Let's make incident management convenient, shall we?
February 24, 2023 — 4 min read
👋 Hey folks
Don't you hate it when you copy and paste something and lose all of your beautiful, shiny formatting? Especially when you've spent hours getting it right? We do, too.
Well, now this is a thing of the past when it comes to post-mortems. But we didn't stop there. Keep reading to learn about this, and other features we launched in February 🔥
Oh, and be sure to check us out at SRECon later this month if you want a peek at what we have in the pipeline—more details below. We promise it'll be worth your time 😄
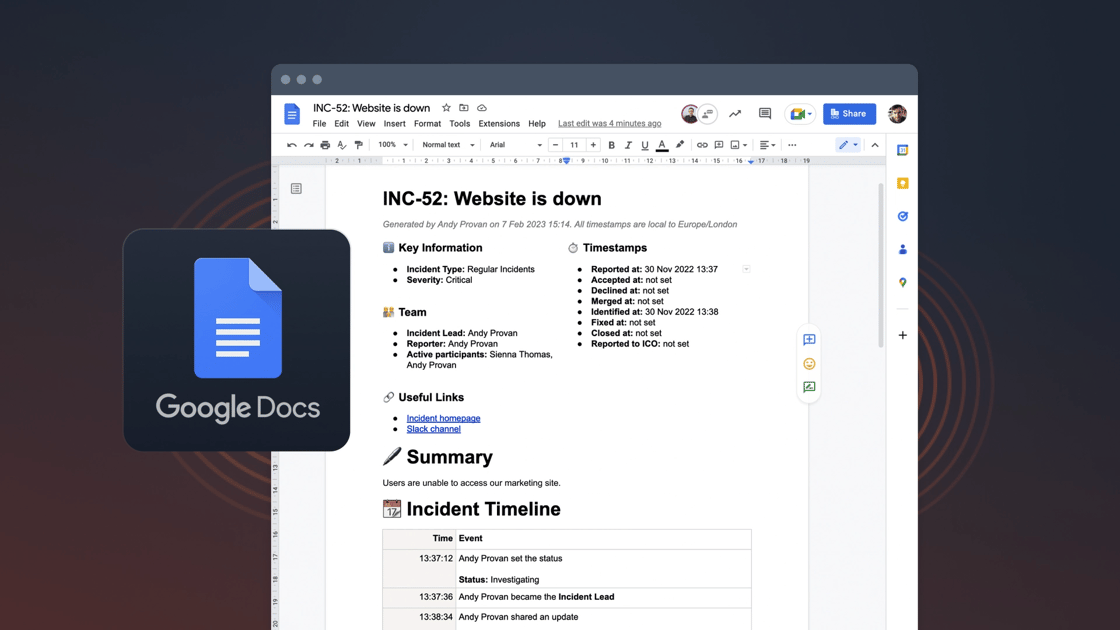
Export your debriefs to Google docs
This is one we’re really excited about—exporting your incident post-mortems directly into Google Docs!
When you export your post-mortem, all key details about your incident will be carried over, including an end-to-end timeline of everything that happened. Now, all of your post-mortems will exist in a single place, so you can track them down in seconds.
Wave goodbye to copy-paste and enjoy beautifully formatted post-mortems you can glean takeaways from at a glance.
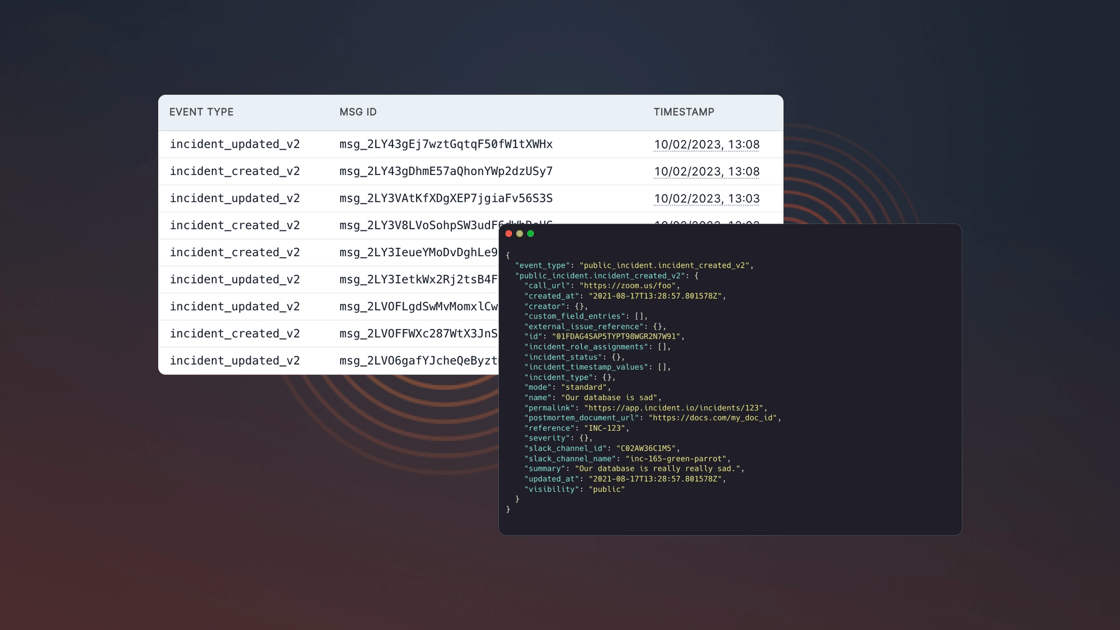
Get connected with Webhooks
You asked, and we listened.
