How we handle sensitive data in BigQuery
November 14, 2024 — 8 min read

As a provider of incident management software, we at incident.io manage sensitive data regarding our customers. This includes Personally Identifiable Information (PII) about their employees, such as emails, first names, and last names, as well as confidential details regarding customer incidents, such as names and summaries.
Consequently, we approach the management of this data with a great deal of care. This blog post will outline our practices for handling sensitive data within our data warehouse, BigQuery.
In the last section of this post, we will delve a bit deeper into the technical implementation for our more technically inclined audience.
Before we dive into the topic, here’s a quick diagram that illustrates our workflow:
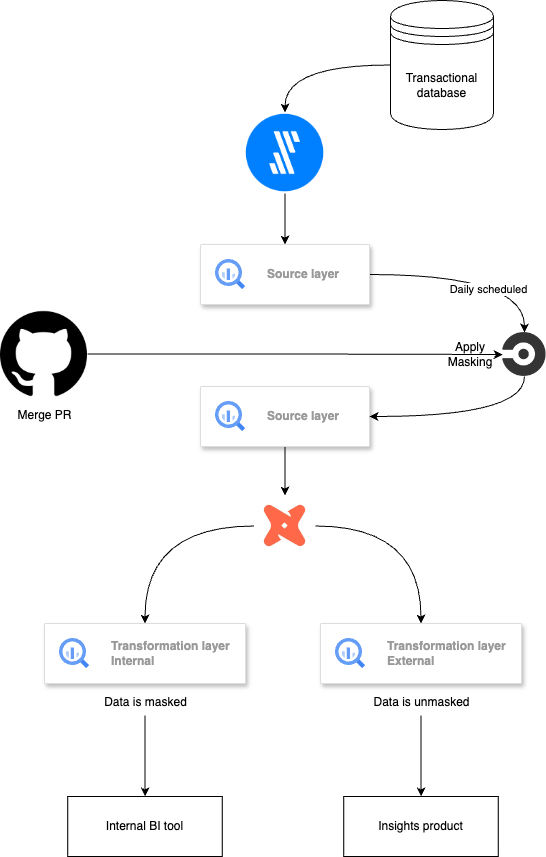
For context, we use Fivetran to replicate our transactional database into BigQuery, dbt for data transformations, and CircleCI to manage all orchestration processes.
How do we detect sensitive data?
Default masking in the source layer
By default, all new columns from our transactional database are marked as sensitive in BigQuery. This means that users without the appropriate IAM permissions will only be able to view the data in a masked format. Here is an example of how incident names and summaries appear when queried without permissions:
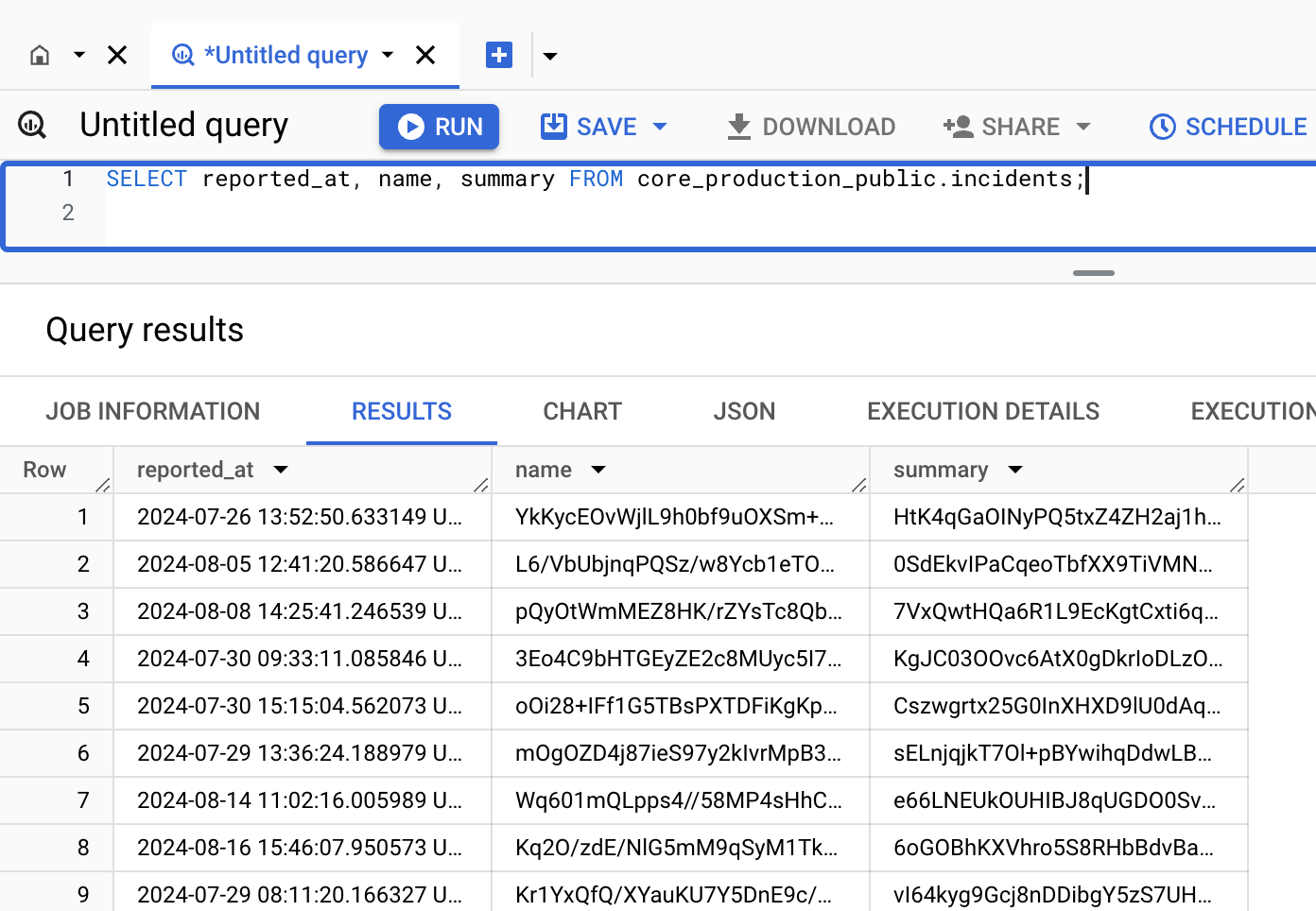
Currently, only our customer-facing dbt service account can view this data in an unmasked format.
This workflow includes several key components:
- First, we established a taxonomy and created policy tags—one for PII and another for confidential information. For more details on column-level access control in BigQuery, refer to their official documentation.
- Second, we have implemented a scheduled daily job in Python (more details on this later) that scans all tables in our transactional database within BigQuery and applies policy tags to any untagged columns. This ensures that any new columns added to the warehouse are masked by default.
- Lastly, any human users within the company can only access columns with an applied policy tag in a masked format, using
SHA256hashing.
Masking in dbt
