8-step framework to cut MTTR for engineering teams
December 11, 2025 — 24 min read
Updated 11 December, 2025
TL;DR: Most engineering teams waste 15+ minutes per incident on coordination overhead assembling people, finding context, and switching between tools before they even start troubleshooting. This "coordination tax" accounts for up to 25% of your total MTTR. By automating detection, assembly, and documentation while keeping everything in Slack, teams of 20-500 engineers can reduce MTTR by up to 80% in 90 days. This playbook covers the 8 tactical steps to eliminate coordination waste: automated alerting, instant team assembly, AI investigation, chat-first workflows, and measurement frameworks that prove improvement.
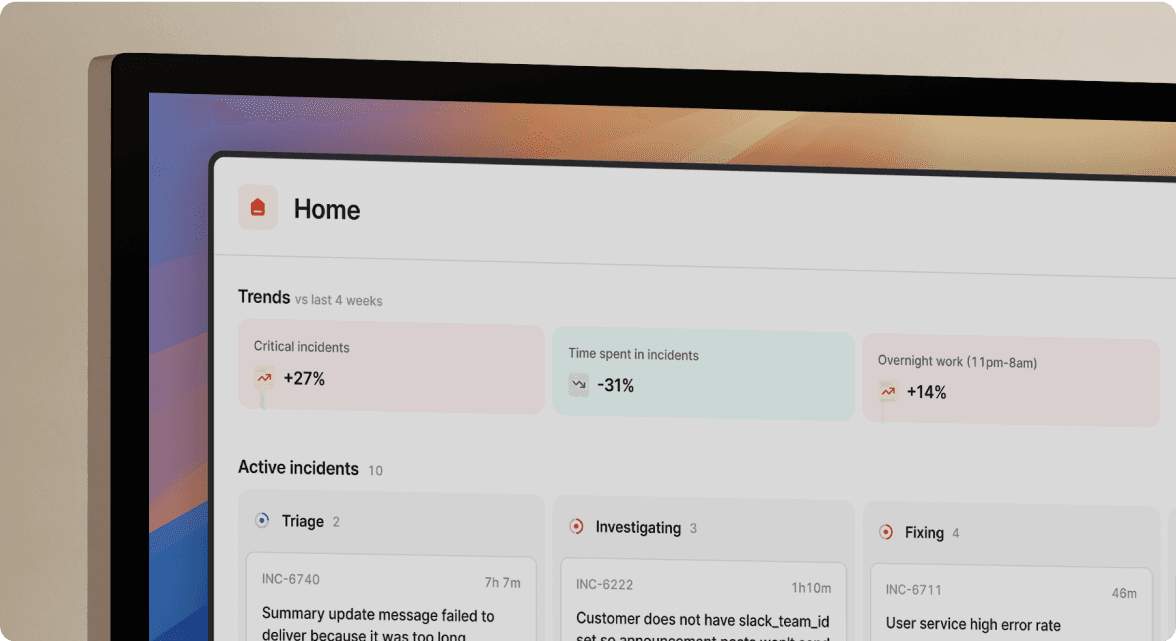
Coordination is killing your MTTR
Your team spends more time coordinating incidents than fixing them. That is not hyperbole.
When a critical alert fires, the clock starts. But here is what happens before troubleshooting begins: Someone manually creates a Slack channel. They search for who is on-call. They ping three different people to find the right service owner. They hunt for the runbook link. They post the Datadog dashboard URL. Twelve minutes gone before diagnosis begins.
This coordination overhead what we call the coordination tax is the gap between elite and medium performers. Research on incident maturity shows elite teams resolve incidents in under one hour while medium performers take one day to one week. The difference is not technical skill. Elite teams automate the logistics of response so engineers focus on problems, not process.
Our analysis of customer data shows coordination overhead can consume up to 25% of your total MTTR. For a 50-engineer team handling 15 incidents per month at 45 minutes each, you burn 168 engineering hours monthly on coordination alone. At a loaded cost of $150 per hour, that is $25,200 in monthly waste.
The good news? Coordination is the easiest part to fix. You cannot automate diagnosis, but you can automate assembly. You cannot automate code fixes, but you can automate context gathering. This playbook shows you how.
