Automated post-mortems compared: incident.io vs FireHydrant vs PagerDuty in 2025
December 1, 2025 — 16 min read
Updated December 01, 2025
TL;DR: Manual post-mortem reconstruction wastes 60-90 minutes per incident. Modern platforms automate timeline capture and drafting, but capabilities vary widely. We built incident.io's Scribe to transcribe calls in real-time, capture Slack timelines automatically, and draft post-mortems in 15 minutes using AI that automates up to 80% of incident response. FireHydrant offers strong workflow customization. PagerDuty focuses on alerting with weak post-mortem features. With Opsgenie shutting down by April 2027, this forced migration is your chance to upgrade from outdated incident management platforms to platforms that capture context as incidents happen.
The hidden cost of manual post-mortems
Manual post-mortem reconstruction wastes 60-90 minutes per incident as teams search through chat history, monitoring tools, and call recordings trying to piece together what happened. Engineers spend hours reconstructing timelines from fragmented sources, checking alert origins across multiple platforms, and trying to recall decisions made during high-stress moments. Critical context gets lost when conversations happen across video calls, chat threads, and dashboards with no unified documentation.
Ninety minutes later, you have a half-complete post-mortem with fuzzy details and missing context. This is incident archaeology, and it's costing your team more than you think.
If your team handles 20 incidents monthly at 90 minutes per post-mortem, you're spending 30 hours monthly on reconstruction. At $150 loaded engineer cost, that's $4,500 monthly spent on documentation overhead, not reliability improvements.
One retail industry incident.io user managing incident response captured the frustration:
"incident.io has changed how i feel about incidents. im no longer stressed or overwhelmed" - Verified user review of incident.io
The quality problem compounds the time problem. Post-mortems written 3-5 days after incidents miss critical context. In our experience working with hundreds of engineering teams, delayed post-mortems lead to incomplete analysis and repeated incidents because root causes get lost in translation.
We've seen manual post-mortems fail repeatedly because they ask engineers to do something unnatural: perfectly remember and document a high-stress event that happened days ago while juggling five tools and fighting production fires.
What does automated post-mortem mean?
When we talk about automated post-mortems, we don't mean templates you fill out faster. We mean real-time capture of incident context, decisions, and timelines, synthesized by AI into structured reports that are 80% complete before you start writing.
Here's what automation changes:
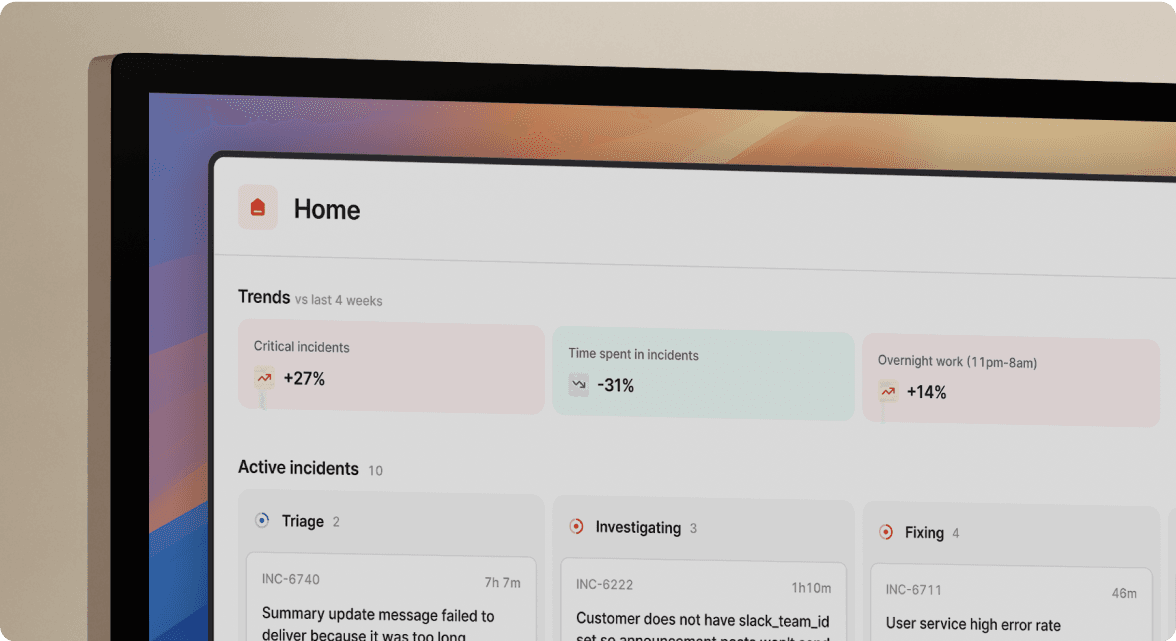
Real-time data capture during the incident: We built our platform to integrate with Slack, monitoring tools, and ticketing systems to automatically capture events as they happen. When an engineer types /inc assign @sarah-devops in Slack, we record the role change with timestamp and context. When someone shares a Datadog graph, we preserve it. When the team discusses rollback options, the conversation becomes part of the timeline.
