Post-mortem software integrations: building your incident management stack in 2026
February 16, 2026 — 21 min read
Updated February 16, 2026
TL;DR: Your incident management stack likely consists of five distinct tool categories: observability (Datadog, Prometheus), alerting (PagerDuty, Opsgenie), coordination (Slack, Teams), ticketing (Jira, Linear), and documentation (Confluence, Notion). If these tools don't talk to each other, you're forcing engineers to be the manual API, copy-pasting context between tabs while production burns. Manual post-mortems waste 60-90 minutes per incident (based on engineering teams incident.io works with), and teams handling 20 incidents monthly spend $4,500 per month on documentation overhead alone. The fix: deep, bi-directional integrations that auto-construct timelines, sync state across systems, and eliminate the "tool whack-a-mole" game that extends MTTR by 12+ minutes per incident (based on engineering teams incident.io works with).
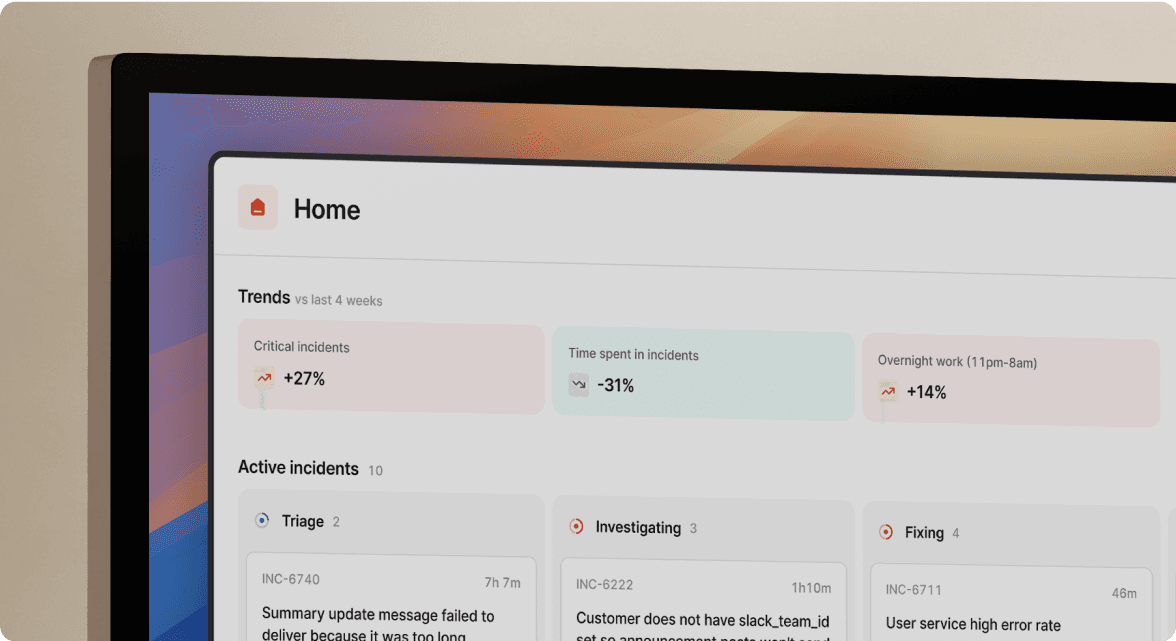
Production incidents expose the hidden cost of tool sprawl. The typical SRE toggles between Datadog for metrics, PagerDuty for alerts, Slack for coordination, and a Google Doc for notes. Twelve minutes elapse assembling context before troubleshooting begins. Three days later, reconstructing the timeline from Slack scroll-back and PagerDuty history takes 90 minutes. Critical decisions made in Zoom calls are lost. The pattern repeats. This is post-mortem archaeology, and it costs more than most teams realize.
The hidden cost of "post-mortem archaeology"
Post-mortem archaeology is the manual, time-consuming process of reconstructing incident timelines after the fact. Manual post-mortems waste 60-90 minutes per incident, and post-mortems written 3-5 days after incidents miss critical context, leading to incomplete analysis and repeated incidents.
If your team handles 20 incidents monthly at 90 minutes per post-mortem, that's 30 hours monthly on reconstruction. At $150 loaded engineer cost (based on average SRE salary of $168,897/year per Glassdoor, 2026), that's $4,500 monthly spent on documentation overhead. Add the coordination tax: teams spend 12 minutes per incident on coordination overhead (based on engineering teams incident.io works with), which for 15 incidents monthly equals 180 minutes ($450) in pure context-switching waste. Research shows it takes an average of 23 minutes to regain focus after each interruption (Gloria Mark, University of California Irvine).