Now incident.io users can use webhooks to push data to an app's endpoint. When we first built our API, we got a lot of feedback from customers who wanted to plug our platform into different tools. The API was the first step towards this—webhooks take care of the other part.
Through webhooks, you can listen for changes and perform actions such as syncing follow-ups or warning about ongoing incidents during code deploys.
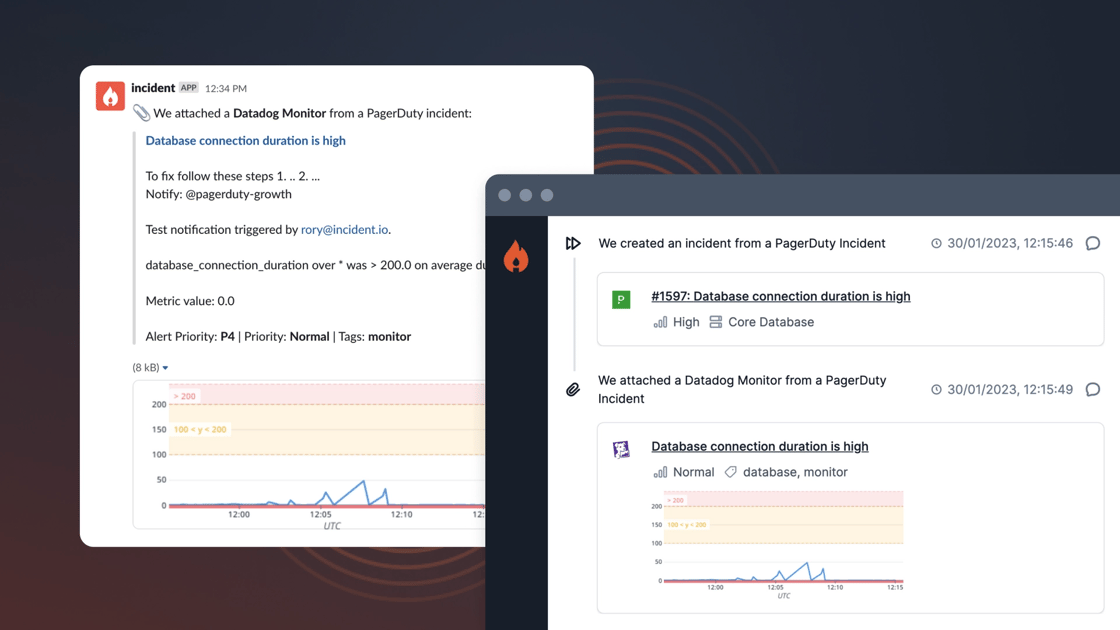
Pulling data from Datadog
Incident management is all about speed and pace. And when there’s a high-severity incident, the last thing you want to be doing is bouncing around different links trying to find the information you need to diagnose the issue.
That’s why we’ve just released an integration with Datadog. When incidents are triggered using Pagerduty or Opsgenie, we’ll automatically pull information about any Datadog monitors that triggered that alert. Then when you join that incident channel, you’ll see a host of relevant information, including:
- The name of the offending Datadog monitor, along with a link to explore more at that point in time
- An image of the monitor, so you can see its recent history and determine if it gradually got worse or if it was a sudden spike
- Up to 500 characters of the description of your monitor
- …and more
We're SSO excited about SAML!
Single Sign-On via SAML is now enabled! Now users can quickly and easily access their incident.io dashboards using their current SAML provider, such as Okta. The time savings here are hard to overstate—now admins can control user or group access in bulk to incident.io.
And watch this space because we'll soon support SCIM 🎉

The importance of transparency
Regardless of the size of your company, practicing transparency across all aspects of your day-to-day can be a game-changer. It’s something that we wholeheartedly believe in here at incident.io.
But why should you adopt it in the first place?
In this article, we explore why we’ve made transparency a key part of our culture and explain why you may want to do the same.
Non-technical teams should be declaring incidents, too
Incident management is something usually delegated to technical teams, e.g., engineers. And in many ways, that feels like the most rational and reasonable decision. But the reality is that companies should not only empower but encourage non-technical teams to declare incidents.
Check out our article to learn why.
We’re going to SRECon!
We’ve been busy planning for our first conference of the year: SRECon US. The team will be in Santa Clara, CA, from March 21-23rd.
Come by Booth 400 to say hi!
Looking forward to seeing lots of you there.
See related articles
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization



