minutes to fully regain focus
This "coordination tax" of context-switching costs teams 10-15 minutes per incident before troubleshooting starts. For junior engineers unfamiliar with the stack, that overhead doubles.
"Incident provides a great user experience when it comes to incident management... In a moment when efforts need to be fully focused on actually handling whatever is happening, Incident releases quite a lot of burden off the team's shoulders." - Verified User on G2
Your new engineers need a grace period of 4-6 weeks handling easier tasks before taking primary on-call, creating bottlenecks and burning out your senior engineers who remain the single point of failure.
The shift to tool-enabled onboarding: Guardrails vs. memorization
Stop trying to force engineers to memorize 47-step processes. You need tools that guide them through the process step-by-step in the interface they already use.
Tool-enabled onboarding replaces memorization with active guardrails. Instead of expecting junior engineers to remember "create incident channel, assign severity, page on-call, update status page," the tool prompts each step in sequence. The interface enforces the process, so cognitive load drops from "what do I do next?" to "follow the prompts."
| Aspect | Manual Onboarding | Tool-Enabled Onboarding |
|---|---|---|
| Time to Ready | 2-3 weeks | 1 week |
| Learning Method | Passive shadowing | Active participation with guardrails |
| Context Source | Memorized tribal knowledge | Auto-surfaced in Slack |
| Documentation | Manual reconstruction | Auto-captured timeline |
| Confidence Level | High anxiety | Supported by tool prompts |
| Senior Engineer Burden | Constant shadowing required | Only needed for escalations |
Think of it this way: PagerDuty is the smoke detector that alerts you to problems. Modern Slack-native platforms act as the fire marshal guiding you to the exit with lit pathways and clear instructions.
"I appreciate how incident.io consolidates workflows that were spread across multiple tools into one centralized hub within Slack, which is really helpful because everyone's already there." - Alex N on G2
The architectural difference matters. Most tools were built as web applications that added Slack integrations later. Truly Slack-native platforms handle the entire incident lifecycle inside chat, no browser tabs required. For junior engineers, this eliminates the panic of "which tool do I open now?"
Essential features for safe, accelerated on-call training
The specific capabilities that accelerate learning are Slack-native workflows that reduce cognitive load, service catalogs that surface context automatically, and automated timelines that eliminate documentation fear. Here's how each feature transforms training.
Slack-native workflows to reduce cognitive load
When incidents happen in Slack channels using slash commands, your new engineers focus on solving problems instead of navigating UIs. The workflow becomes conversational: /inc declare creates a channel, /inc assign @engineer delegates tasks, /inc severity high escalates priority.
Netflix specifically wanted UX "that an engineer across Netflix could pick it up, could run with it and didn't need explicit training... even if it's 3AM, it's the first time and it would just feel natural". They achieved this because the tool prompts users through each step without requiring browser navigation.
You eliminate measurable cognitive load. Instead of junior engineers juggling seven browser tabs (PagerDuty, Datadog, Jira, Confluence, Google Docs, Statuspage, Zoom), they work in one interface. This matters because interruptions as short as five seconds triple error rates in complex cognitive work.
See how Slack-native incident management eliminates context switching by keeping all coordination, communication, and commands in a single place. Learn more about improvements to on-call workflows that reduce friction for new engineers.
Service catalogs that surface context automatically
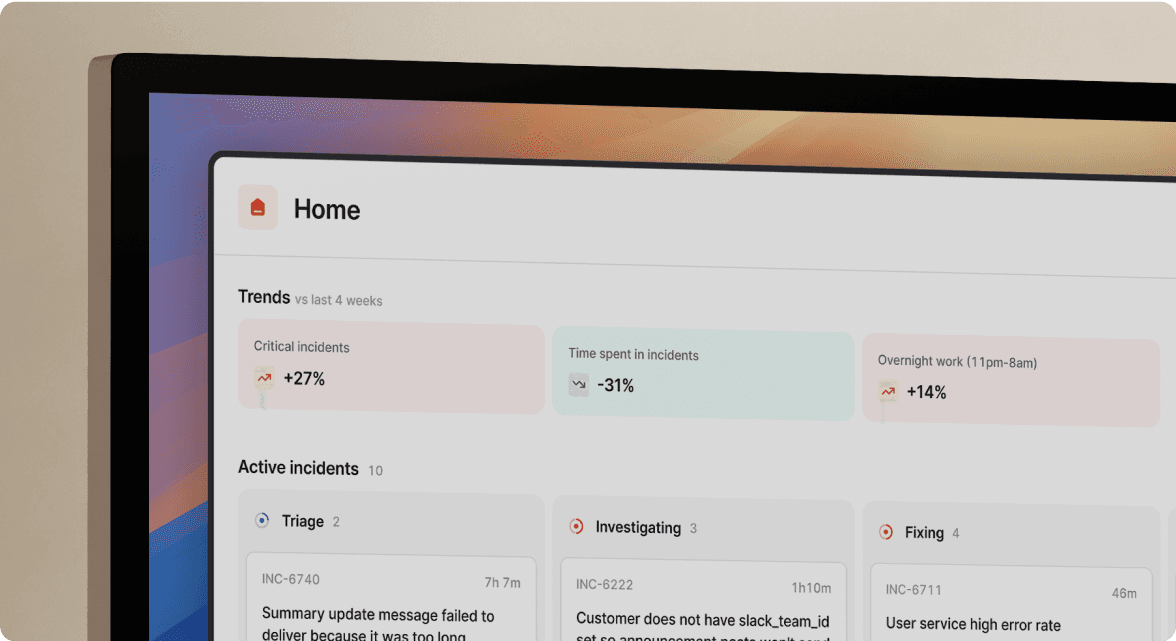
Junior engineers don't know your architecture map yet. They shouldn't need to memorize which team owns the payment service or where the API gateway runbook lives. Service catalogs solve the "who owns this?" problem by automatically surfacing ownership, dependencies, and documentation links directly in incident channels.