Observable activities that constitute post-mortem archaeology:
- Cross-referencing timestamps across multiple systems (Datadog, Slack, PagerDuty logs)
- Scrolling through Slack threads to find what decisions were made and when
- Manually extracting graph snapshots from monitoring tools
- Copy-pasting data from multiple sources into a post-mortem template
According to Google SRE, "toil" is work that is "manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows." Post-mortem reconstruction is textbook toil.
Anatomy of a connected incident management stack
A modern incident management stack consists of five canonical layers, each serving a distinct purpose in the incident lifecycle.
Layer 1: Observability ("The Eyes")
Purpose: Monitor system health, metrics, logs, and traces.
Market leaders: Datadog, Prometheus, New Relic, Grafana
Your incident management solution should integrate with observability platforms in your existing stack. These tools tell you what broke and when, but they don't coordinate the response.
Layer 2: Alerting ("The Siren")
Purpose: Detect issues and page on-call engineers.
Market leaders: PagerDuty, Opsgenie
The gap between "getting paged" and "starting the fix" exists because vendors built traditional on-call tools for a single job: reliable alert delivery. PagerDuty excels at routing alerts but lacks coordination depth once you acknowledge.
Layer 3: Coordination ("The War Room")
Purpose: Real-time communication and collaboration.
Market leaders: Slack, Microsoft Teams
The defining feature of modern incident management is chat-native response. When an alert fires, the entire incident lifecycle should happen in Slack or Microsoft Teams, not in a web dashboard.
Layer 4: Ticketing ("The To-Do List")
Purpose: Track follow-up work and action items.
Market leaders: Jira, Linear
Dedicated incident management software is faster for on-call, alert routing, ChatOps, and post-mortems. Most modern platforms integrate with Slack or Microsoft Teams for ChatOps, plus Jira and GitHub.
Layer 5: Documentation ("The Library")
Purpose: Knowledge base and post-mortem storage.
Market leaders: Confluence, Notion
Whether you're using Google Docs, Notion, Confluence or another document provider, save yourself countless hours by using automated post-mortem templates instead of manual copy-paste.
The central problem: These five layers rarely communicate with each other. Post-mortem software sits in the middle, ingesting data from observability, alerting, and coordination tools to populate ticketing and documentation systems.
"Without incident.io our incident response culture would be caustic, and our process would be chaos. It empowers anybody to raise an incident and helps us quickly coordinate any response across technical, operational and support teams." - Matt B. on G2
Integrating observability: Datadog and Prometheus
Your observability platform is the first domino in the incident cascade. The integration must turn metrics into timeline events automatically.
How Datadog integration works
You create a webhook in Datadog that triggers incidents by sending alerts to your incident.io alert source. Once configured and connected to a route, Datadog monitors can automatically trigger incident creation.
The integration flow:
- Webhook configuration: Datadog monitor fires and sends webhook payload to incident platform API
- Incident creation: Platform receives payload and creates dedicated Slack/Teams channel
- Context enrichment: Platform pulls monitor details and attaches them to the incident
When you join an incident channel, everything you need is right there: the triggering monitor name with a link, up to 500 characters of the monitor body, and runbook links if you've added them to your monitors.
Graph snapshot integration
If you paste in a Datadog snapshot link, Slack unfurls the image. Pin that message and the platform adds the linked image to your timeline automatically.
The limitation of built-in incident features
Many observability platforms offer their own incident management. The primary limitation: they excel at showing you what broke, but lack depth in coordinating the response. PagerDuty's architecture focuses on alerting and on-call management. Post-mortem capabilities are less developed. The platform captures alert data well but doesn't automatically document coordination happening in Slack or Zoom.
Benefit: See exactly what the CPU spike looked like at the moment the alert fired, without leaving Slack or opening browser tabs.
"My favourite thing about the product is how it lets you start somewhere simple, with a focus on helping you run incident response through Slack. Once you're ready for more, it's got great features you can dive into (post-mortem templates, action item tracking) and integrations with all the major tools (Statuspage, GitHub, etc)." - Chris S. on G2
Connecting alerting and on-call: PagerDuty and Opsgenie
Bi-directional sync between your alerting platform and incident coordination tool is critical. One-way notifications add noise. Two-way state management reduces cognitive load.
Technical difference: One-way vs. bi-directional sync
One-way sync (webhook): PagerDuty fires alert and sends notification to Slack. Information flows in one direction only. Actions in Slack don't update PagerDuty. This is a "read-only" integration.
