Going beyond MTTx and measuring “good” incident management
March 25, 2025 — 5 min read

Going beyond MTTx and measuring “good” incident management
We’ve chatted with hundreds of engineering teams, and a pattern keeps popping up: everyone’s tracking MTTX metrics—MTTR, MTTA, MTT-whatever—but when you ask, “Cool, so what are you doing with that?” …you get blank stares.
And honestly, fair enough. Time-based metrics are easy. They’re simple to calculate, they look nice on a dashboard, and they give you something to put in your quarterly update. But when it comes to actually improving your incident response lifecycle? They're mostly noise.
So we tried something different.
we pulled data from over 100,000 real incidents and built a benchmark report that skips the vanity incident reporting metrics and focuses on what good incident response actually looks like. And if you’d rather watch than read, we also broke it all down in a webinar—with commentary, of course.
Let’s get into it.
What’s wrong with MTTX?
We’re not here to cancel MTTR (we’d never). But let’s be honest: it’s a bit of a blunt instrument.
It’s easily skewed by outliers and it tells you nothing about how the incident was handled. You could halve your MTTR and still have a total mess behind the scenes. And it could massively increase when everything has been done entirely right. At best it’s lightly correlated with what’s happening on the ground and at worse it’s actively misleading.
And yet, teams everywhere—from 5-person startups to 5,000-person enterprises—are tracking these numbers. But few are using them to drive actual change.
So we built something better
We asked ourselves: what if we stopped obsessing over how fast incidents end, and started paying attention to how well they’re managed?
That led to our benchmark report: a set of quality-focused, data-backed metrics that reflect what actually happens during incident response. No surveys, no guesswork—just anonymized, real-world data from across the incident.io platform.
We designed these metrics to:
- Reflect the quality of your incident process—not just speed.
- Be grounded in real product data, from hundreds of thousands of incidents.
- Be genuinely actionable—showing you where to focus and what to improve.
- Enable fair comparison, internally across teams or externally with peers.
Following incident management best practices is like an annual checkup for your incident process—with way less awkward small talk.
A few metrics we actually like
Let’s run through a handful of our favorites from the report:
Time to mobilize and time to assign a lead
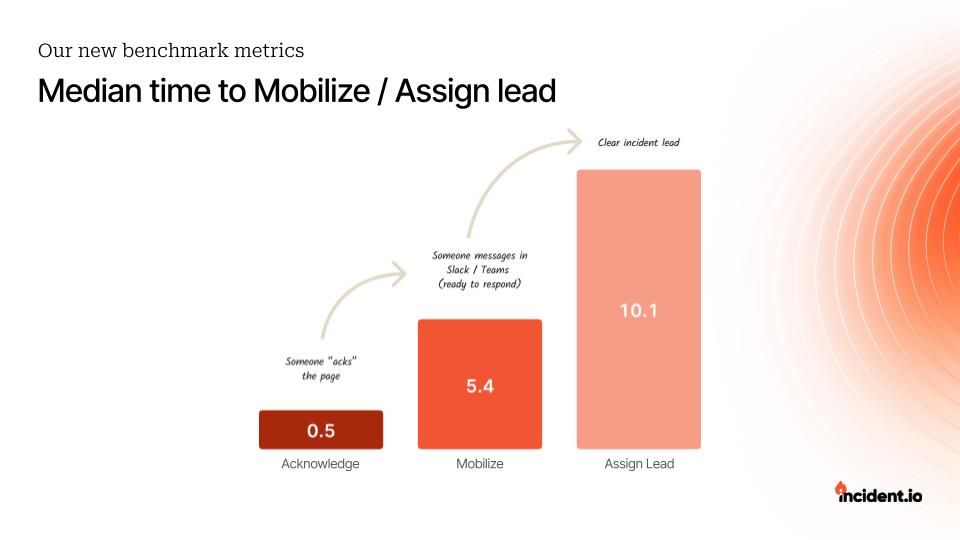
Time to mobilize tracks how long it takes from the first alert firing to someone actively engaging with the incident. Unlike “time to acknowledge” (which usually means someone half-asleep swiped a notification), this gives you a real sense of responsiveness.