When an alert fires for API latency, the platform creates a dedicated Slack channel pre-populated with the triggering alert, full context from your Service Catalog (owners, recent deployments). Your junior engineer sees:
- Service ownership: Who to page for the checkout service
- Dependencies: The PostgreSQL cluster and Redis cache connections
- Recent changes: Last three deployments that might correlate
- Runbook links: Copy-paste commands for common fixes
This embedded context eliminates the tribal knowledge trap. The Catalog "connects your services to their owners, documentation, and dependencies" so context is pushed to engineers rather than pulled from wikis.
"My favourite thing about the product is how it lets you start somewhere simple, with a focus on helping you run incident response through Slack." - Chris S on G2
For new engineers, this is transformative. Instead of pinging five people asking "who owns payments?" while production burns, the answer appears automatically in the incident channel within seconds.
Automated timelines for stress-free post-mortems
Junior engineers fear messing up the post-mortem more than they fear the incident itself. The anxiety of "did I capture everything?" compounds the stress of "am I fixing this correctly?"
Automated timeline capture eliminates this fear. Modern platforms capture every Slack message in incident channels, every slash command, every role assignment, and every call transcript. When the incident resolves, the timeline is already complete. No reconstruction from memory three days later.
You save substantial time. Manual post-mortem writing typically requires 60-90 minutes of scrolling through Slack threads, Zoom recordings, and memory to piece together what happened. AI-powered platforms generate post-mortems automatically from captured timeline data, reducing completion time to 15 minutes of refinement.
For training purposes, this shifts junior engineers from "please take perfect notes" to "focus on fixing the problem while the tool handles documentation." They learn incident response without the administrative burden that causes paralysis.
"incident.io as a fantastic solution for incident management!... it's incredibly easy to get started with since all ICM tasks can be performed directly through Slack, so there's no need for responders to spend time learning a new tool." - Daniel L. on G2
See how Scribe automatically joins incident calls to transcribe key decisions without manual note-taking.
90-day success plan: From new hire to primary on-call
Accelerate onboarding with this structured progression that replaces passive shadowing with active participation supported by tool guardrails.
Days 1-30: Foundation through simulation
Start with practice before production. Run "Wheel of Misfortune" training exercises where new engineers role-play recent incidents to practice debugging without customer impact. Modern platforms support this through sandboxed test incidents that feel identical to real emergencies.
Week 1 activities:
- Practice
/inc declare,/inc assign,/inc severitycommands in test channels - Review your 10 most critical services, their owners, and dependencies
- Run a simulated database failover with senior backup
Week 2-4 activities:
- Join 2-3 real incidents as observer, watching command sequences
- Update status pages, assign follow-up tickets, verify fixes in staging
- Read post-mortems from past incidents affecting services they'll own
By day 30, junior engineers should confidently navigate the interface and understand service relationships. Learn how to set up effective on-call schedules that protect new engineers during ramp-up.
Days 31-60: Active participation with backup
Shift from observer to active participant. The "co-pilot" approach lets junior engineers drive incident response with a senior engineer ready to intervene if needed.
Co-pilot phase responsibilities:
- Primary communicator: Junior engineer types status updates, assigns roles, coordinates response
- Decision maker: Proposes fixes and rollback strategies with senior approval
- Post-mortem author: Drafts the post-mortem using auto-generated timeline as foundation
During this phase, at least two on-call shifts where the new engineer is primary backed by another engineer give them real responsibility with safety nets.
