From Opsgenie to JSM: migration patterns and lessons learned
March 20, 2026 — 17 min read
Updated March 20, 2026
TL;DR: Migrating from Opsgenie to Jira Service Management looks like the safe default because it stays inside the Atlassian ecosystem. But JSM is an ITSM ticketing tool, not a real-time incident response platform, and that mismatch creates serious friction for SRE teams managing 3 AM P1 incidents. The engineers who get the best outcomes treat the Opsgenie sunset as an opportunity to upgrade their whole workflow, not just swap one tool for another. Purpose-built, Slack-native platforms integrate directly with Jira and Confluence while keeping coordination where your team already lives.
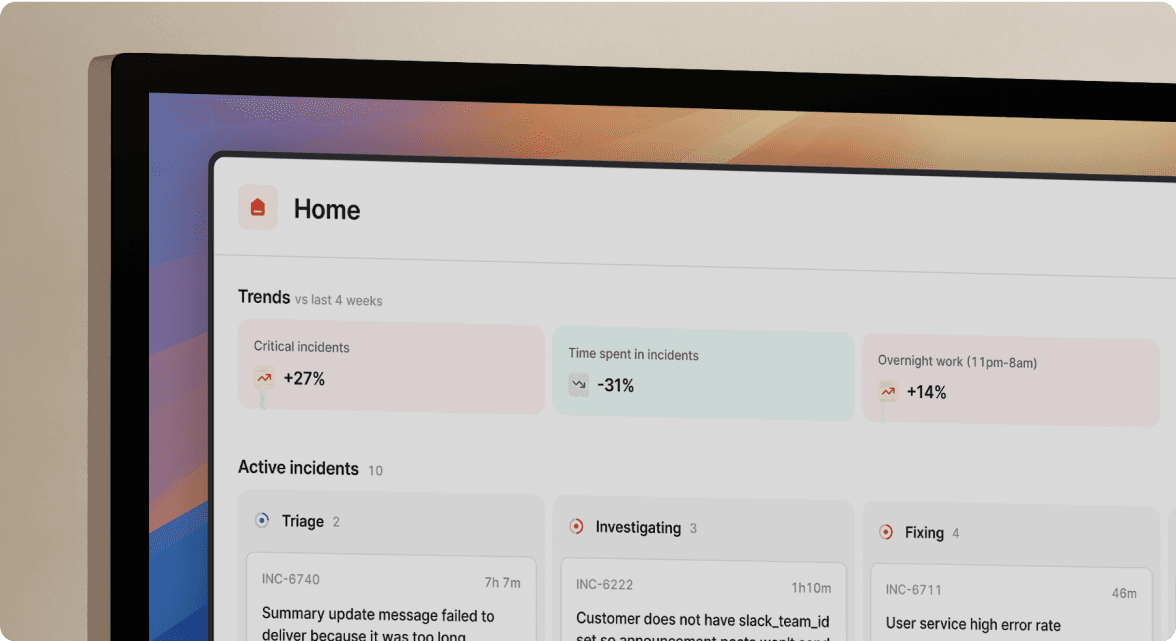
The April 5, 2027 Opsgenie end-of-support deadline is not a distant problem anymore. For many engineering teams running bundled JSM licenses, access ends as early as October 2025. If you're a DevOps Lead or SRE Manager with 50+ on-call schedules and 200+ alert integrations to migrate, you're already behind the comfortable timeline. Every team must migrate. The open question is whether JSM fits your incident response workflow or creates new friction.
Why the Opsgenie sunset is forcing a difficult choice
Atlassian announced a firm end-of-sale date of June 4, 2025 and end-of-support on April 5, 2027, after which Atlassian will delete any unmigrated data. For teams using the JSM-bundled version of Opsgenie, loss of access comes as early as October 2025.
Atlassian's official migration path points to Jira Service Management, which makes sense on the surface. You already pay for Atlassian products, the migration tooling exists, and JSM covers on-call scheduling, alerting, and incident swarming on its Premium plan. The path of least resistance is to follow Atlassian's recommendation and call it done.
