Data quality testing
September 4, 2024 — 6 min read

Data quality testing is a subset of data observability. It is the process of evaluating data to ensure it meets the necessary standards of accuracy, consistency, completeness, and reliability before it is used in business operations or analytics. This involves validating data against predefined rules and criteria, such as checking for duplicates, verifying data formats, ensuring data integrity across systems, and confirming that all required fields are populated. Effective data quality testing helps not only fosters trust in the data but also empowers organizations to make confident, data-driven decisions.
In this post, we'll explore the data observability workflow at incident.io, discuss two common challenges we encountered, and explain how we addressed them.
Data observability workflow at incident.io
While there are various tools specifically designed for data observability, at incident.io, we rely on dbt's native testing features to ensure the reliability of our data. Since dbt is our primary tool for data transformations, using it for data observability was a practical choice. This approach allows us to integrate both processes into the same pipeline, streamlining our production and CI workflows. Additionally, the capability to run custom data tests and override default schema tests (more on this later) offers the flexibility and customization we need to meet our specific requirements.
What challenges did we face?
Relationship tests
Overview
One of the most powerful schema tests available is the relationship test. As the name suggests, it verifies whether all column values (typically a foreign key) in a given table have corresponding matches in a specified table's columns (typically a primary key). For instance, we can use a relationship test on a transactions table to ensure that every user ID referenced has a corresponding entry in our user table.
Challenge
However, we frequently encountered "flaky" relationship test failures due to the timing of our ingestion pipeline. Our transformation pipeline often runs while data is still being ingested, causing some tables to have more up-to-date data than others, leading to failed relationship tests.
Returning to our earlier example, the user table might be refreshed before the transaction table during our transformation workflow, while new data is still being inserted into our source tables. This could result in the transaction table containing entries linked to users that haven't yet been added to the user table. Does this indicate an issue with our pipelines? No, it simply means the pipeline ran at an inopportune time.
Solution
How did we address this issue? While there are various approaches (such as applying a watermark on an ingestion timestamp to exclude recent data from the test), we opted for a more pragmatic solution. We agreed that a relationship test should be marked as failed only if the same value is missing from its parent table twice in a row. For instance, if a user ID in our transaction table is still absent from our user table after two consecutive test runs (scheduled hourly), it’s marked as a failure. Here’s an overview of how we implemented this:
- We began by using dbt’s store_failures feature to log missing column values from relationship tests. We modified dbt's should_store_failures macro to store test failures for all tests with severity set to error.
{% macro should_store_failures() %}
{% set config_store_failures = config.get('store_failures') %}
{% if target.name not in ["test", "dev"]
and config_store_failures is none
and config.get("severity") == "error" %}
{% set config_store_failures = true %}
{% endif %}
{% if config_store_failures is none %}
{% set config_store_failures = flags.STORE_FAILURES %}
{% endif %}
{% do return(config_store_failures) %}
{% endmacro %}- Next, we customized dbt’s default relationship test to incorporate our logic:
- We introduced an
is_recurrentfield to track whether the value was missing in the previous test run. To calculate this, we join the current results with the previous stored results (if available) to check if the value was already missing. If it’s the first test run,is_recurrentis set to false for all values.
- We introduced an
{% macro default__test_relationships(relation, column_name, to, field) %}
with child as (
select {{ column_name }} as from_field
{% if execute and should_store_failures() %}
{%- if adapter.get_relation(
database=this.database ,
schema=this.schema,
identifier=this.name) is not none -%}
, if(from_field is not null, true, false) as is_recurrent
{% else %}
, false as is_recurrent
{% endif %}
{% endif %}
from {{ relation }}
{% if execute and should_store_failures() %}
{%- if adapter.get_relation(
database=this.database ,
schema=this.schema,
identifier=this.name) is not none -%}
left join {{ this }} on from_field={{ column_name }}
{% endif %}
{% endif %}
where {{ column_name }} is not null
),
parent as (
select {{ field }} as to_field