"Without incident.io our incident response culture would be caustic, and our process would be chaos. It empowers anybody to raise an incident and helps us quickly coordinate any response across technical, operational and support teams." - Matt B on G2.
Days 61-90: Independent operation and mastery
By month three, junior engineers should take primary on-call independently. The tool continues providing guardrails, but they no longer need human backup for routine incidents.
Mastery indicators:
- Handles SEV2/SEV3 incidents solo from alert to post-mortem
- Escalates appropriately when incidents exceed their scope
- Contributes to runbook improvements based on experience
- Mentors the next cohort of junior engineers joining rotation
Track on-call readiness using platform analytics that show incident volume per engineer, MTTR trends, and escalation patterns.
Measuring onboarding success: Metrics that matter
Prove ROI to leadership with quantifiable metrics that demonstrate faster ramp-up and improved incident response.
| Metric | Traditional Onboarding | Tool-Enabled Onboarding | How to Measure |
|---|---|---|---|
| Time to On-Call Readiness | 2-3 weeks | 1 week with guardrails | Days from hire to first solo incident |
| First Incident MTTR | 2-3x senior engineer time | Within 25% of senior time | Compare resolution times by experience |
| Documentation Completion | 60% delayed >3 days | 95% within 24 hours | Track post-mortem publishing lag |
| Confidence Score | Lower self-reported | Higher with tool support | Survey new engineers after 30 days |
Key metrics to track quarterly:
- Mean Time to Resolution (MTTR): Strong correlation between MTTR and customer satisfaction makes this the primary success metric. Teams using tool-enabled onboarding reduce MTTR by up to 80%, with Favor achieving 37% reduction.
- First Contact Resolution (FCR): Measures the percentage of incidents solved during initial contact without escalation. Higher FCR indicates junior engineers can handle more incident types independently.
- On-Call Volunteer Rate: When on-call becomes less terrifying through tool support, voluntary participation increases as engineers feel confident rather than anxious.
- Incident Volume by Severity: Buffer saw a 70% reduction in critical incidents by improving early detection through lower-friction incident declaration.
"incident.io provides a one stop shop for all the orcestrations involved when managing an incident... hugely improving our communication capabilities and response times." - Kay C. on G2
Export quarterly reports showing these trends to demonstrate the business value of improved onboarding processes.
How tool-enabled onboarding builds lasting competence
The pattern across successful teams: treat your incident management platform as training infrastructure, not just a response tool. Specific architectural choices determine whether tools accelerate or impede learning.
Why Slack-native architecture matters for training:
- Familiar interface reduces learning overhead. Your new engineers already work in Slack daily. When incident management happens in the same interface, you eliminate tool-learning friction. Netflix specifically wanted UX where "an engineer across Netflix could pick it up... and didn't need explicit training".
- Test mode enables safe practice. Run simulated incidents that feel identical to production emergencies. Junior engineers practice the exact workflow they'll use during real incidents, building muscle memory without customer impact.
- Automated timeline capture eliminates documentation anxiety. When the platform automatically records every action, decision, and outcome, junior engineers focus on problem-solving instead of note-taking. This shifts their cognitive load from administrative tasks to technical judgment.
- Service Catalog integration provides just-in-time learning. Instead of memorizing your entire architecture upfront, engineers see ownership and dependencies surface automatically when they need them. They learn your system's structure through repeated exposure during real incidents.
"The customization of incident.io is fantastic. It allows us to refine our process as we learn by adding custom fields, severity types or workflows to tailor the tool to our exact needs." - Nathael A on G2
incident.io provides these guardrails as core architecture. The Slack-native design means your team manages incidents where they already work, eliminating context-switching that slows learning. AI SRE assistance acts like a senior engineer suggesting root causes based on past incidents, accelerating pattern recognition for new engineers.
Try incident.io free to run a simulated incident with your team. Run a test page at 3 PM on Tuesday, not 3 AM on Sunday, and see how Slack-native workflows feel for new engineers. Or schedule a demo to see the 90-day onboarding framework in action with real customer examples.
Key terms
Runbook: Step-by-step documentation for handling specific incident types. Effective runbooks include copy-paste commands and clear decision trees.
Service Catalog: Directory of services with ownership, dependencies, and documentation links. Modern platforms surface this context automatically during incidents.
MTTR (Mean Time to Resolution): Average time from incident detection to resolution. Primary metric for incident management effectiveness.
Shadow Rotation: Training approach where new engineers observe experienced responders during live incidents before taking primary on-call responsibility.
Game Day / Wheel of Misfortune: Simulated incident exercises that let teams practice response procedures without production impact or customer risk.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

