Your non-technical teams should be using incident management tools, too
February 8, 2023 — 8 min read

For many businesses across the world, incident management is something that’s usually left to engineers.
These teams are on the front lines, declaring, managing, and resolving all sorts of incidents across the org, regardless of where it originates or what form it takes. But there’s a glaring issue with this approach.
Outside of technical teams, people across organizations aren’t accustomed or trained to use the word “incident” whenever an issue comes up. For them, an ‘incident’ is yet more technical jargon: another language that doesn’t overlap with their day-to-day function.
The reality is that organizations have more incidents across functions than people realize—they’re just not calling them that! But incidents are exactly what many of these issues are—and starting to categorize them as that can be huge for your company.
So should your non-technical teams be declaring incidents like your engineering team? Should they be using an incident response lifecycle and incident management tool to communicate throughout the response process? Absolutely. Here's why:
Many issues in non-technical functions are actually incidents in disguise
Let’s use two hypothetical situation to illustrate the point here. First, imagine you have a former employee who’s breached their contract and has threatened to disclose confidential information that will jeopardize the future of your business.
Is this a big deal? Absolutely. Potential information breaches keep people up at night.
Let’s think about how you might respond to this situation. You would need to respond to the breach with the level of severity that it deserves—this is a critical situation that requires a all-hand-on-deck approach. You would then coordinate and rally everyone who needs to be involved—managers, engineers, VPs, and more. You would then have to investigate how to prevent this data breach as quickly as possible with the help of your engineering team.
Once the fire is out, you would then come together to figure out how to avoid situations like these in the future. Data breaches are a PR nightmare so you’d want to make sure you’re putting as many resources as possible towards avoiding this entirely.
Now take a typical “technical” incident declaration and response process. An engineer finds an issue that’s causing a website outage—let’s assume this one isn’t as severe as the hypothetical data breach above. Either way, in this case, they would declare an incident using their tool of choice, and teams would then coordinate to resolve the incident and communicate throughout the process. They would then come together in a few days to figure out how they can avoid incidents like these in the future.
The first scenario is starting to look and sound a lot like an incident, isn’t it?
Evangelizing incidents is a strategic and ultimately transformative business decision
If you’ve siloed incident management in your engineering team, you likely have several incident, or “issue” response processes across your organization. And you might even be responding to non-technical issues ad hoc.
While that might work when your organization is small, it’s not a scalable solution as your product gets more complex, your customer base expands, and your potential vulnerabilities grow.
By siloing incident response to engineering, you unintentionally create a lack of alignment across departments since everyone is essentially managing incidents — regardless of what they call them — the way they think is best.
To add to this, when your incident response is siloed, you can’t ever glean high-level insights about your incidents. This is because incidents aren’t in a single database. They’re spread across many tools and documents. Wrangling all of these to try to deduce patterns or any meaningful insight is going to be tough even for the most dedicated person.
No insights plus disparate processes is the formula for inefficiency in fast-scaling organizations - which is why the incident maturity model emphasizes centralized visibility.
When you decide to loop everyone into the incident response process, you ensure that all issues are dealt with using the same processes. Granted, not all incidents are the same and some will be more severe than others. But by following incident communication best practices and having a structure in place that everyone can follow, regardless of technical competency, you can get one step closer to an efficient workflow that gets to the root of incidents quicker.
Everyone can and should declare incidents
Even from the earliest days of your business, you should be making an effort to reinvent the way functions think about incidents.
Incidents don’t have to only be app outages or website glitches. They can be anything that negatively impacts product, sales, legal, marketing, design, or any number of teams across your organization.
As explored in incidents are for everyone, making incident management a company-wide process gets you one step closer to turning incident response into a well-oiled machine. You’ll say goodbye to the days of ad hoc incident response that varies by department. Gone will be the days of overworked engineers dealing with issues that may not necessarily call for them.
incident.io can help non-technical teams feel empowered and confident when declaring incidents
Getting non-technical teams on board to use an incident management tool can be a hard-sell if the platform is complex, difficult to navigate, and clearly designed for engineers.
And as a broader point, adopting complex tools, even for engineers, can create unnecessarily long adoption timelines that cut into productivity. At the end of the day, no one wants to use a tool that take weeks to use competently.
One of the things we like to say at incident.io is that everyone should feel empowered to declare an incident. That’s exactly why we designed a product that allows for exactly that. Our tool is simple to use, straightforward to navigate, and since it's built around slack-native incident response, adoption is smooth throughout your entire company.