But the engineers doing this migration are discovering a fundamental mismatch. Opsgenie focused exclusively on real-time alerting and on-call coordination. Atlassian built JSM for IT service management, specifically request, incident, problem, change, and configuration management across IT, HR, facilities, and finance. That breadth is JSM's strength in an enterprise service context. For a 150-person SaaS company where your SRE team lives in Slack and resolves P1 incidents fast, that breadth creates drag.
The Opsgenie sunset is not just a forced migration. It's a forcing function to decide what kind of incident response capability you actually want for the next three years.
The reality of migrating from Opsgenie to Jira Service Management
The mechanics of an Opsgenie-to-JSM migration are more complicated than Atlassian's documentation suggests. The official migration guide uses a phased approach, but it surfaces a manual configuration step that catches most teams off guard: before you can complete the migration, an admin must intervene to handle deprecated features and incompatible configurations.
Data mapping and integration challenges
Not everything in Opsgenie maps cleanly to JSM. Several configurations require manual recreation after migration. The official deprecations list includes:
- Team-level details: Activity Streams and Conferences are deprecated with no direct equivalent.
- Notification policies: In JSM, notification policies are scoped to the operations/team level only, while alert policies support both global and team-based scope, but the migration from Opsgenie requires manual conversion. Any global policies you configured in Opsgenie must be converted manually before the Opsgenie shutdown or they won't carry forward.
- Groups: JSM replaces Groups with Teams. Your group-based routing rules require manual remapping.
- Custom roles: Opsgenie custom roles that don't match JSM's role model need manual reassignment, and some Opsgenie admins may not automatically receive the product admin role in JSM.
- Asset data: According to Atlassian's own knowledge base, there is no automated way to migrate Assets data from Datacenter or Server versions to cloud. You must create references, statuses, roles, attachments, and links between Jira fields and Assets objects manually.
For a team with 200+ alert integrations, each of these represents hours of manual work that doesn't appear in migration timelines built on optimistic estimates. The ITSM and DevOps integration guide covers how to map these workflows accurately before you start.
The JSM migration trap: ticketing vs. real-time response
The deepest challenge is not technical. It's structural. JSM uses a ticketing-first model, which creates friction during real-time incidents. Atlassian also points to Compass as a complementary layer, but Compass is a developer portal, not an incident orchestration layer. It won't alert the right person, create timelines, or escalate across teams.
The practical result during a P1 incident looks like this:
- Alert fires and creates a JSM ticket.
- On-call engineer opens JSM in a browser tab to read the ticket.
- Coordination moves to Slack manually because that's where the team is.
- Someone updates the JSM ticket separately to satisfy the audit trail.
- Post-mortem reconstruction happens after the fact because JSM captured the ticket state, not the Slack conversation where the actual work happened.
Every minute you spend switching between Slack and JSM during a critical incident is cognitive overhead that extends MTTR. Coordination overhead from tool sprawl during incidents adds significant time to incident response. For teams handling 15 incidents per month at a $150 loaded hourly cost per engineer, even 15 minutes of coordination overhead per incident would represent roughly $1,700–$2,250 in monthly coordination costs for a team averaging 3–4 responders per incident.
Aggregated migration patterns: what engineering teams actually encounter
Based on migration patterns from incident.io customer data, engineering teams migrating from Opsgenie to JSM typically manage multiple on-call schedules and hundreds of alert integrations across monitoring tools. Most teams initially evaluate JSM because it appears to be the safe option inside their existing Atlassian contract. The migration consistently reveals the same friction points.
Pre-migration planning and prerequisites
Before starting any Opsgenie migration, a thorough audit is non-negotiable. The pre-migration checklist covers:
- Audit all on-call schedules: Document every rotation, including coverage gaps, override rules, and escalation paths.