Breaking down the MTTR bottleneck
Before you can reduce MTTR, you need to understand where the time goes. Mean Time to Resolution breaks into five distinct phases:
1. Time-to-Detect (TTD): How long between when the issue starts and when your monitoring fires an alert.
2. Time-to-Acknowledge (TTA): How long between when the alert fires and when the on-call responder acknowledges it.
3. Time-to-Assemble (TTM): The coordination phase. Creating channels, finding experts, gathering context. Most teams lose 10-20 minutes here.
4. Time-to-Diagnose: Investigation time. Reading logs, correlating metrics, checking recent deployments.
5. Time-to-Resolve (TTR): Implementing the fix. Rolling back deployments, restarting services, or applying patches.
The 8-step framework targets automated improvements across all five phases, with the biggest gains in assembly and diagnosis.
The 8-step framework to cut MTTR by up to 80%
Step 1: Automate Detection and Routing
Fast detection requires high-signal, low-noise alerts that route to the right team instantly. Most organizations fail here because they broadcast alerts to entire departments, creating alert fatigue that slows acknowledgment.
Build intelligent routing rules:
- Integrate monitoring at the source: Connect Datadog, Prometheus, Grafana, Sentry, or New Relic directly to your incident management platform. This allows alerts to automatically trigger incidents without manual declaration.
- Route by service ownership: Configure rules that send alerts to the specific team that owns the affected service, not to a generic engineering channel. Use tags like
service:paymentsorteam:platformin your monitoring tool. - Set severity automatically: Use alert metadata to classify severity. A complete outage on a customer-facing API should auto-classify as critical. High latency on an internal tool might be low severity.
- Deduplicate and aggregate: Group related alerts within a 5-minute window to prevent notification floods. Five alerts for the same database connection issue should create one incident, not five.
Evidence this works: Teams that implement automated alert routing see alert volume drop by 90%+, eliminating noise while preserving critical signals.
Step 2: Eliminate "who's on-call?" Chaos
Every minute spent hunting for the right person is a minute your customers are impacted. Automated escalation paths ensure the right engineer receives the page within seconds, not minutes.
Structure your on-call system:
- Define clear schedules: Build primary, secondary, and tertiary on-call tiers with automatic escalation. If the primary does not acknowledge within 5 minutes, escalate to secondary.
- Use role-based paging: Beyond on-call engineers, define roles like Incident Commander, Communications Lead, or Database Expert. Configure workflows to automatically invite these roles when specific services are affected.
- Integrate with existing tools: If you already use PagerDuty or Opsgenie for paging, integrate it with your coordination layer. This lets you keep existing alerting while centralizing response workflows in Slack.
- Test escalation paths monthly: Run fire drills where you trigger test alerts during business hours to verify escalation policies work as expected.
"incident.io strikes just the right balance between not getting in the way while still providing structure, process and data gathering to incident management." - Verified user review of incident.io
Learn how to design smarter on-call schedules for faster, calmer incident response.
Step 3: The 2-minute Assembly
This step eliminates the single biggest coordination bottleneck. Instead of spending 10-15 minutes manually creating channels and inviting people, automate it to under 30 seconds.
Here is the automated assembly workflow:
- Instant channel creation: When an alert fires or someone runs
/inc declarein Slack, the system creates a dedicated incident channel with a consistent naming convention like#inc-2025-12-01-api-latency-sev1. - Automatic role invitations: Based on pre-configured rules, the platform invites the on-call engineer for the affected service, the designated Incident Commander, and any other required stakeholders.
- Pre-populated context: The channel opens with critical information already present, incident summary, severity level, status, links to runbooks, a video conference link for immediate collaboration.
- Service-aware routing: By connecting to your service catalog, the system knows that
payments-apiincidents need the Platform team and the Payments team, inviting both automatically.
The result: Assembly time drops from 15 minutes to under 2 minutes.
"incident.io makes incidents normal. Instead of a fire alarm you can build best practice into a process that everyone can understand intuitively and execute." - Verified user review of incident.io
Watch a full platform walkthrough on YouTube to see automated assembly in action.
Step 4: Context at Your Fingertips
When responders join an incident channel, they should not need to ask "where is the runbook?" or "what changed recently?" A Service Catalog surfaces this context automatically.
Build your Service Catalog:
- Document service metadata: For each service, record the service owner, on-call schedule, Slack channel, source code repository, dashboards, and runbooks. This can be maintained via UI, YAML config-as-code, or API.