Bi-directional sync (API-based state management): Two-way sync means bidirectional data flow where changes in either system propagate in near real-time. Automatically create, update, acknowledge and resolve PagerDuty incidents with two-way sync using account-level API keys.
Managing the lifecycle from chat
Slack-native architecture means you can acknowledge alerts, escalate to another team, assign roles, update severity, and resolve incidents using slash commands. You type /inc escalate to pull in another team, /inc severity critical to escalate priority, and /inc resolve to close the incident.
This isn't just convenience, it's a fundamental reduction in cognitive load. Compare this to the traditional flow: PagerDuty sends an alert to Slack, you click the link which opens a web browser, you log into the web UI (10-15 seconds), you acknowledge the alert there, then you return to Slack to coordinate. That's four context switches costing 30-45 seconds before you've even started investigating.
Bi-directional resolution means you can resolve incidents in either system to streamline your workflow. Comment syncing means making a comment in one system automatically updates the connected incident.
Benefit: Eliminates the "who is on call?" scramble and manual phone unlocking to acknowledge alerts.
Syncing ticketing and issue tracking: Jira and Linear
Follow-up actions are where good intentions go to die. Without bi-directional sync between your incident platform and ticketing system, action items get lost in documentation.
The typical failure mode
Many organizations either haphazardly put together post-incident notes that live in disparate places or don't know where to start in creating their own post-mortems. Action items listed in Confluence docs don't appear in sprint backlogs. Items "assigned" via @mention in documents have no owner in the project management system. No deadlines or reminders exist.
Follow-up actions convey what's being done to reduce the likelihood and impact of similar events in future. The critical risk: The same issue causes a repeat incident because the fix was never prioritized or completed.
How action item sync works
With Jira connected you can export follow-ups via the web dashboard and Slack/Teams apps. Information on the ticket such as its title, assignee, and completion syncs back, updating the corresponding follow-up.
Step-by-step process:
- User runs
/inc actioncommand or clicks action button in Slack - Form appears in Slack to capture action details (title, assignee, description)
- Platform makes API call to Jira/Linear
- Jira/Linear ticket created with link back to incident
- Ticket status syncs back to post-mortem
You can configure automatic export based on incident attributes. This ensures tickets are created in the right Jira projects without incident responders thinking about it. When enabled, a Jira ticket represents each incident and automatically syncs when the incident changes.
Benefit: Creates a "closed loop" where action items don't get lost, status updates flow bidirectionally, engineering teams see incident context attached to tickets, and post-mortems show real-time completion status.
"I really like that incident.io is slack-centric, everyone can collaborate. The slackbot helps us with all of the incident management functions we need. Its functions help us to have clarity on who is doing what to drive incidents forward." - Mateus B. on G2
Automating documentation: Confluence and Notion
Post-mortems only create value if they're accessible, searchable, and actually read by the wider organization.
One-click export process
If you're more comfortable writing your post-mortem in an external system like Confluence, Notion or Google Docs, you can write it there. The platform exports the template with pre-filled incident data like the incident summary and timeline.
Export workflow:
- Complete post-mortem or configure for external writing
- Click "Export to Confluence" or "Export to Notion" button
- Choose the correct destination depending on team or service
- Fields map automatically (incident summary to title, timeline to body)
- New page created with formatted content
You can add multiple destinations for post-mortems using different Confluence folders. Integrate Confluence via the Atlassian Marketplace app. The Notion integration allows you to export post-mortems into Notion for team collaboration.
Benefit: Consistent formatting and discoverability for all post-mortems in your central knowledge base, without manual copy-paste work. Your incidents become searchable organizational memory.
Linking CI/CD pipelines: GitHub and GitLab
The critical question during any incident: "What changed?" Integrating your CI/CD pipeline with incident management helps answer this automatically.
While GitHub and GitLab integrations exist for issues and merge requests, you can add deployment events to your timeline as custom events by providing the timestamp and title. This helps answer the critical "what changed?" question during incidents.
Benefit: Reduces time to identify a potentially bad deploy as the root cause by showing deployment context with your incident timeline. Instead of asking "did we deploy recently?" and waiting for someone to check, you can manually add this information to the timeline.