- Map alert integrations: Catalog every source (Datadog, Prometheus, GitHub, custom webhooks) and document the routing logic for each.
- Identify deprecated features: Flag anything requiring manual recreation before migration starts.
- Set up parallel run infrastructure: Both systems receive the same alerts for a minimum of two weeks before cutover.
- Define validation criteria: Zero missed pages and 100% alert delivery continuity during the parallel run before proceeding.
The tools for migrating from Opsgenie provide automation for the schedule and integration export steps, which compresses this from weeks to days.
Execution, pitfalls, and post-migration validation
Teams consistently hit three risks during cutover:
- Notification policy gaps: The team failed to convert global notification policies before completing the migration. Alerts routed to deprecated groups and paged nobody during the validation window. Converting all notification policies before migration starts prevents this.
- Engineer confusion during live incidents: The first real P1 after cutover had engineers opening JSM in a browser while simultaneously coordinating in Slack. Nobody updated the JSM ticket in real time because coordination stayed in Slack.
- Post-mortem disconnect: The JSM ticket recorded timestamps for state changes but missed the Slack thread where the team identified the actual root cause, the rollback decision, and the communications to customer success. Post-mortem reconstruction still required significant manual effort.
The key validation step most teams skip: measure coordination time separately from technical resolution time. If MTTR isn't improving 30 days post-migration, check whether technical fix time improved while coordination overhead stayed flat or got worse.
Opsgenie vs. JSM: Feature and workflow comparison
| Capability | Opsgenie (legacy) | JSM Premium | incident.io Pro |
|---|---|---|---|
| Primary interface | Dedicated web app + mobile | Browser/JSM ticket view | Slack-native via /inc commands |
| On-call scheduling | Advanced rotations, escalations | Included on Premium plan | Full scheduling included in Pro |
| Alert routing | Rules-based, global policies | Team-based, grouping and dedup | Routes by team, service, or custom attribute |
| Real-time coordination | Manual Slack channel creation | Manual Slack hand-off required | Auto-creates Slack channel on alert |
| Timeline capture | Manual | JSM ticket state changes only | Auto-captures Slack actions and decisions |
| Post-mortem automation | None | Manual templates | AI drafts 80% of post-mortem from captured timeline |
| Jira integration | Separate tool | Native (same platform) | Follow-ups auto-create Jira tickets, syncing status back to incident.io |
| Pricing (with on-call) | See Atlassian pricing | ~$51/agent/month on Premium | $45/user/month ($25 Pro + $20 on-call add-on) |
JSM is the right tool if your primary need is enterprise service management across IT, HR, and facilities and your incident response volume is low. For SRE teams handling 5-20+ incidents per month where Slack is the operational center of gravity, the workflow mismatch carries a measurable cost.
Why engineering teams are choosing purpose-built alternatives
The Opsgenie sunset is pushing teams to ask a better question than "where does Atlassian want us to go?" The real question is what your team actually needs to resolve incidents faster.
For most SRE and DevOps teams, the answer is a tool that lives where they already work. The coordination tax of switching between Opsgenie, Slack, Datadog, and Google Docs often exceeds the actual technical resolution time. Slack-native incident management can reduce MTTR by up to 80%.
Keeping incident response Slack-native
The workflow difference is concrete. A Datadog alert fires at 2:47 AM. With incident.io, the sequence looks like this:
- Alert fires in Datadog.
- incident.io auto-creates a dedicated incident channel in Slack.
- On-call engineer gets paged and joins the channel.
- Service owner is automatically pulled in based on the service catalog.
- Timeline starts capturing automatically: role assignments, severity updates, and key decisions logged without a dedicated note-taker.
No browser tabs. No manual channel setup. No copying alert links into Slack.
"incident.io brings calm to chaos... Incident.io [sic] is now the backbone of our response, making communication easier, the delegation of roles and responsibilities extremely clear, and follow-ups accounted for." - Braedon G. on G2
The 5 best Slack-native incident management platforms guide covers how each approach handles the coordination layer in detail.