- Link recent changes: Integrate with GitHub, GitLab, or your CI/CD tool to show recent deployments. When an incident occurs, responders see that
payments-apiwas deployed 14 minutes ago, correlating the timeline. - Auto-surface in incidents: When an incident is declared for a specific service, the catalog automatically posts relevant links in the incident channel. No one needs to remember where the runbook lives.
- Keep it current: Assign service owners to review their catalog entries quarterly. Out-of-date documentation is worse than no documentation.
The Service Catalog addresses a common challenge cited by SRE leaders: critical information is scattered across wikis, Confluence pages, and tribal knowledge. Consolidating it into a structured catalog that surfaces automatically saves 5-10 minutes of context-gathering per incident.
Learn how to build effective runbooks that your team will actually use.
Step 5: AI-assisted Investigation
AI SRE can automate up to 80% of incident response through four key capabilities that dramatically reduce diagnosis time.
Leverage AI in the incident workflow:
- Root cause suggestions: AI analyzes the incident and compares it to past incidents, suggesting patterns like "90% of similar incidents were caused by database connection pool exhaustion" or "this correlates with deployment #4872."
- Automated fix pull requests: For common issues like configuration drift or dependency version mismatches, AI can open pull requests directly in Slack for human review and approval.
- Log and metric synthesis: Instead of manually grepping logs, ask the AI "show me error rates for payments-api in the last hour" and receive a summarized analysis.
- Call transcription: AI note-taking tools transcribe incident calls in real-time, capturing key decisions and action items without requiring a dedicated scribe.
The impact is measurable. incident.io's AI SRE automates up to 80% of incident response, allowing responders to focus on the 20% that requires human judgment.
"The onboarding experience was outstanding and the integration with our existing tools was seamless and fast less than 20 days to rollout. The user experience is polished and intuitive." - Verified user review of incident.io
Discover how automated incident response is transforming modern SRE practices.
Step 6: Chat-first Communication
Keeping the entire incident lifecycle in Slack eliminates context-switching, the hidden tax of toggling between PagerDuty, Jira, Confluence, and status page tools.
Implement chat-first workflows:
- Slash commands for everything: Use commands like
/inc update,/inc assign @role,/inc severity criticalto manage incidents without leaving Slack. This reduces the cognitive load during high-stress moments. - Automated status page updates: When you post an update in the incident channel, push it to your status page with a single click. This ensures stakeholders get timely communication without manual effort.
- Stakeholder notifications: Configure workflows to post key updates, severity changes, resolution notifications to broader channels like
#engineering-updates, keeping everyone informed without manual announcements. - Timeline auto-capture: Every message, command, and role change is automatically recorded, building a precise timeline that becomes the foundation of your post-mortem.
"Huge fan of the usability of the Slack commands and how it's helped us improve our incident management workflows. The AI features really reduce the friction of incident management." - Verified user review of incident.io
Step 7: Auto-drafted Post-mortems
Post-mortems are where teams learn and improve, but they rarely happen consistently because writing them from memory takes 90 minutes. Automation solves this.
Automate post-incident learning:
- Timeline as foundation: Since every action during the incident was captured automatically, the post-mortem starts with a complete, interactive timeline of events. You do not need to recall who did what when.
- AI-drafted narrative: When you run
/inc resolve, AI generates a draft post-mortem including summary, timeline, participants, and placeholders for analysis and action items. This is 80% complete in 10 minutes. - One-click export: Publish the finalized post-mortem to Confluence, Notion, or Google Docs with a single command. Follow-up tasks auto-create in Jira or Linear.
- Track completion rates: Use your Insights dashboard to measure post-mortem completion. Teams using automated drafts see completion rates jump from 40% to 85%+.
Customer proof: Organizations that formalize their incident process with automated documentation see dramatic improvements. One customer reduced their MTTR from 3 hours to 30 minutes, an 83% improvement. Another cut MTTR by 50% using the same approach to automated post-mortems.
Use this simple incident post-mortem template to structure your retrospectives effectively.
Step 8: The Feedback Loop
You cannot improve what you do not measure. An Insights dashboard provides the analytics to identify bottlenecks, track improvements, and prove ROI to leadership.
Build your measurement framework:
- Track core metrics: Monitor overall MTTR, MTTR by severity, Time-to-Acknowledge, Time-to-Resolve, incident volume by service, and responder workload.
