Post-mortem automation: How incident management tools speed up retrospectives
January 30, 2026 — 23 min read
Updated January 30, 2026
TL;DR: Manual post-mortem reconstruction wastes 60-90 minutes per incident as teams search through chat history, monitoring tools, and call recordings trying to piece together what happened. Automated incident management platforms capture timelines in real-time as events unfold, use AI to draft summaries from that data, and sync follow-up actions directly to Jira or Linear. This shifts the work from 90 minutes of reconstruction to 10 minutes of refinement, freeing engineering teams to focus on prevention instead of paperwork. Tools like incident.io reduce post-mortem time by 75-83% while improving accuracy through immutable, timestamped records captured during the incident itself.
You fixed the production outage in 22 minutes. Writing the post-mortem took two hours.
You spent 90 minutes scrolling through 847 Slack messages, three Zoom recordings, and five Datadog dashboards trying to reconstruct exactly when Sarah restarted the pods, who approved the rollback, and which deployment correlation triggered the cascade failure. By the time you finished, you couldn't remember why you'd opened the third tab. The timeline was fuzzy. The action items were generic. The post-mortem shipped four days late because nobody wanted to do the archaeology work.
Manual post-mortems fail repeatedly because they ask engineers to do something unnatural: perfectly remember and document a high-stress event that happened days ago while juggling five tools and fighting production fires. Automation doesn't just save time. It transforms post-mortems from creative writing exercises into data-driven learning sessions by capturing context as incidents unfold, not after memory fades.
Why manual post-mortems are killing your team's velocity
The toil tax compounds with every incident
Many teams aim to complete incident analysis within 36–48 hours, when you include root-cause analysis, remediation, writing the post-mortem, fixing bugs, and following up. Manual timeline reconstruction alone consumes 60-90 minutes of that total. The cognitive cost is higher: context-switching between Slack threads, PagerDuty alerts, Datadog graphs, Jira tickets, and Google Docs fragments your attention precisely when you need deep focus to identify systemic patterns.
"It can become a real nightmare to retroactively parse through 100s of Slack messages, screenshots, Sentry errors, GitHub PRs/commits etc. to get a clear picture of what happened." - Verified user review on G2
If your team handles 15 incidents monthly and each post-mortem consumes 90 minutes of engineering time, that's 22.5 hours per month or 270 hours annually spent on administrative reconstruction. At a blended engineering rate of $150/hour, you're burning $40,500 yearly on work that creates no technical value.
Memory fails under pressure
Human recall degrades rapidly after high-stress events. The exact timestamp when you rolled back the deployment? Forgotten. The specific reason you chose option B over option A during the 3 AM decision? Lost. Which graph showed the correlation between the cache spike and API latency? Buried in a browser tab you closed.
Industry research on blameless post-mortems shows that delays between incident resolution and documentation directly correlate with incomplete or inaccurate reports. Engineers reconstructing timelines three days later rely on imperfect memory, leading to missing context, incorrect timestamps, and overlooked contributing factors that could prevent future incidents.
Low completion rates signal lost learning opportunities
Post-mortem completion rates serve as a numerical proxy for how much teams actually learn from incidents. When the process requires 90 minutes of manual work, incidents go undocumented. Your team resolves 20 incidents but only publishes 12 post-mortems because the administrative burden is too high. Those eight missing retrospectives contain insights about system vulnerabilities, configuration gaps, and process improvements that never get captured or addressed.
The cost isn't just the time spent writing. It's the repeated incidents that could have been prevented if you'd documented the pattern.
What is post-mortem automation?
When we talk about automated post-mortems, we don't mean templates you fill out faster. We mean real-time capture of incident context, decisions, and timelines, synthesized by AI into structured reports that are 80% complete before you start writing.