AI synthesis of timelines and decisions: Instead of manually reconstructing "who did what when," our automated system builds chronological timelines from captured data. Scribe transcribes incident calls, highlights key decisions, and flags root causes mentioned during live discussions. The AI doesn't just record, but it also understands context.
Draft generation with structure: Using the captured timeline, our AI generates post-mortem drafts that include incident summary, timeline of events, contributing factors, and suggested action items. Your engineers spend 10-15 minutes reviewing and refining instead of 90 minutes writing from scratch.
Here's the critical distinction we've learned: automation shifts your engineer time from tedious data gathering to high-value root cause analysis and learning. You're not replacing human judgment. You're eliminating the archaeology.
Comparing automated post-mortem capabilities
Core automation features
| Feature | incident.io | FireHydrant | PagerDuty |
|---|---|---|---|
| Real-time timeline capture | Automatic via Slack commands, messages, role changes | Automatic via platform actions | Manual entry or basic alert logs |
| AI post-mortem drafting | Scribe transcribes calls, AI generates drafts from timeline data | AI Copilot answers questions within templates | Limited; requires add-ons |
| Voice transcription | Yes (Scribe for Google Meet, Zoom) | Yes (Zoom, Google Meet transcription) | No |
| Template customization | Custom templates, exports to Confluence/Notion/Google Docs | Extensive template library with branching logic | Basic templates, limited workflow |
Pricing and support comparison
| Aspect | incident.io | FireHydrant | PagerDuty |
|---|---|---|---|
| Pro tier pricing | $45/user/month with on-call for Pro plan | Custom (not transparent) | ~$60-80/user/month with add-ons |
| Support model | Shared Slack channels, fixes in hours | Standard support tiers | Email-based, slower response |
| Best for | Slack-native teams, Opsgenie refugees | Teams wanting workflow customization | Enterprise alerting complexity |
Note: Team plan is also available for incident.io which starts at $15/user/month on annual billing.
incident.io: Slack-native automation with AI transcription
Strengths of incident.io
We built the entire post-mortem workflow inside Slack. When you run an incident using /inc commands, every action auto-populates the timeline: role assignments, severity changes, Slack threads, shared links. Our Scribe feature records and transcribes incident calls, capturing decisions made verbally without requiring a dedicated note-taker.
When you type /inc resolve, we draft the post-mortem automatically using captured data. One engineering team praised the comprehensive automation:
"The main items we like best about incident.io: - Helpful & responsive customer support - Very intuitive UI and user-friendly - Automated incident creation - Many integrations out-of-the-box - Automation & configuration possibilities - Automated post-incident ..." - Verified user review of incident.io
We also support AI SRE capabilities that identify root causes during incidents, helping post-mortems include accurate technical analysis instead of guesses made days later.