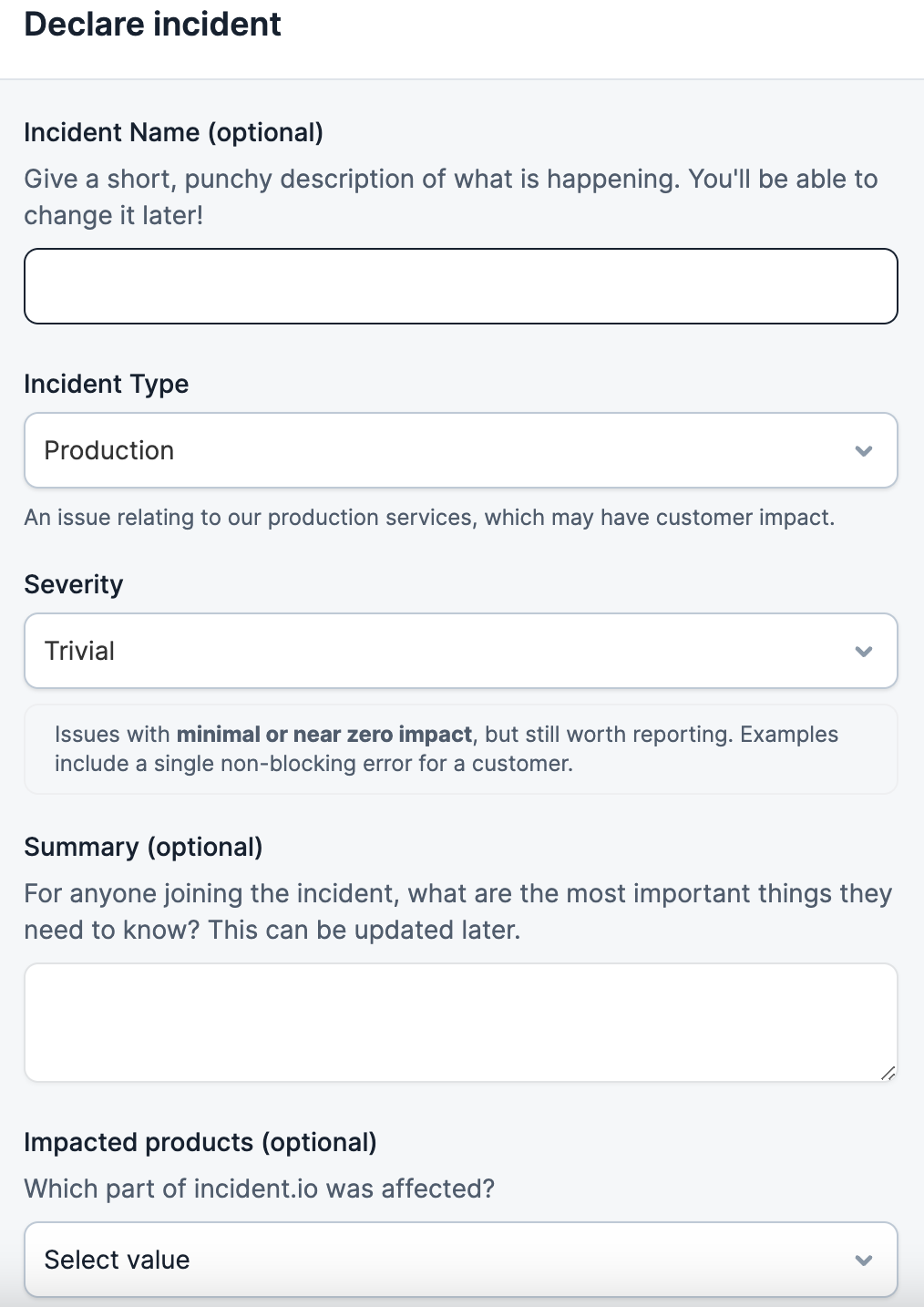
What you’re seeing above is our actual incident declaration form. All folks need to do is fill out the incident name (this can be anything), type (what the issue is affecting), severity (we include a handy note that explains what to consider when deciding severity) and a summary field.
And because every team and organization is different, you can create custom fields that best suit your needs and processes. Then, once an incident is declared, the right folks can rally around to get the incident resolved—technical or otherwise. We feel like it’s the most straightforward workflow for all functions, from sales down to customer support and everything in between, to feel empowered to declare incidents quickly.
In the end, we want companies to fundamentally reimagine the way they think about incidents. They’re much more than just something for engineers to worry about. And the reality is, you’re already dealing with incidents every single day. But when you democratize the concept of incidents across your organization and create processes around them, you’ll save time, be more efficient, and ultimately protect your customers better.
So will you start calling your issues incidents? We hope you do. And when you’re ready, check out our demo to see our straightforward and customizable workflows in action.

Stephen Whitworth
Co-Founder & CEO
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

