Splunk on-call vs. incident.io: Slack-native incident management platform
December 8, 2025 — 14 min read
Updated December 08, 2025
TL;DR: Splunk On-Call handles alerting and basic on-call scheduling, but managing incidents still requires jumping between Slack, the Splunk web UI, and mobile apps. This context switching creates coordination overhead that slows resolution. We eliminate this tax by running your entire incident lifecycle in Slack, from alert to post-mortem, using slash commands and automated workflows. For teams invested in Splunk Observability Cloud, we integrate via webhooks so you keep your monitoring stack while modernizing your response workflow. Teams using our platform report significant MTTR improvements without abandoning their Splunk investment.
Your Splunk observability stack tells you exactly what's broken. Splunk On-Call pages the right person. But then what happens?
Alert acknowledgment happens in one tool, team coordination in another, escalation details in a third, status updates in a fourth. Engineers context-switch between mobile apps, web interfaces, and chat platforms while critical minutes pass before troubleshooting begins.
The core question for engineering teams using Splunk's ecosystem: does the convenience of a bundled on-call platform tool outweigh the operational cost of a workflow designed for 2015?
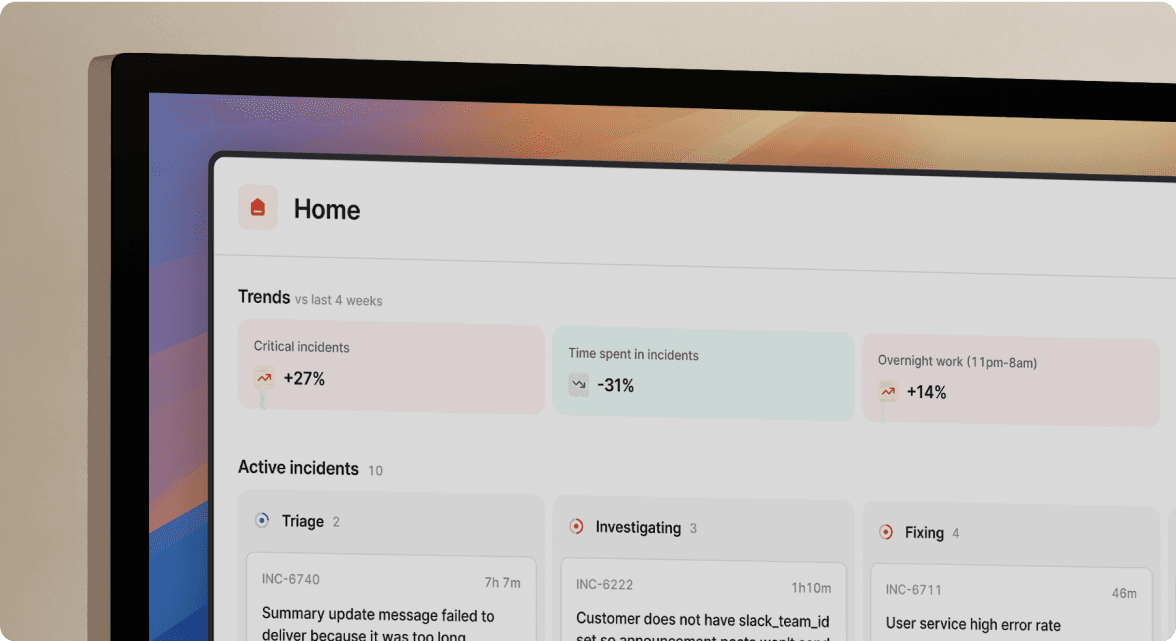
At a glance: alerting vs. coordination
Splunk On-Call excels at one job: routing alerts to the right responder through escalation policies. It's an alerting router with a capable rules engine. We handle the full incident lifecycle, including coordination, communication, learning, and follow-up, inside the tools your team already uses.
The architectural difference matters because effective incident response requires substantial coordination. When your database connection pool is exhausted, the hard part isn't restarting pods. The hard part is assembling the right people, maintaining context across multiple simultaneous investigations, keeping stakeholders informed, and capturing what happened for the post-mortem.
Splunk On-Call assumes you'll handle coordination elsewhere. We make coordination our core value proposition, using Slack as the command center where engineering work already happens.