Pro tip: it’s slower at night. If that matters for your SLAs, it’s probably time to rethink your on-call setup.
The time to assign a lead metric tracks how long it takes to appoint an incident commander—a crucial step for coordination, communication, and making sure things don’t spiral. A slow handoff here = more chaos.
Frequency of updates
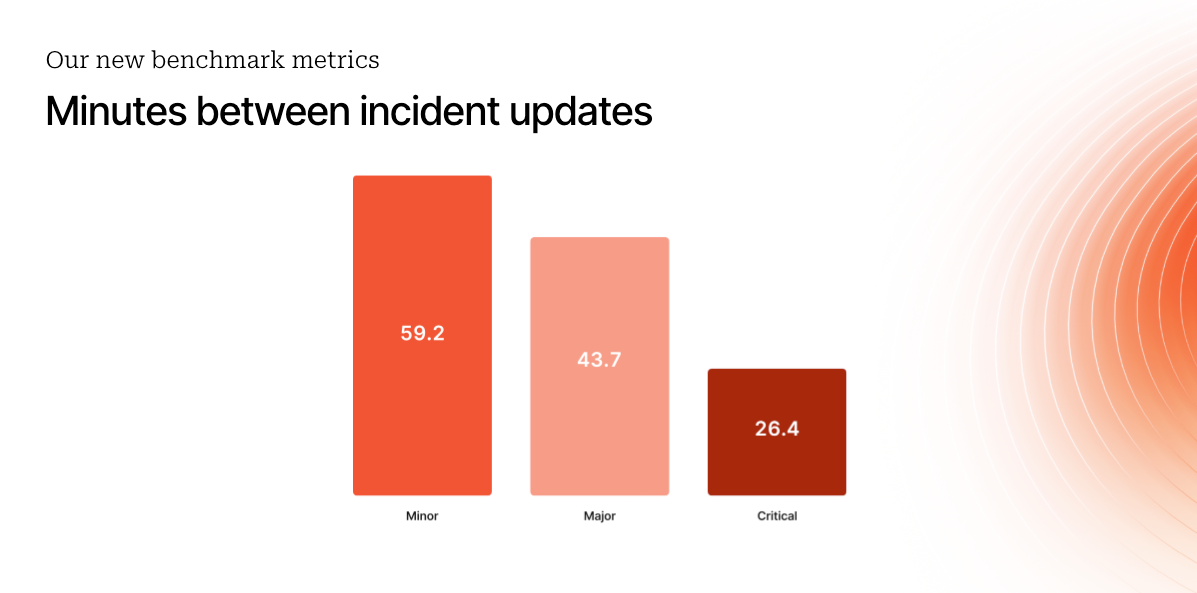
Incidents are scary. Updates make them less so. This metric looks at how often updates are posted throughout the incident lifecycle.
Frequent updates mean better alignment, lower stress, and a more resilient team when things go sideways. And yes, incident response automation helps: a gentle nudge or a pre-filled template can work wonders.
Out-of-hours paging
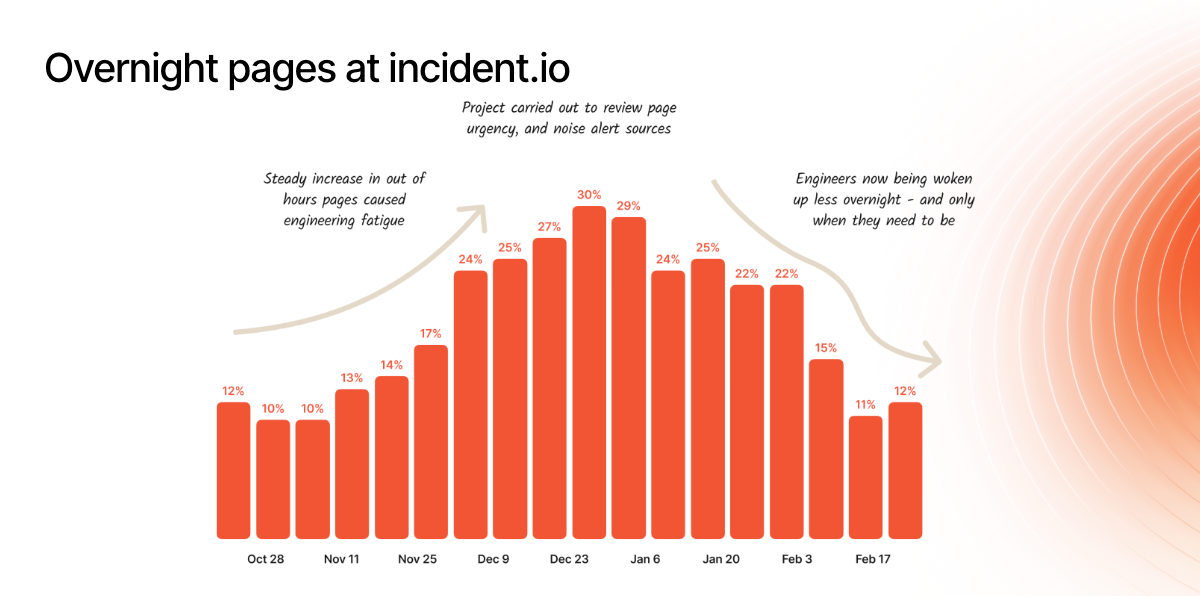
You might not just have an incident problem: you might have an alert fatigue problem.
Tracking how many incidents happen outside of working hours gives you insight into alert quality, load distribution, and whether your team’s getting burned out. We track this religiously at incident.io—and when our December numbers spiked? We fixed it. (The vibes are back to excellent, thanks for asking.)
Metrics don’t have all the answers, but they know where to look
None of these numbers are magic on their own. But together, they paint a picture.
A picture that says: here’s how your team really works under pressure. Here’s what’s working. And here’s where to dig in.
We’re not saying MTTR should disappear forever (it’s got its uses). But if you want to build a high-performing, resilient, and human-friendly incident process, you’ve got to look beyond the stopwatch.
Curious about where your team stands?
Check out the report or drop us a line. We’re always up for a chat—especially if there’s a postmortem-worthy tale involved.

Chris Evans
Co-Founder & Field CTO
I'm one of the co-founders, and Field CTO here at incident.io.
See related articles

Pager fatigue: Making the invisible work visible
We developed The Fatigue Score to make sure our On-call responders’ efforts are visible. Here's how we did it, and how you can too.
 Matilda Hultgren
Matilda HultgrenApril 25, 2025

How we handle sensitive data in BigQuery
We take handling sensitive customer data seriously. This blog explains how we manage PII and confidential data in BigQuery through default masking, automated tagging, and strict access controls.
 Lambert Le Manh
Lambert Le ManhNovember 14, 2024

How we model our data warehouse
Curious about the inner workings of our data warehouse? We’ve shared a lot about our data stack, but this time we’re diving into the design principles behind our warehouse. This blog breaks down how we structure our data, from staging to marts layers, and how we use it all in our BI tool. It’s a quick look into how we keep things flexible, efficient, and built to scale.
 Jack Colsey
Jack ColseyNovember 8, 2024
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