Automating post-mortems and timeline capture
The post-mortem gap between JSM and purpose-built tools is most visible after an incident closes. JSM captures ticket state changes. incident.io captures the full incident record: every Slack message pinned to the timeline, every role assignment, every severity change, and every verbal decision captured via the Scribe transcription feature on incident calls.
When the incident closes, the AI SRE assistant uses that captured timeline to generate a draft post-mortem covering the incident summary, timeline of events, contributing factors, and suggested action items. That automation covers up to 80% of incident response work, as detailed in incident.io's 5 critical features guide.
"1-click post-mortem reports - this is a killer feature, time saving, that helps a lot to have relevant conversations around incidents (instead of spending time curating a timeline)" - Adrian M. on G2
The automated post-mortems comparison and the post-mortem problem break down exactly where manual reconstruction wastes the most time.
How incident.io integrates with your Atlassian stack
The most common objection to moving outside the Atlassian ecosystem is: "We want to keep Jira." That's the right instinct, and incident.io doesn't ask you to abandon it.
The Jira sync integration works like this: when you declare an incident in incident.io, it automatically creates a corresponding Jira ticket and updates that ticket as the incident evolves. Follow-up actions assigned during the incident automatically export to Jira with the proper project, assignee, and metadata attached. When the Jira ticket status changes, incident.io reflects that update on the follow-up. Here's a concrete example of the workflow: an engineer types /inc resolve in Slack, incident.io marks the incident closed, the follow-up action "Increase database connection pool" automatically creates a Jira ticket, and your platform team sees it in their sprint board.
The Confluence integration is available through the Atlassian Marketplace, allowing post-mortems to publish directly to Confluence pages. Your runbooks stay in Confluence. Your follow-up work flows into Jira. Your incident response stays in Slack.
Think of it this way: incident.io is not replacing your Atlassian tools. It feeds them better data by capturing what actually happened during the incident, not just the ticket state changes.
Your Opsgenie migration checklist
Use this checklist regardless of which tool you migrate to. Skipping any of these steps is the fastest path to a missed page during a production incident.
- Audit all on-call schedules and document escalation paths
- Catalog every alert integration with its source, routing rule, and owning team
- Identify deprecated Opsgenie features that require manual recreation using the official deprecations list
- Convert all global notification policies to team-level policies before migration starts
- Document custom roles and map them to the target tool's role model
- Configure both systems to receive identical alerts during a parallel run of at least two weeks
- Validate routing: confirm every alert reaches the correct on-call engineer in both systems
- Run at least two simulated incidents end-to-end in the new system before live cutover
- Define cutover criteria: zero missed pages and 100% alert delivery continuity
- Freeze configuration changes for one hour during the cutover window
- Swap webhooks and monitor the first 24 hours closely
- Measure MTTR at 30 days post-migration against your pre-migration baseline
The incident.io Opsgenie migration tools automate the schedule export and integration transfer steps, reducing the manual work in the first two weeks significantly.
If you're evaluating incident.io as your Opsgenie replacement, schedule a demo and we'll walk through a full incident lifecycle in Slack, from Datadog alert to published post-mortem.
Key terms glossary
MTTR (Mean Time To Resolution): The average time from incident detection to full resolution. Purpose-built incident management tools can help teams reduce MTTR by up to 80% by eliminating coordination overhead.
Ticketing-coordination mismatch: The friction that occurs when a team's real-time coordination happens in Slack while the incident record lives in a separate ticketing system, fragmenting the audit trail.
Slack-native incident management: An incident response workflow where incidents are declared, coordinated, escalated, and documented entirely within Slack using /inc commands, without requiring engineers to switch to a browser-based UI during an active incident.
Parallel run: A migration strategy where the legacy system (Opsgenie) and the new system run simultaneously for 2-4 weeks, both receiving identical alerts, letting teams validate the new system's reliability before full cutover.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