Feature comparison: what you get from each platform
| Capability | incident.io | Splunk On-Call |
|---|---|---|
| On-call scheduling | Flexible rotations, follow-the-sun, shadow schedules, calendar sync | Rotations, overrides, escalation policies |
| Alerting channels | Phone, SMS, email, Slack, push notifications | Phone, SMS, email, push via mobile app |
| Incident coordination | Full lifecycle in Slack via slash commands | Timeline view, basic Slack actions, primary management in web/mobile UI |
| Status pages | Built-in public and private pages, auto-updated | Requires third-party integration |
| Post-mortems | Auto-generated from captured timeline | Manual post-incident reviews, metrics dashboard |
| AI capabilities | AI SRE for investigation and automated fixes | Limited to intelligent alert routing |
| Mobile experience | Via Slack mobile app | Dedicated iOS/Android apps |
| Workflow automation | Unlimited custom workflows (Pro plan) | Rules engine for alert routing |
| Integration architecture | Webhook-based with 40+ native integrations | Native Splunk ecosystem, 200+ integrations |
The context switching tax: comparing user workflows
Splunk On-Call workflow: coordination across multiple tools
When a P0 alert fires, here's the typical Splunk On-Call workflow:
- Push notification wakes the on-call engineer
- Open Splunk mobile app to acknowledge
- Switch to Slack to manually create coordination channel
- Tag relevant team members
- Jump back to Splunk web UI for escalation details
- Update incident status in Splunk
- Remember to update external status page
- Manually reconstruct timeline for post-mortem
One engineer on the devops subreddit described their experience:
"Try Victorops (Splunk on-call) for a week and your experience will suddenly become very user friendly. VO was the absolute worst." - Reddit user discussion
While individual, this reflects the friction legacy tools create during critical moments.
incident.io workflow: unified incident management in Slack
The same P0 alert through our workflow:
- Slack notification on mobile
- We auto-create dedicated channel
#inc-2847-db-pool - We auto-invite on-call engineer and service owners
- Type
/inc severity highto set priority - We capture every action in timeline automatically
- Status page updates when incident state changes
- Post-mortem generates from captured data after resolution
Users consistently highlight this difference:
"To me incident.io strikes just the right balance between not getting in the way while still providing structure, process and data gathering to incident management." - Verified user review of incident.io
Another reviewer emphasized the ease:
"I've used incident.io in a couple of different settings, and it's proved fantastic in removing friction and allowing teams to just get on with getting things sorted." - Verified user review of incident.io
Splunk observability integration: how incident.io works with your existing monitoring
The most common objection from Splunk shops: "We've invested heavily in Splunk Observability Cloud. Do we have to rip that out?"
No. We're complementary to Splunk Observability, not competitive.
We integrate with Splunk On-Call via webhooks, allowing you to route alerts from your existing Splunk monitoring into our incident management layer. Your observability stays in place. Your alerting logic stays in place. What changes is how you coordinate the response once the alert fires.
The integration flow:
- Splunk Observability detects anomaly
- Alert fires to Splunk On-Call
- Webhook triggers our platform to create dedicated Slack channel
- We manage coordination, communication, and documentation
- Resolution flows back through your existing ticketing
Our migration guide shows how teams run both platforms in parallel during transitions. This parallel-run approach means zero risk: prove the value before committing.
Enterprise security and compliance comparison
Both platforms meet baseline enterprise requirements, but implementation differs.
Our compliance posture:
- SOC 2 Type II certified
- GDPR compliant with formal data retention procedures
- SAML/SCIM for Enterprise plan
- AES-256 encryption at rest
- 99.99% uptime SLA for dashboard
Splunk On-Call's compliance:
- Part of broader Splunk ecosystem security
- Specific certifications require direct sales inquiry
- Enterprise-grade access controls
- Audit logging capabilities
For regulated industries, our documented compliance and transparent certification process simplifies vendor security reviews.
Pricing transparency and total cost of ownership
Splunk On-Call's pricing model
Splunk On-Call pricing is not publicly listed, requiring sales engagement for quotes.
The pricing is typically bundled with Splunk Observability Cloud, which can create savings if you're buying the full suite but adds complexity if you only need incident management.
Our pricing model
We publish transparent pricing:
- Basic: Free for small teams
- Team: $15/user/month + $10/user/month for on-call = $25/user/month (annual)
- Pro: $25/user/month + $20/user/month for on-call = $45/user/month (annual)
- Enterprise: Custom pricing larger teams
For a 100-person engineering team on Pro with on-call, annual cost is $54,000. Our ROI calculator shows that reducing coordination time by 30 minutes per incident across 15 monthly incidents saves 7.5 engineer-hours per month, or $13,500 annually at $150 loaded cost.
The hidden cost of tool sprawl
Splunk On-Call doesn't include status pages, requiring separate Statuspage.io subscriptions. Post-mortems happen in Confluence or Notion. Follow-ups live in Jira. Each integration point is another place for context to slip through the cracks.
We consolidate these functions into a unified platform, reducing the coordination overhead that comes from managing multiple separate tools.