Real-world workflow: From alert to analysis without copy-pasting
When a Datadog alert fires for API latency spiking, the platform auto-creates a dedicated Slack channel. PagerDuty pages the on-call SRE, who joins to find everything needed already there: the triggering monitor details, runbook links, and recent deploy information. Datadog graph snapshots show the latency spike correlated with deployment time. The SRE identifies a database query problem in the suspicious deploy, initiates rollback, and types /inc resolve when latency returns to normal. The platform uses AI to draft the post-mortem in 15 minutes, and /inc action creates a Jira ticket for 'Add database query performance tests to CI pipeline' with automatic status sync back. The post-mortem exports to Confluence with pre-filled incident data. Total time: 20 minutes from alert to documented learnings. Time saved vs. manual process: 12 minutes on team assembly, 90 minutes on post-mortem reconstruction.
Checklist: 5 questions to ask about integration capabilities
When evaluating post-mortem software, use this checklist to assess integration depth:
1. Is it bi-directional?
Does the integration write back to the source system or just read? Two-way sync means bidirectional data flow where changes in either system propagate in near real-time. One-way sync creates state drift.
Test it: Resolve an incident from Slack. Does the PagerDuty alert close automatically?
2. Is it Slack-native or Teams-native?
The defining feature of modern incident management is chat-native response. The entire incident lifecycle should happen in Slack or Microsoft Teams, not in a web dashboard.
Test it: Can you acknowledge alerts, escalate to teams, create action items, and resolve incidents using slash commands, or do you need to open a web UI?
3. Does it support custom mapping?
Can you map severity levels, incident types, and custom fields between systems? Generic integrations force you into vendor defaults.
Test it: Can you map your P0/P1/P2 severity schema to Jira priority levels automatically?
4. Does it handle attachments?
If you paste in a Datadog snapshot link, Slack unfurls the image. Graphs, logs, and screenshots are critical incident context.
Test it: When you share a Datadog graph link in the incident channel, does it automatically appear in the timeline?
5. Is it secure?
API scopes, SOC 2 certification, and data handling matter when you're granting a tool access to production systems.
Test it: Does the integration use OAuth with minimal required scopes? Is there an audit log of API calls?
"The velocity of development and integrations is second to none. Having the ability to manage an incident through raising, triage, resolution, and post-mortem all from Slack is wonderful. Anyone in our business is able to interact and contribute to incidents frictionlessly, which allows for better feedback loop on issues and fixes." - Terry A. on G2
How incident.io helps
We built incident.io to eliminate the tool tax. Our Slack-native architecture means the entire incident lifecycle happens where your team already works.
Our key integration capabilities:
- Auto-created incidents: We trigger incident creation automatically from Datadog, Prometheus, and PagerDuty alerts with context pre-loaded
- Bi-directional sync: Resolve incidents in either system with our two-way state management
- Automatic timeline capture: We record every Slack message, command, and role change automatically
- Jira and Linear sync: We export follow-ups with automatic status updates flowing back to your post-mortem
- One-click export: We publish to Confluence or Notion with intelligent field mapping
Teams using our platform typically reduce median P1 MTTR by 25-40%. Proven results: Intercom saved 40% of incident time after migrating to incident.io. Favor reduced MTTR by 37%.
Learn more about our Slack-native incident management, AI-powered post-mortems, and integrations ecosystem.
Book a demo to see how incident.io eliminates the tool tax across your Datadog, PagerDuty, Jira, and Slack stack.
FAQs
Can I use incident.io with my existing PagerDuty subscription?
Yes. incident.io integrates with PagerDuty bidirectionally for alert routing and on-call management.
Do Jira tickets update automatically when incidents are resolved?
Yes. When enabled, a Jira ticket represents each incident and we automatically sync the ticket when the incident changes in incident.io.
Can I export post-mortems to multiple Confluence spaces?
Yes. You can add multiple destinations for post-mortems using different Confluence folders based on team or service.
What happens if my Slack workspace goes down during an incident?
We maintain incident state in our platform and sync automatically when Slack recovers. For Slack outages, teams typically escalate to direct paging via PagerDuty.
Key terms glossary
Bi-directional sync: Integration pattern where changes in either system (incident platform or external tool) propagate automatically to the other, maintaining consistent state across both systems.
Slack-native: Architecture where the entire incident workflow happens inside Slack using slash commands and channel interactions, not web UI with Slack notifications bolted on.
Tool tax: Time overhead spent assembling context, finding the right people, and switching between tools during incident response before actual troubleshooting begins. Typically costs 12-15 minutes per incident.
Post-mortem archaeology: Manual process of reconstructing incident timelines days after resolution by cross-referencing logs, chat history, and team memory. Manual post-mortems waste 60-90 minutes per incident.
Timeline capture: Automated recording of incident events, decisions, role changes, and artifacts (graphs, logs) as they occur in real-time, eliminating manual note-taking.

Tom Wentworth
Chief Marketing Officer
See related articles

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