Most of our columns do not contain sensitive data. As a result, masking them by default leads to a significant number of false positives. To remove policy tagging from a column and make it visible to human users, we have created two YAML files in our data repository that list non-sensitive columns. The process to untag a column is as follows:
- Submit a PR in our data repository to add the column name to the relevant YAML file(s). We maintain one file for Personally Identifiable Information (PII) and another for confidential data; if a column does not fall under either category, it should be added to both files.
- After the PR is merged, our daily workflow, as described in the previous section, is activated. This workflow compares the current state of the YAML files with their most recent previous versions, allowing it to process only the tables affected by the change, thereby optimizing overall processing time.
- The workflow can both apply and remove policy tags as needed.
How is sensitive data handled downstream?
We use dbt for our data transformations and have divided our dbt pipeline into two distinct streams. One of these is customer-facing, meaning that the dbt service account used to refresh this data has full access to sensitive information in a non-masked format. This ensures that our customers can access their data, even if it contains sensitive information.
The other pipeline, which is used for internal analytics (for instance, if a CSM wants to assess the number of incidents for one of their accounts), is managed by a different service account that only has access to sensitive data in a masked format. Consequently, when refreshing dbt models, the masked data is pulled from the source and hardcoded into the downstream tables. This approach allows us to tag a column only once at the source, thereby reducing the likelihood of human errors.
However, this does introduce some limitations, such as the challenge of transforming sensitive data into non-sensitive formats (for instance, extracting the email domain from an email address field). For now, this is a trade-off we are willing to accept. Any other non-customer-facing tools that access our data warehouse will either have access to our source data in a masked format or to the non-customer-facing transformed data, where sensitive information is hardcoded as masked.
How does the workflow work under the hood?