Post-mortem automation is the active collection and organization of incident data during the event itself. Modern platforms integrate with Slack, monitoring tools, and ticketing systems to automatically record:
- Every action taken (role assignments, escalations, status changes)
- Every decision made (rollback approved, deployment paused)
- Every piece of context shared (Datadog graphs, PagerDuty alerts, GitHub PRs)
- Every conversation thread (Slack messages, Zoom call transcriptions)
The fundamental shift is from reconstruction to recording. Instead of asking "What happened three days ago?" you're reviewing a complete, timestamped record that was built automatically as events unfolded. Watch incident.io's approach in this hands-on introduction to automated incident workflows.
Core components of automated incident retrospectives
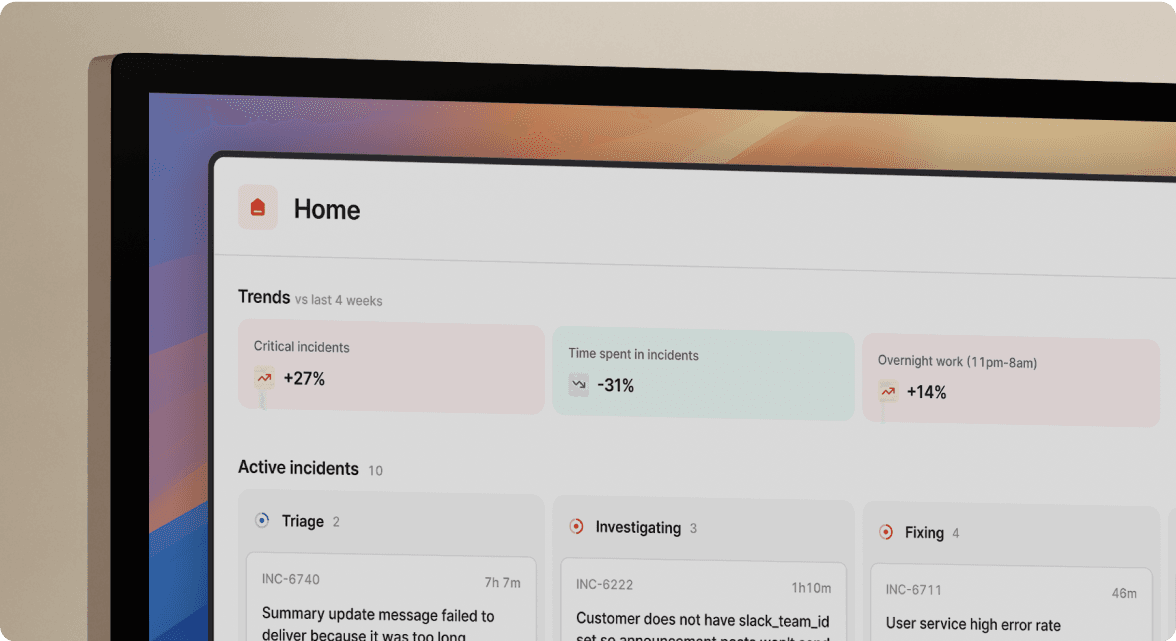
Real-time timeline capture
When an engineer types /inc assign @sarah-devops in Slack, incident.io records the role change with timestamp and full context. When someone shares a Datadog graph showing the latency spike, the platform preserves it. When the team discusses rollback options in a thread, those messages become part of the permanent incident record.
The timeline auto-constructs from multiple data streams:
Slack commands and messages: Pin-to-timeline functionality lets you mark critical messages with the 📌 emoji. Items pinned are stamped at the time of their actual posting, not when they were pinned, so you can catch up on tagging important moments even after they happen.
Integration events: Monitoring alerts from Datadog or Prometheus, deployment notifications from GitHub, alert escalations from PagerDuty, all flow into a unified chronological view without manual logging.
Custom events: If something happened outside the incident channel (customer complaint via email, manual database query), you can add it to the timeline as a custom event by providing the timestamp and description.
"Less time spent putting together an accurate timeline of an incident. It's so easy to pin important messages and updates and automatically it creates the timeline for you." - Verified user on G2
The platform renders a visual copy of the timeline showing events, decisions, and context consolidated in one view. No more jumping between tools to find the deployment that happened at 02:47 UTC.