Weaknesses of incident.io
Our platform is deliberately opinionated. Teams wanting infinite customization will find constraints frustrating. Scribe works best with Google Meet and Zoom, other call platforms require manual workarounds. The $45/user/month Pro tier (with on-call) costs more upfront than Team tier, though our unified platform reduces total stack costs by replacing multiple tools.
Best for: Engineering teams living in Slack who want documentation to happen automatically without changing how they work. Teams facing the Opsgenie sunset seeking a modern replacement that handles more than alerting.
FireHydrant: Workflow automation with retrospective templates
Strengths of FireHydrant
FireHydrant built a strong retrospective system with branching logic templates. You can create custom questions that adapt based on incident type or severity. Their AI Copilot feature uses incident data to intelligently answer questions within retrospectives, reducing manual lookup.
The platform captures incident data well and supports extensive integrations with monitoring tools. Timeline building is automatic based on platform activity. FireHydrant also offers AI-powered voice transcription for Zoom and Google Meet calls with real-time transcription and automatic key point summarization.
Weaknesses of FireHydrant
FireHydrant uses custom pricing that requires sales conversations to determine total cost, making upfront budgeting more difficult. Some users report the interface feels more complex than Slack-native alternatives. The web-first architecture requires more context-switching during incidents compared to chat-native platforms.
Best for: Teams wanting sophisticated workflow customization and willing to invest time in configuration. Organizations comfortable with dedicated web UI for incident management rather than chat-native approach.
PagerDuty: Alerting-focused with weak post-mortem features
Strengths of PagerDuty
PagerDuty does well in alerting and on-call scheduling. The platform has extensive integrations and handles complex escalation rules better than anyone. For teams heavily invested in PagerDuty's ecosystem, staying adds convenience.
Weaknesses of PagerDuty
PagerDuty's architecture focuses on alerting and on-call management. Post-mortem capabilities are less developed—the platform captures alert data well but doesn't automatically document coordination happening in Slack or Zoom. You're essentially back to manual documentation or using third-party tools.
Teams migrating from PagerDuty to incident.io consistently cite the lack of unified incident management:
"We like how we can manage our incidents in one place. The way it organises all the information being fed into an incident makes it easy to follow for everyone in and out of engineering. The recent addition of on-call allowed us to migrate our incident response stack from PagerDuty and Statuspage to a single tool." - Verified user review of incident.io
PagerDuty's pricing escalates quickly. Base platform plus AI features, noise reduction, and runbooks can reach $60-80/user/month. You're paying premium prices for alerting excellence but mediocre post-incident learning.
Best for: Enterprise teams deeply committed to PagerDuty's alerting sophistication and willing to supplement with separate documentation tools. Teams where alerting complexity matters more than post-mortem automation.
Rootly: Lightweight automation for smaller teams
Rootly offers AI-assisted summaries and Slack-native incident management similar to incident.io but with less feature depth. Good for smaller teams seeking affordable automation without enterprise complexity. Lacks the advanced AI capabilities and voice transcription found in incident.io and FireHydrant.
How incident.io automates the post-mortem lifecycle
Let's look at what automation actually looks like during a real incident.
Alert to resolution in Slack
At 2:47 AM, your Datadog alert fires: API latency spiking to 5000ms. We automatically create #inc-2847-api-latency-spike in Slack, page the on-call engineer, and pull in the API service owner. The channel contains the triggering alert, recent deployments, runbook links, and a live timeline that's already recording. Everything happens where your team already works.
Sarah joins and types /inc summary "API response times spiking" and /inc severity high. Your team starts a Zoom call to coordinate. Scribe joins automatically and transcribes everything in real-time. When someone says "I think this correlates with the 2:30 AM deployment," Scribe flags it as a key moment. When you decide "let's rollback first," that decision is captured.