Post-mortem and learning: automation vs. reconstruction
Splunk On-Call's post-incident workflow
Splunk On-Call provides a timeline of incident events and MTTA/MTTR metrics. However, creating the actual post-mortem document requires manually reconstructing what happened from the timeline, Slack messages, memory, and incident call notes.
This manual process means post-mortems often don't happen. Common SRE challenges include this pattern: good intentions undermined by manual processes.
Our automated documentation
We capture your timeline as the incident happens. Every Slack message in the incident channel, every /inc command, every role assignment, every decision. When you type /inc resolve, the post-mortem is substantially complete, including:
- Chronological timeline with timestamps
- Key decisions and who made them
- Transcribed call notes from our AI
- Related service information
- Impacted customers and systems
You spend minutes refining the document, not hours reconstructing from memory. One reviewer confirmed this benefit:
"Huge fan of the usability of the Slack commands and how it's helped us improve our incident management workflows. The AI features really reduce the friction of incident management." - Verified user review of incident.io
The VictorOps legacy: innovation velocity matters
Splunk acquired VictorOps in 2018 for approximately $120 million, positioning the deal as creating a comprehensive "Platform of Engagement" for DevOps teams.
Nearly seven years later, users point to slower innovation compared to modern platforms. Splunk On-Call lacks a public changelog, making it difficult to track feature velocity. Industry analysts reviewing incident management tools in 2025 noted development appears to have "slowed."
Compare this to our product velocity. Customer testimonials highlight that "in the time that it had taken us to get one vendor to respond to our product feedback, incident.io had shipped four features we requested."
For enterprise buyers, product velocity matters because incident management evolves rapidly. ChatOps, AI-assisted investigation, and automated documentation weren't considerations in 2018. In 2025, they're table stakes.
When Splunk On-Call makes sense
Honest assessment: Splunk On-Call isn't wrong for everyone.
Choose Splunk On-Call if:
- You're deeply embedded in the Splunk ecosystem with bundled pricing that includes On-Call at favorable rates
- Your team doesn't use Slack or Microsoft Teams as the central communication hub
- Your incident volume is low (under 5 per month) and coordination overhead isn't material
Choose incident.io if:
- Your team lives in Slack or Microsoft Teams for daily work
- You want to reduce MTTR by eliminating context switching
- You need built-in status pages, AI-assisted investigation, and automated documentation
- You want a vendor with visible product velocity and responsive support
User satisfaction: what the data shows
G2 reviews reveal a meaningful satisfaction gap:
We hold 4.8 out of 5 stars with 170+ reviews on G2
- 167 five-star reviews
- Users praise ease of use, Slack integration, and support quality
- G2 #1 Relationship Index ranking Spring 2024
Splunk On-Call: 4.6 out of 5 stars (50 reviews)
- Generally positive but fewer recent reviews
- Support rated 9.2/10
- Some concerns about complex navigation
A representative review captures the sentiment:
"incident.io is a game-changer for incident response. Its seamless ChatOps integration makes managing incidents fast, collaborative, and intuitive—right from Slack." - Verified user review of incident.io
The verdict: coordination beats alerting
Splunk On-Call is a competent alerting platform with a strong rules engine and reliable paging. For teams that bought it as part of a broader Splunk investment, it provides adequate functionality.
But "adequate" isn't the bar for incident management in 2025. Modern engineering teams need more than a pager. They need a platform that handles the entire incident lifecycle, eliminates tool sprawl, captures institutional knowledge automatically, and reduces cognitive load during high-stress moments.
We deliver this through our Slack-native architecture, which isn't just an integration layer but a fundamental design choice. By meeting engineers where they already work, we disappear into the workflow instead of interrupting it.
The question isn't whether we're "better" than Splunk On-Call in some abstract sense. The question is: what does context switching cost during your incidents? If your team handles 15 incidents monthly, and each requires coordination across multiple tools, the minutes lost compound into substantial productivity drain.
Book a demo to see the Slack-native workflow in action, including AI investigation, automated post-mortems, and the unified platform that eliminates separate status page and documentation tools.
Key terms glossary
Slack-native: An architecture where the primary user interface and workflow are embedded directly in Slack using slash commands and interactive elements, rather than treating Slack as a notification destination.
Context switching tax: The productivity cost incurred when responders must move between multiple tools during an incident, including time lost and cognitive overhead of maintaining mental state across applications.
Escalation policy: A set of rules defining how alerts route through on-call responders, including primary contacts, fallback responders, and timeout thresholds before escalating to the next level.
MTTR (Mean Time To Resolution): The average time from incident detection to resolution, a key metric for measuring incident response efficiency and the impact of process improvements.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