Our policy tag workflow consists of two functions. The first function parses the input YAML file into a more readable format for the second function:
def column_list_to_dict(
column_yml_file_dir: str,
column_yml_file_name: str,
is_slim_run: bool = False,
slim_run_artifacts_location: str = ".",
) -> Dict[str, Dict[str, Dict[str, List[str]]]]:
"""Takes a yml file of columns and returns dictionary
Args:
column_yml_file_dir (str): Dir to yml file.
column_yml_file_name (str): yml file name.
is_slim_run (boolean, optional): If this is a slim run (i.e. deployment). Defaults to false.
slim_run_artifacts_location (str, optional). Dir to previous version of yml file.
Returns:
nested_dict: Nested dictionary of columns
"""
try:
with open(f"{column_yml_file_dir}/{column_yml_file_name}") as yml_file:
column_yaml = yaml.safe_load(yml_file)
except FileNotFoundError:
return nested_dict()
if is_slim_run:
try:
previous_results: Dict[str, Dict[str, Dict[str, List[str]]]] = (
column_list_to_dict(
column_yml_file_dir=slim_run_artifacts_location,
column_yml_file_name=column_yml_file_name,
)
)
except FileNotFoundError:
previous_results = nested_dict()
results: nested_dict = nested_dict(
{
project_name: {
dataset_name: {
table_name: [
column["name"]
for column in table["columns"]
if (
column["name"]
not in previous_results[project_name][dataset_name].get(
table_name, []
)
if is_slim_run
else True
)
]
for table_name, table in dataset["tables"].items()
}
for dataset_name, dataset in project["datasets"].items()
}
for project_name, project in column_yaml["projects"].items()
}
)
return results
The output returned is a nested dictionary that maps each project_id to dataset names, which in turn map to table names, and those table names map to a list of columns. This function exhibits two different behaviors depending on when it is invoked:
- During our daily scheduled job, it returns columns that should be excluded from the policy tag workflow, as they are deemed non-sensitive.
- After a merged PR, it provides a list of tables to iterate through, in contrast to the daily scheduled workflow where all tables are processed. This is achieved by comparing the current version of the file with its most recent previous state. As you may have noticed, this function is recursive; when modifying the YAML file(s), it reads the latest previous state of each file along the current version of the file to ensure that we retain only those tables where at least one new column has been added.
- To obtain the latest previous version of each file, we upload them to Google Cloud Storage (GCS) after every merged PR. During our production run, a Python script is used to retrieve these files.
The second function applies or unapplies the policy tags as needed:
def apply_policy_tag(
project_id: str,
dataset_id: str,
policy_tag: str,
classification: str,
exclude_columns: Dict[str, Dict[str, Dict[str, List[str]]]],
is_slim_run: bool = False,
slim_ci_columns: Dict[str, Dict[str, Dict[str, List[str]]]] = nested_dict(),
) -> List[str]:
"""Apply policy tag to all columns in a dataset unless they are specificed in the exclude_columns paramater
Args:
project_id (str): GCP project id.
dataset_id (str): Bigquery dataset.
policy_tag (str): policy tag id.
classification (str). Either pii or confidential.
exclude_columns (Dict[str, Dict[str, Dict[str, List[str]]]]): Dictionary of columns to exclude from tagging policy.
is_slim_run (boolean, optional): If this is a slim run (i.e. deployment). Defaults to false.
slim_ci_columns(nested_dict, optional): list of columns to remove policy tag from. Default to a nested dict.
Returns:
List[str]: List of columns policy was applied to.