AI-driven root cause analysis and summarization
incident.io's AI SRE automates up to 80% of incident response coordination by identifying likely root causes, suggesting fixes, and handling documentation during active incidents. This isn't log correlation or pattern matching. The AI analyzes the complete incident timeline to provide specific capabilities:
Automated post-mortem drafting: When you type /inc resolve, the platform drafts a complete post-mortem including timeline, contributing factors, and follow-ups. You spend 10 minutes refining root cause and action items, not 90 minutes reconstructing from memory.
Root cause identification: The AI achieves high precision for identifying code changes that caused incidents, citing specific pull requests and data sources. It spots the likely pull request behind the incident so you can review changes without leaving Slack.
Call transcription via Scribe: incident.io's Scribe feature transcribes incident calls from Zoom or Google Meet in real-time. Scribe generates detailed, structured call notes featuring sections like "Overview," "Key moments," and "Next steps" along with participant lists. Learn more in this video demonstration of Scribe capabilities.
"A recent enhancement introduced a 'suggested summary' feature for incident summaries, using AI to remove the pain of crafting the perfect summary." - Mark K on G2
The AI handles the 80% that is administrative toil. Human engineers validate root causes, refine technical explanations, add nuanced context, and determine follow-up priorities. The 80/20 rule applies: automation does data collection and initial drafting so you spend cognitive effort on analysis and prevention.
Deep stack integrations
Automation quality depends on data completeness. incident.io connects with your entire stack to build comprehensive timelines:
Monitoring and observability: Datadog provides graphs, alert timestamps, and infrastructure context. Prometheus Alertmanager creates incidents and escalations automatically. Grafana contributes dashboard snapshots and metric visualizations. Sentry links errors to incidents for real-time tracking.
Issue tracking: Export and automatically sync incident actions with Jira tickets. Linear receives follow-up tasks and syncs status bidirectionally. This eliminates the manual step of "now go create tickets for all these action items."
Documentation platforms: Export post-mortems to Confluence or Google Docs with one click. Notion serves as the final destination for published reports, maintaining your existing documentation structure.
Version control: GitHub integration shows deployment timelines and links code changes to incidents. When the AI identifies a suspicious deployment, it surfaces the actual pull request for review.
Service catalog: Sync your Backstage or Cortex service catalog into incident.io. Use service metadata in workflows, insights, and automated triggers.
The integration depth means your post-mortem includes not just what happened in Slack, but metrics from Datadog, code changes from GitHub, and alert histories from PagerDuty without manual data gathering.
How automation supports a blameless culture
Objective data removes subjective blame
Blameless post-mortems focus on system failures rather than individual fault, promoting continuous learning and psychological safety. The automated timeline provides an immutable, objective record of system events with precise timestamps, actions taken with full context, technical decisions made with available information, and integration data from monitoring tools.
This creates a factual foundation. Instead of "Who caused this?" the question becomes "What sequence of system behaviors led to this outcome?" Research from Google's Project Aristotle identified psychological safety as the most critical element in high-performing teams. Objective, automated documentation prevents blameful language and finger-pointing by centering discussion on verifiable facts.
Reduced toil increases focus on systemic improvements
Google's SRE Book defines toil as manual, repetitive work tied to running production services that is automatable, tactical, and devoid of enduring value. Manual post-mortem reconstruction is pure toil. Engineers spend cognitive energy on data entry instead of systemic analysis.
Teams with mature post-mortem practices report higher psychological safety scores and faster implementation of system improvements. When the administrative burden drops from 90 minutes to 10 minutes, teams have more energy to focus on the hard questions: What architectural changes would prevent this category of incident? Which monitoring gaps did we discover? How do we make the system more resilient?
Lower barriers encourage proactive incident declaration
Psychological safety research shows that engineers who feel safe are more likely to contribute honest, nuanced insights. When post-mortem documentation is lightweight and automated, engineers stop hesitating to declare incidents. The fear of "creating two hours of work for everyone" evaporates.