- Identify bottlenecks: Use the MTTR phase breakdown chart to see where delays occur. If Time-to-Assemble is consistently high, focus on automation. If Time-to-Diagnose is long for a specific service, improve runbooks.
- Calculate MTTR reduction: Establish your baseline MTTR over 30 days. After implementing changes, measure your current MTTR. Use this formula:
% Reduction = ((Baseline MTTR - Current MTTR) / Baseline MTTR) × 100. - Review monthly: Schedule a monthly incident review with your team to analyze trends, celebrate wins, and identify the next improvement area.
"The velocity of development and integrations is second to none. Having the ability to manage an incident through raising - triage - resolution - post-mortem all from Slack is wonderful." - Verified user review of incident.io
For deeper guidance, read about 8 actionable tips to improve your incident management processes.
Your 30/60/90-day Implementation Roadmap
Breaking implementation into three phases ensures you demonstrate value quickly while building toward full adoption.
Days 0-30: Pilot and Quick Wins
Objective: Prove the concept with a small team and establish your MTTR baseline.
Activities:
- Connect your primary monitoring tool (Datadog, Prometheus, etc.) and alerting system.
- Configure on-call schedules for 1-2 pilot teams (20-30 engineers).
- Define basic incident roles: Incident Commander, Communications Lead.
- Train the pilot team on declaring incidents and using core commands.
- Document your baseline MTTR by analyzing the last 30 days of incidents.
Success metrics:
- Pilot teams use the platform for 100% of new incidents.
- Time-to-Assemble drops below 2 minutes consistently.
- Post-incident surveys show 80%+ satisfaction with the new process.
Days 31-60: Organization Rollout and Catalog Population
Objective: Expand to all engineering teams and build out your Service Catalog.
Activities:
- Onboard all remaining engineering teams (50-500 engineers total).
- Populate the Service Catalog with your 20 most critical services, including runbooks and recent deploy information.
- Enable automated status page updates.
- Roll out AI-assisted post-mortem drafts and train teams on refinement workflow.
- Review incident routing best practices to optimize escalation paths.
Success metrics:
- 80%+ of engineering teams actively using the platform.
- Post-mortem completion rate increases by 50% (from ~40% to 60%+).
- Initial 10-15% reduction in MTTR is visible in Insights dashboard.
Days 61-90: Tuning, Automation, and Continuous Improvement
Objective: Hit your MTTR reduction target and establish continuous improvement processes.
Activities:
- Use Insights to identify remaining bottlenecks and tune workflows.
- Build advanced custom workflows (auto-assigning roles by severity, auto-escalating based on time thresholds).
- Complete Service Catalog population for all production services.
- Conduct a 90-day review with leadership, presenting MTTR reduction data and ROI calculation.
- Watch this incident.io On-call end-to-end demo for advanced features.
Success metrics:
- Target achieved: Up to 80% reduction in average MTTR sustained for 30+ days.
- Post-mortem completion rate reaches 85%+.
- Teams proactively use Insights to optimize their own services.
Intercom successfully migrated in a matter of weeks using a similar phased approach. Their engineering team noted that "engineers immediately preferred incident.io, and adoption across the broader company quickly followed."
Manual vs. Automated Workflow Comparison
| Phase | Manual Process (Before) | Automated Process (After) | Time Saved |
|---|---|---|---|
| Detection & Routing | Alert fires, broadcasts to entire engineering team. Someone manually triages. | Alert auto-creates incident, routes to service owner, sets severity based on metadata. | 3-5 min |
| On-Call & Assembly | Responder searches Slack for on-call schedule, manually creates channel, invites people one by one. | Automated channel creation, on-call paged instantly, roles invited automatically with context pre-loaded. | 10-15 min |
| Investigation | Responder searches for runbooks in Confluence, checks recent deploys in GitHub, manually correlates alerts. | Service Catalog surfaces runbooks and recent deploys automatically. AI suggests likely root cause. | 5-10 min |
| Communication | Responder manually updates status page, posts to stakeholder channels, sends summary emails. | One-click status page updates from Slack. Auto-notifications to stakeholder channels. | 4-6 min |
| Post-Mortem | Responder spends 90 minutes reconstructing timeline from memory and Slack scroll-back 3 days later. | AI drafts 80% complete post-mortem from captured timeline in 10 minutes. Responder refines in 10 more minutes. | 70-80 min |
| Total Coordination Tax | 25-40 minutes per incident | 5-10 minutes per incident | 20-30 min |
ROI calculation for a 100-engineer team on the Pro plan:
- 15 incidents per month at 25 minutes saved per incident = 375 minutes (6.25 hours) saved monthly
- At 5 responders per incident average = 31.25 engineering hours reclaimed per month
- At $150 loaded hourly cost = $4,687.50 monthly savings or $56,250 annually
- Pro plan cost for 100 users at $45/user/month = $4,500 monthly ($54,000 annually)
- Net annual value: $2,250 (breaks even in Month 1, then delivers pure time savings for proactive work)
This calculation does not include the business impact of faster resolution (reduced customer churn, fewer SLA breaches, improved NPS).