"""
client: bigquery.Client = bigquery.Client(project=project_id)
if is_slim_run:
tables: List[str] = [
table_id
for table_id in slim_ci_columns[project_id][dataset_id].keys()
if slim_ci_columns[project_id][dataset_id][table_id]
]
else:
tables: List[str] = [
tab.table_id for tab in client.list_tables(f"{project_id}.{dataset_id}")
]
policy_tag_object: bigquery.PolicyTagList = bigquery.PolicyTagList([policy_tag])
results: list[str] = []
for tab in tables:
table: bigquery.Table = client.get_table(f"{project_id}.{dataset_id}.{tab}")
new_schema: List[Any] = []
table_results: List[str] = []
num_of_updated_cols: int = 0
for count, column in enumerate(table.schema):
try:
exception_columns: List[str] = exclude_columns[project_id][dataset_id][
table.table_id
]
except KeyError:
exception_columns: List[str] = []
if (
column.name not in exception_columns
and not column.policy_tags
and column.field_type in ["STRING", "BYTES"]
):
new_column: bigquery.SchemaField = bigquery.SchemaField(
name=column.name,
field_type=column.field_type,
mode=column.mode,
description=column.description,
policy_tags=policy_tag_object,
)
new_schema.append(new_column)
logging.warning(
f"tag {policy_tag} applied to {table.full_table_id}.{column.name}"
)
table_results.append(f"{table.full_table_id}.{column.name}")
add_row_to_data_catalogue(
block_id=DATA_CATALOGUE_BLOCK_ID,
dataset=dataset_id,
table=tab,
column=column.name,
classification=classification,
)
delete_row_from_data_catalogue(
block_id=DATA_CATALOGUE_BLOCK_ID,
dataset=dataset_id,
table=tab,
column=column.name,
classification=(
"pii" if classification == "confidential" else "confidential"
),
)
num_of_updated_cols += 1
elif (
column.name in exception_columns
and column.policy_tags == policy_tag_object
):
new_column: bigquery.SchemaField = bigquery.SchemaField(
name=column.name,
field_type=column.field_type,
mode=column.mode,
description=column.description,
policy_tags=bigquery.PolicyTagList(),
)
new_schema.append(new_column)
logging.warning(
f"tag {policy_tag} removed from {table.full_table_id}.{column.name}"
)
delete_row_from_data_catalogue(
block_id=DATA_CATALOGUE_BLOCK_ID,
dataset=dataset_id,
table=tab,
column=column.name,
classification=classification,
)
else:
new_schema.append(column)
if new_schema != table.schema:
table.schema = new_schema
client.update_table(table, ["schema"])
if num_of_updated_cols == count + 1:
table_results = [f"All columns from {table.full_table_id}"]
results += table_results
return resultsFirst, we define the set of tables to iterate through, which is stored in the tables variable. During a daily scheduled run, this consists of all tables within the specified dataset. However, when following a merged PR (i.e., when is_slim_run is true), we utilize the list of tables returned by our first function.
Next, we iterate through all tables (using the BigQuery Python library) and all columns, applying the defined policy tag if the column is not in the exception list returned by our first function or if it is not already tagged.
Additionally, we have included a couple of other tasks to update our Notion sensitive data catalogue (detailed below) and send Slack alerts whenever a new column is tagged.
Notion data catalogue
By leveraging Notion’s API, we automatically update our Notion data catalog with a list of sensitive data.
Here’s what our catalog looks like:
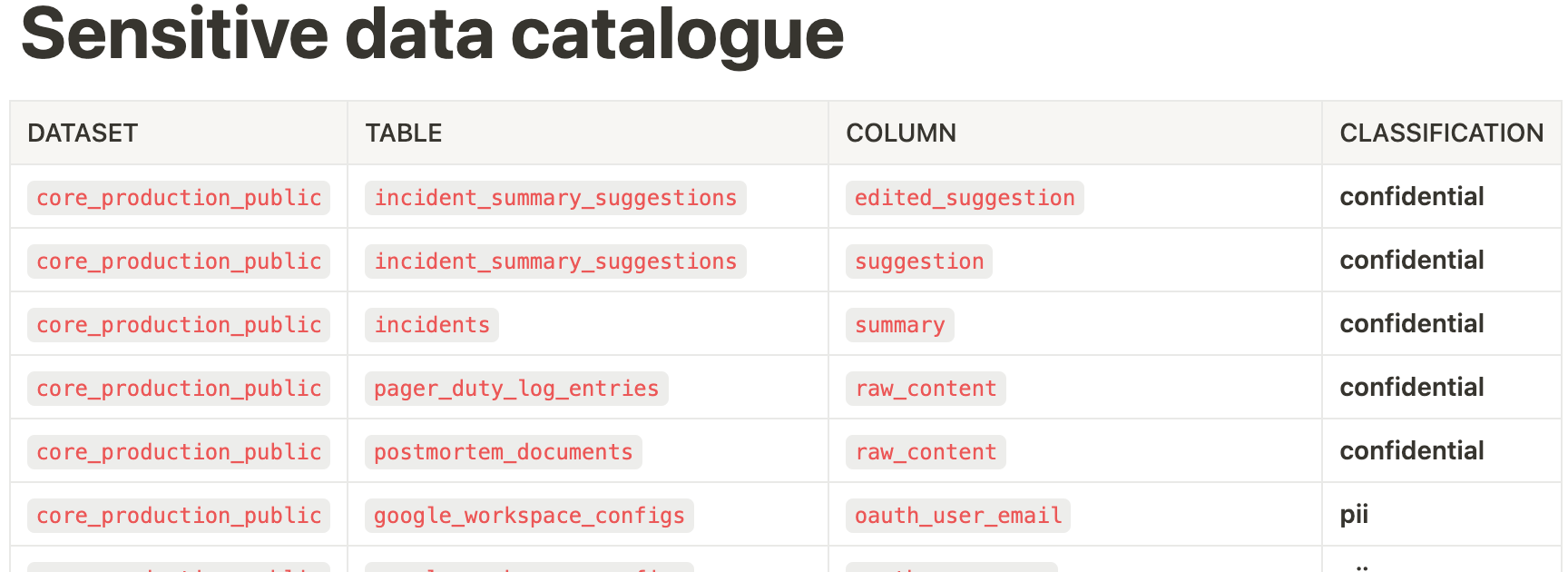
In order to automate it, we have developed two straightforward functions. The first function is used to add a new entry to the data catalog:
def add_row_to_data_catalogue(
block_id: str, dataset: str, table: str, column: str, classification: str
) -> int:
"""Add row to data catalogue
Args:
block_id (str): Data catalogue block id.