"Since using incident.io people are definitely creating more incidents to solve any issues that may arise, including those that are trivial." - Scott K. on G2
More incidents declared means more data captured, more patterns identified, and more opportunities to learn. Proactive declaration of minor issues prevents them from escalating into major outages.
Measuring the impact: KPIs for automated retrospectives
Time to publish post-mortem
Several engineering teams cite post-mortem completion times as a primary measure of learning effectiveness. Track the delta between "Incident Resolved" and "Post-Mortem Published." Best practice target is within 24-48 hours of incident resolution, and no more than five business days.
incident.io customers report reducing post-mortem drafting time from 60-90 minutes to 15 minutes, representing a 75-83% time reduction. Configure your Insights dashboard to track this metric monthly and present trends to leadership.
Post-mortem completion rate
Post-mortem completion rates serve as a numerical proxy for how much teams learn from incidents. Measure the percentage of declared incidents that have completed post-mortems. Target 90%+ completion within your defined timeframe.
"Incident.io stands out as a valuable tool for automating incident management and communication... Another handy feature is its ability to automate routine actions, such as postmortem reports generation." - Vadym C. on G2
Automated platforms increase completion rates by removing the barrier of manual documentation work. When post-mortems write themselves, teams stop skipping them.
Action item closure rate
Respondents tracking follow-up actions most commonly measure completion time and overall percentage of actions completed. Action items that languish incomplete indicate process gaps that could result in repeat incidents.
incident.io automatically creates Jira or Linear tickets from follow-up actions, assigns owners, sets due dates, and sends reminders. Track what percentage close within 30 days. Set a target of 80%+ closure and investigate bottlenecks when rates drop.
Mean Time To Resolution (MTTR) trends
Half of survey respondents cite MTTR or variations (mean time to recovery, mean time to restore) as their north star incident management KPI. MTTR measures how quickly service recovers after failures.
While MTTR is a lagging indicator, reduced coordination overhead directly impacts it. Favor reduced MTTR by 37% using incident.io, largely by eliminating manual coordination overhead. Over 100 incidents per year, automation saves 1,500+ minutes (25+ hours) of pure coordination time.
Track MTTR quarterly and correlate improvements with post-mortem quality and follow-up action completion rates. The ultimate goal: learning from incidents and reducing the likelihood of repeat incidents.
Top post-mortem automation tools compared
| Feature | incident.io | PagerDuty | Manual Docs |
|---|---|---|---|
| Slack-native capture | ✓ Native workflow | ✗ Web-first with notifications | ✗ Manual copy-paste |
| AI post-mortem drafting | ✓ 80% complete in 15 min | ✓ Basic AI summaries | ✗ Manual writing |
| Voice call transcription | ✓ Scribe (Zoom, Meet) | ✓ Scribe Agent | ✗ Manual notes |
| Root cause AI precision | 80% precision | Correlation-focused | Manual analysis |
| Timeline auto-construction | ✓ Real-time from integrations | Partial (alerts only) | ✗ Manual reconstruction |
| Deployment speed | 3-5 days | 2-6 weeks | Immediate (no features) |
| Integration depth | Datadog, Prometheus, Jira, Linear, GitHub | 200+ integrations | Manual per tool |
| Pricing transparency | $25/user/month (Pro) | Custom quote required | Free (engineer time cost) |
PagerDuty remains a web-first platform with Slack as an afterthought. Alert fires in PagerDuty, coordination happens in Slack, tickets get created in Jira, and post-mortems get written in Confluence. The data never unifies. PagerDuty focuses on alerting with weak post-mortem features compared to platforms built around chat-native workflows from day one.
Manual documentation in Google Docs or Confluence costs nothing upfront but burns engineering hours. The hidden cost is incomplete data, delayed learning, and repeat incidents that proper automation would prevent.