One insurance industry user described the seamless workflow:
"Huge fan of the usability of the Slack commands and how it's helped us improve our incident management workflows. The AI features really reduce the friction of incident management. ... It's easy to set up, and easy to..." - Verified user review of incident.io
From resolution to complete post-mortem in minutes
Sarah identifies the root cause and types /inc resolve "Rolled back deploy #4872, connection pool stable". Within 10 seconds, we generate the post-mortem draft with incident summary, complete timeline, transcribed call highlights, contributing factors, and suggested follow-up actions.
Sarah spends 10 minutes refining the AI draft and exports to Confluence with one click. Total post-mortem time: 15 minutes instead of 90. We automatically create follow-up tasks in Linear and update your status page. No manual work required.
A real estate industry user summarized the comprehensive approach:
"Too many to list - it's a one stop shop for incident management (not just on call rotations like many competitors. Built in and custom automations, great slack integration, automated post mortem generation, jira ticket creation, followup and actions creation,..." - Verified user review of incident.io
Navigating the Opsgenie sunset
Atlassian's Opsgenie shutdown forces every current user to migrate by April 2027. You can move to Jira Service Management (Atlassian's preferred path), PagerDuty (lateral move for alerting), or upgrade to a modern platform that solves the post-mortem problem.
Why JSM won't solve your post-mortem pain:
JSM is a service desk platform adapted for incident management. It's built for ticket workflows, not real-time incident response. Post-mortem capabilities are essentially Confluence docs with Jira integration—still manual, still requiring reconstruction from memory. If you were frustrated spending 90 minutes per post-mortem with Opsgenie, JSM won't fix that.
Why this is your upgrade opportunity:
The forced migration lets you ask: "What if we solved incident management completely this time?" Instead of just replacing alerting, adopt platforms that handle on-call scheduling, incident coordination, status pages, and post-mortems in one unified system. Engineering teams like Intercom report being operational with incident.io in a short time, not quarters.
The Opsgenie sunset forces a migration decision. It also exposes how much time your team wastes on incident archaeology when we built platforms that capture everything automatically.
incident.io, FireHydrant, and others prove that post-mortems don't need to be 90-minute exercises in memory reconstruction. Real-time timeline capture, AI transcription of incident calls, and automated draft generation turn documentation from a burden into a byproduct of doing the work.
Choose a platform that fits your workflow. If you live in Slack and want everything automated with minimal configuration, we deliver. If you need extensive customization and control, FireHydrant offers that. If you're deeply committed to PagerDuty's alerting, add a separate documentation tool rather than settling for their weak post-mortem features.
The teams already using these platforms aren't spending 90 minutes reconstructing timelines. They're spending that time on reliability improvements, reducing repeat incidents, and shipping features instead of fighting fires.
Schedule a demo to see Scribe transcribe a live call and watch the post-mortem generate in real-time. Either way, stop doing archaeology.
Key terminology
MTTR (Mean Time To Resolution): Average time from incident detection to full resolution. Automated post-mortems help reduce MTTR by capturing context during incidents, enabling faster learning cycles.
Incident archaeology: The painful process of reconstructing what happened by manually scrolling through Slack history, checking multiple tools, and relying on team memory days after events occurred.
Real-time timeline capture: Automated recording of incident events, decisions, and role changes as they happen. Eliminates manual note-taking and ensures complete documentation.
Scribe: Our AI feature that transcribes incident calls from Google Meet or Zoom in real-time, highlights key decisions, and feeds transcribed content into automated post-mortem drafts.
Slack-native incident management: Architecture where the entire incident workflow happens inside Slack using slash commands and channel interactions, not web UI with Slack notifications bolted on.
AI SRE: Artificial intelligence assistant that automates incident coordination tasks by identifying root causes, suggesting fixes, and handling documentation during active incidents. Our AI automates up to 80% of incident response coordination.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