dataset (str): Dataset name.
table (str): Table name.
column (str): Column name.
classification (str): Either pii or confidential.
Returns:
int: Api response code.
"""
url = f"https://api.notion.com/v1/blocks/{block_id}/children"
payload = {
"children": [
{
"type": "table_row",
"table_row": {
"cells": [
[
{
"type": "text",
"text": {"content": dataset},
"annotations": {"code": True},
}
],
[
{
"type": "text",
"text": {"content": table},
"annotations": {"code": True},
}
],
[
{
"type": "text",
"text": {"content": column},
"annotations": {"code": True},
}
],
[
{
"type": "text",
"text": {"content": classification},
"annotations": {"bold": True},
}
],
]
},
}
]
}
response = requests.patch(url, headers=HEADERS, json=payload)
return response.status_codeThis function is part of our policy tag workflow, triggered when a tag is applied to a column.
Our second function is designed to delete an entry from our data catalog:
def delete_row_from_data_catalogue(
block_id: str, dataset: str, table: str, column: str, classification: str
) -> int:
"""Delete row from data catalogue
Args:
block_id (str): Data catalogue block id.
dataset (str): Dataset name.
table (str): Table name.
column (str): Column name.
classification (str): Either pii or confidential.
Returns:
int: Api response code.
"""
url = f"https://api.notion.com/v1/blocks/{block_id}/children"
response = requests.get(url, headers=HEADERS)
block_ids: List[str] = [
block["id"] for block in json.loads(response.content).get("results", [])
]
for block_id in block_ids:
url = f"https://api.notion.com/v1/blocks/{block_id}"
cells: List[List[Dict, Any]] = json.loads(
requests.get(url, headers=HEADERS).content
)["table_row"]["cells"]
try:
if [cell[0]["text"]["content"] for cell in cells] == [
dataset,
table,
column,
classification,
]:
response = requests.delete(url, headers=HEADERS)
print(f"deleted block: {block_id}")
return response.status_code
except IndexError:
continueThis function is invoked when the tagging policy is removed from a column.
Conclusion
While our approach to handling sensitive data in BigQuery is strict and may not offer the most flexibility, it prioritizes the security of our customers' data, which is our top priority. In the future, with the implementation of column-level lineage, we could adopt a less restrictive approach in dbt to automatically tag downstream dependencies of sensitive columns. For now, however, we find that not having to worry about tagging our columns—and only needing to submit a pull request to untag them—is sufficiently effective.

Lambert Le Manh
Senior Data Engineer
See related articles

Pager fatigue: Making the invisible work visible
We developed The Fatigue Score to make sure our On-call responders’ efforts are visible. Here's how we did it, and how you can too.
 Matilda Hultgren
Matilda HultgrenApril 25, 2025

Going beyond MTTx and measuring “good” incident management
What does "good" incident management look like? MTTx metrics track speed, but speed alone doesn’t mean success. So, we decided to analyze 100,000+ incident from companies of all sizes to identify a set of new benchmarks for every stage of the incident lifecycle.
 Chris Evans
Chris EvansMarch 25, 2025

How we model our data warehouse
Curious about the inner workings of our data warehouse? We’ve shared a lot about our data stack, but this time we’re diving into the design principles behind our warehouse. This blog breaks down how we structure our data, from staging to marts layers, and how we use it all in our BI tool. It’s a quick look into how we keep things flexible, efficient, and built to scale.
 Jack Colsey
Jack ColseyNovember 8, 2024
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