Checklist: How to evaluate post-mortem automation tools
Use these criteria when assessing platforms:
- Does it capture data automatically from Slack or Microsoft Teams? Work happens in chat. Tools that are truly Slack-native capture timeline data without requiring manual input.
- Does it integrate with your specific monitoring stack? Verify connections to Datadog, Prometheus, Grafana, or your observability platform. Alert data and metrics should flow into timelines automatically.
- Can it export cleanly to your documentation platform? One-click export to Confluence, Notion, or Google Docs maintains your existing documentation structure without reformatting work.
- Does it offer AI-assisted drafting with verified accuracy? Look for platforms that cite their sources and show their work, not black-box "AI magic." Ask for precision and recall metrics.
- Does it transcribe video calls automatically? Scribe-like capabilities that join Zoom or Google Meet calls and capture decisions in real-time eliminate the need for dedicated note-takers. See this demonstration of AI-powered capabilities.
- How deeply does AI integrate into the workflow? Does it just summarize, or does it identify root causes by correlating code changes with system events? Substance matters more than marketing claims.
- Can you run the entire incident without opening a browser? True chat-native platforms feel like using Slack, not like using a web tool that posts notifications to Slack.
- What is the deployment timeline? Teams using opinionated Slack-native platforms become operational in 3-5 days versus typical 2-6 week configurations for legacy tools. Learn more in this video on incident response workflow automation.
- What is the support model? Shared Slack channels with engineering teams mean bugs fixed in hours. Traditional ticketing systems add days or weeks to resolution.
- Does it meet your security requirements? SOC 2 Type II certification, SAML/SCIM support, and GDPR compliance are table stakes for enterprise adoption.
"The Incident.io team is committed to continuous improvement... The regular updates and responsiveness to user feedback, underscore a commendable dedication to refining the user experience." - Mark K. on G2
Watch how teams think about learning from incidents to understand evaluation criteria from a practitioner perspective.
Ready to eliminate post-mortem toil?
Start by auditing your current costs. Calculate [number of incidents monthly] × [90 minutes per post-mortem] × [blended engineering rate]. That's your baseline waste. Then track completion rates. What percentage of incidents actually get documented?
Try incident.io in a free demo and run your first incident using automated timeline capture. You'll see the difference between reconstruction and recording within one incident cycle. Use the pin-to-timeline feature during your next incident and watch the post-mortem draft itself when you type /inc resolve.
For teams handling 15+ incidents monthly, automation isn't a nice-to-have. It's the difference between learning from every incident and drowning in administrative toil. Book a demo to see how teams reduce post-mortem time by 75-83% while improving documentation quality and follow-up completion rates.
"Spend more time in post mortems looking at problem solving and long term improvements instead of worrying about paperwork." - Verified user on G2
The goal isn't faster paperwork. It's more time spent preventing the next incident. Learn more about tracking follow-up actions effectively to ensure your post-mortem insights translate into systemic improvements.
Key terminology
Timeline: A chronological record of events, alerts, decisions, and communications during an incident, automatically captured with precise timestamps.
Toil: Manual, repetitive work tied to running production services that is automatable, tactical, devoid of enduring value, and scales linearly with service growth.
Root Cause Analysis (RCA): The process of identifying the fundamental system cause of an incident by analyzing contributing factors, not assigning individual blame.
MTTR: Mean Time To Resolution, measuring how quickly service recovers after failures. Used as a north star KPI for incident management effectiveness.
Blameless Post-Mortem: Structured incident review focusing on system failures and learning opportunities rather than individual fault, promoting psychological safety.
Slack-Native: Architecture where the entire incident workflow happens inside Slack using slash commands and channel interactions, not web UI with chat notifications.
AI SRE: Artificial intelligence assistant that automates incident coordination tasks by identifying root causes, suggesting fixes, and handling documentation during active incidents.
Scribe: AI feature that transcribes incident calls from Zoom or Google Meet in real-time, capturing key decisions and generating structured call notes automatically.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