How Incident.io Accelerates This Framework
- Coordination happens in Slack, not in a separate web app. The entire incident lifecycle from
/inc declareto resolution runs in Slack where your team already works, eliminating context-switching that costs 3-5 minutes per incident. - AI SRE automates up to 80% of response. From root cause identification to fix PR generation, AI handles routine analysis so engineers focus on edge cases. Watch how AI becomes the first responder.
- The Service Catalog is built in, not bolted on. The catalog lives in the platform and auto-surfaces runbooks and recent deployments during incidents, saving 5-10 minutes of "where is the documentation?" time.
- Post-mortems write themselves. Timeline data automatically generates 80% complete post-mortems in 10 minutes, eliminating the manual reconstruction that causes many incidents to never get documented.
- Support responds in hours, not days. incident.io's team fixes issues via shared Slack channels, typically within hours.
"The customer support has been nothing but amazing. Feedback is immediately heard and reacted to, and bugs were fixed in a matter of days max." - Verified user review of incident.io
Common Objections and How to Address Them
"We already built a custom Slack bot." Your bot probably works great for 20 people, but how does it handle on-call scheduling for 8 teams? Does it auto-draft post-mortems? Does it provide analytics on MTTR trends? Custom tools break at scale and no one wants to maintain them. Learn why purpose-built incident management matters as you grow.
"PagerDuty does all this." PagerDuty excels at alerting and on-call scheduling, but incident coordination happens in their web UI, which requires context-switching. Many teams integrate PagerDuty for alerting with Slack-native platforms for coordination, combining the best of both: robust alerting with zero-friction response.
"Our MTTR is already fine." If your median MTTR is under 30 minutes for critical incidents and you have 85%+ post-mortem completion, you are in the elite tier. But most teams discover their measured MTTR does not include the 10-15 minutes spent assembling people because that time is not tracked. Run a baseline analysis to see where you truly stand.
"This will add overhead during incidents." The opposite is true. Adding structure reduces cognitive load. When a P0 fires at 3 AM, you want clear workflows, not chaos.
"We like how we can manage our incidents in one place. The way it organises all the information being fed into an incident makes it easy to follow for everyone in and out of engineering." - Verified user review of incident.io
The coordination tax is not inevitable. Elite engineering teams have proven that MTTR reductions of up to 80% are achievable when you automate the logistics of response and keep teams in their natural workflow. Start with automated assembly, add AI investigation, close the loop with measurement, and you will see improvement within 90 days.
Visit incident.io to learn how teams of 20-500 engineers cut MTTR by up to 80% or book a demo to watch the workflow in action.
Key Terminology
Mean Time to Resolution (MTTR): The average time from when an incident is detected until it is fully resolved. Elite performers achieve MTTR under 1 hour, while medium performers take 1 day to 1 week.
Coordination tax: The time and resources spent on manual administrative tasks during incidents (finding on-call, creating channels, updating tools) rather than technical troubleshooting. This can account for 25% of total MTTR.
Time-to-Assemble: The phase between alert acknowledgment and when the full incident response team is assembled in a communication channel with relevant context. Automation can reduce this from 15 minutes to under 2 minutes.
Service Catalog: A centralized repository of metadata about your services, including owners, on-call schedules, runbooks, dashboards, and dependencies. It auto-surfaces this context during incidents to eliminate manual searching.
Slack-native: An architecture where the entire incident workflow happens via Slack commands and channels, rather than requiring users to switch to a web application. This reduces context-switching and cognitive load during high-stress incidents.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