from {{ to }}
)
select distinct
from_field
{% if should_store_failures() %}
, is_recurrent
{% endif %}
from child
left join parent
on child.from_field = parent.to_field
where parent.to_field is null
{% endmacro %}- Finally, we modified dbt’s default get_test_sql macro to return only the values where is_recurrent is true for relationship tests:
{% macro default__get_test_sql(main_sql, fail_calc, warn_if, error_if, limit) -%}
select
{{ fail_calc }} as failures,
{{ fail_calc }} {{ warn_if }} as should_warn,
{{ fail_calc }} {{ error_if }} as should_error
from (
{{ main_sql }}
{% if model.test_metadata %}
{% if model.test_metadata.name == "relationships" and should_store_failures() %}
where is_recurrent is true
{% endif %}
{% endif %}
{{ "limit " ~ limit if limit != none }}
) dbt_internal_test
{%- endmacro %}Incident workflow
Overview
As it can be expected, we automatically create an incident for any dbt test failure with a severity error . This ensures that every failures is logged, audited and provides greater clarity and visibility on what was the issue and who is fixing it.
Challenge
However, the entire debugging process wasn’t the most user friendly. Although a link to the dbt run logs was attached to the incident slack channel, the incident lead had to scroll through the logs to understand which test failed and then often run a custom query to understand which rows were failing.
Solution
By utilizing dbt’s store_failures feature, which we discussed earlier, and dbt’s artefacts, we implemented the following steps in our dbt pipeline:
- Flagged failed tests by iterating through the run_results file. Below is a python helper function that accomplishes this:
def parse_run_results(run_results_dir: str) -> List[Dict[str, Any]]:
results = []
for item in listdir(run_results_dir):
if item.startswith("run_results"):
with open(f"{run_results_dir}/{item}") as run_results_file:
run_results: Dict[str, Any] = json.load(run_results_file)
invocation_id: str = run_results["metadata"]["invocation_id"]
file_path: str = f"{run_results_dir}/{item}"
for node in run_results["results"]:
node_result_payload: Dict[str, Any] = {
"invocation_id": invocation_id,
"file_path": file_path,
"unique_id": node["unique_id"],
"status": node["status"],
"timing": node["timing"],
}
results.append(node_result_payload)
return results- Used the manifest file to retrieve the table name that stores the failed results. Below is a python helper function for this:
def parse_manifest(manifest_dir: str) -> List[Dict[str, Any]]:
results = []
with open(f"{manifest_dir}/manifest.json") as manifest_file:
manifest: Dict[str, Any] = json.load(manifest_file)
invocation_id: str = manifest["metadata"]["invocation_id"]
for node, value in manifest["nodes"].items():
node_payload: Dict[str, Any] = {
"invocation_id": invocation_id,
"config": value["config"],
"unique_id": node,
"database_id": f"{value['database']}.{value['schema']}.{value.get('alias', value['name'])}",
"path": value["path"],
}
results.append(node_payload)
return results- Included the table names in the incident.io payload (we use python to generate them), sent via the incident API, to automatically trigger an incident:
failed_tests: List[str] = [
node["unique_id"]
for node in parse_run_results(run_results_dir)
if node["status"] == "fail"
]
database_ids: List[str] = [
node["database_id"]
for node in parse_manifest(manifest_dir)
if node["unique_id"] in failed_tests
]
payload["metadata"]["queries"] = "; ".join(
[f"SELECT * FROM {database_id}" for database_id in database_ids]
)- Finally, we customized the incident alert source to add it as an incident feature, as shown below:
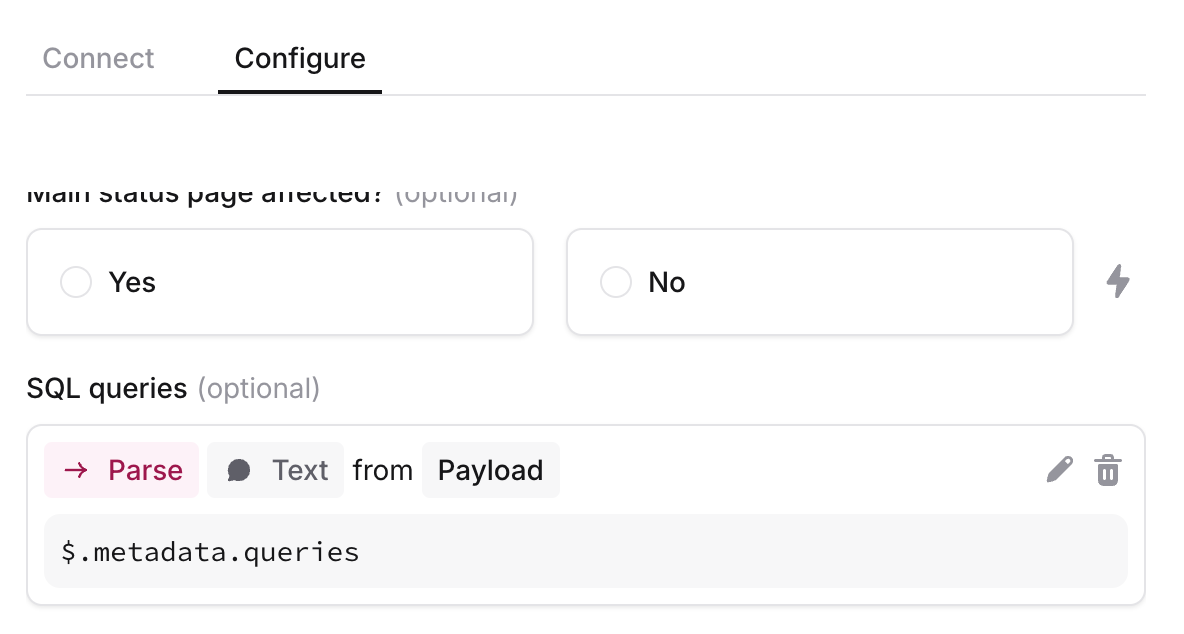
- And voilà:

Conclusion
While there's much more to explore about data observability, we believe the two issues discussed are common across many organizations. Our proposed solutions were tailored to our specific needs, and it's important to note that solutions may vary between organizations depending on their unique requirements and data stacks.

Lambert Le Manh
Senior Data Engineer
See related articles

Pager fatigue: Making the invisible work visible
We developed The Fatigue Score to make sure our On-call responders’ efforts are visible. Here's how we did it, and how you can too.
 Matilda Hultgren
Matilda HultgrenApril 25, 2025

Going beyond MTTx and measuring “good” incident management
What does "good" incident management look like? MTTx metrics track speed, but speed alone doesn’t mean success. So, we decided to analyze 100,000+ incident from companies of all sizes to identify a set of new benchmarks for every stage of the incident lifecycle.
 Chris Evans
Chris EvansMarch 25, 2025

How we handle sensitive data in BigQuery
We take handling sensitive customer data seriously. This blog explains how we manage PII and confidential data in BigQuery through default masking, automated tagging, and strict access controls.
 Lambert Le Manh
Lambert Le ManhNovember 14, 2024
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


