Best incident postmortem software for enterprise teams (2026 guide)
February 5, 2026 — 22 min read
Updated February 5, 2026
TL;DR: The best enterprise postmortem software captures incident data automatically during response, not after. Manual timeline reconstruction wastes 60-90 minutes per incident and creates incomplete reports. Look for platforms combining real-time data capture, AI-powered drafting, and security features like SOC 2, SAML/SCIM, and private incidents. We reduce postmortem effort by approximately 80% by capturing timelines, decisions, and debug data where work already happens in Slack or Teams, while meeting compliance requirements for enterprise deployments.
Your team just resolved a major database incident at 2 AM. Three days later, you're staring at a blank Confluence page trying to reconstruct what happened from 200+ Slack messages across four channels, PagerDuty alert history, and half-remembered Zoom conversations. You spend 90 minutes piecing together who did what and when, but the critical decision about why the team rolled back instead of scaling remains lost. This timeline archaeology is the hidden tax of manual incident management.
Your team wastes 12-15 minutes per incident just assembling people by manually creating Slack channels, hunting for who's on-call in a Google Sheet, and pinging database engineers who are asleep. Then you spend another 60-90 minutes after resolution reconstructing the timeline from scattered sources. At $88/hour for senior engineers, coordination and documentation logistics consume $1,912 to $3,187 monthly before any actual learning happens.
The best postmortem software eliminates the reconstruction problem entirely by capturing data automatically during incidents.
Why enterprise post-mortems fail (and how software fixes it)
The archaeology tax
The hardest part of post-mortems isn't writing them, it's remembering what happened three days later when memory has faded. Engineers make dozens of micro-decisions during high-stress incidents. "Let's try scaling the pods first" seems obvious at 2 AM but vanishes by morning.
Critical decisions made in DMs or verbal calls often go undocumented, vanishing from institutional memory. The incident commander's rationale for choosing rollback over hotfix, discussed in a quick Slack huddle, never makes it into the timeline. Three months later when similar incidents occur, teams repeat the same debugging paths.
"Without incident.io our incident response culture would be caustic, and our process would be chaos. It empowers anybody to raise an incident and helps us quickly coordinate any response across technical, operational and support teams." - Matt B. on G2
The compliance gap
Enterprise security audits require complete, immutable timelines. Auditors want to see who accessed what data, when decisions were made, and what actions were taken for SOC 2 compliance. Manual Google Docs fail this test because you can edit them retroactively, timestamps are unreliable, and there's no audit trail showing who changed what.
GDPR compliance demands formal data retention procedures for incidents involving customer data. Copy-pasting from Slack into Confluence creates multiple copies of potentially sensitive data across systems with different retention policies, creating audit exposure and regulatory risk.
Financial services and healthcare organizations need role-based access control for sensitive incidents like data breaches or security vulnerabilities where only specific teams should see details.
The multi-team coordination problem
Enterprise incidents span teams. Database connection pool exhaustion involves SRE (initial response), database team (root cause), platform team (configuration), and product team (feature flag rollback). Each team works in different Slack channels, uses different monitoring dashboards, and documents work in different Jira projects.
When postmortems shift from allocating blame to investigating systematic reasons why teams had incomplete information, effective prevention plans emerge. But you can't investigate systematic failures when data lives in six tools across four teams.
Key features to look for in enterprise postmortem tools
Automated timeline reconstruction
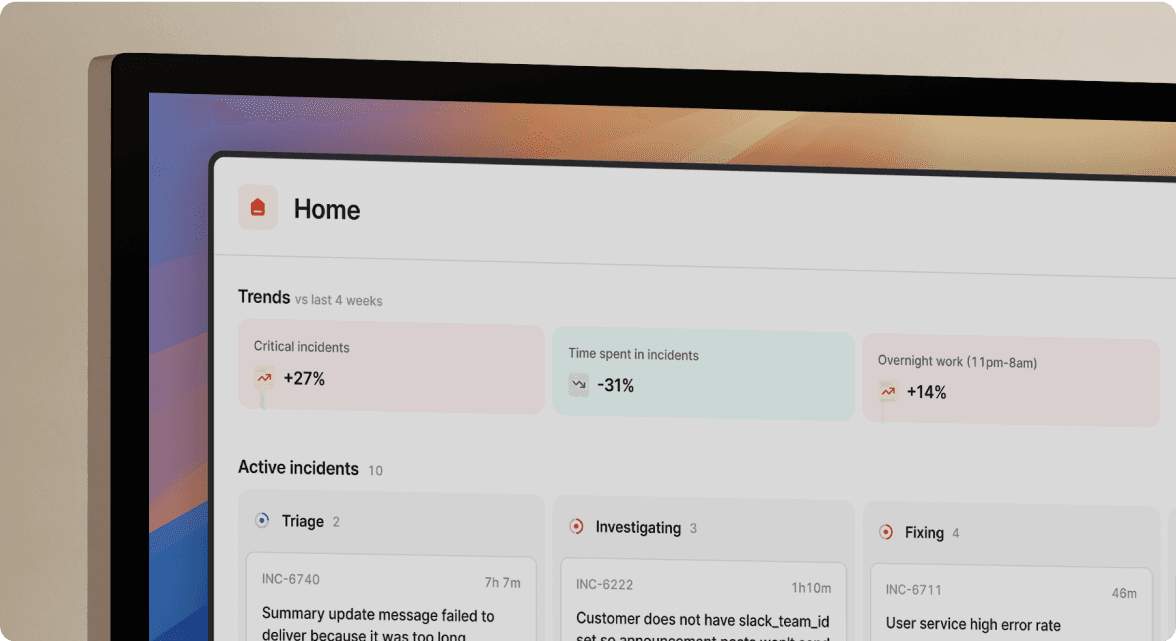
We capture chat logs, graph snapshots, and decisions in real-time without requiring a designated note-taker. When you run an incident using /inc commands, every action auto-populates the timeline: role assignments, severity changes, Slack threads, and shared links including triggering alerts and runbook links from your service catalog.
Real-time transcription captures decisions even if they turn out wrong. When someone says "I think this correlates with the 2:30 AM deployment," that hypothesis gets captured. Three weeks later when reviewing patterns, you'll see the team initially suspected deployments but the real culprit was a configuration change.
Context preservation matters. Simply using the pin emoji on a Slack message, screenshot, or graph automatically adds it to the incident timeline. Engineers don't switch contexts or learn new tools.
AI-powered analysis and drafting
Our AI summarizes events, suggests root causes, and drafts the initial report automatically, not just correlates logs. We generate post-mortem drafts from captured timelines that include incident summary, timeline of events, contributing factors, and suggested action items. You spend 10-15 minutes reviewing and refining instead of 90 minutes writing from scratch.
Our AI SRE represents current state-of-the-art for autonomous incident investigation because it analyzes logs, metrics, and traces from your observability stack and connects telemetry with code changes and past incidents to surface root causes without manual prompting.
You can interact with our AI directly inside the post-mortem editor to ask questions about the incident and quickly surface relevant context. It understands incident timelines, participants, and metadata, helping you extract key details without leaving the document.
"Incident.io does everything for incident management, from the moment you receive an alert to the moment you close a post-mortem. They always come up with solutions you didn't know you needed." - Pablo P. on G2
Compare this to competitors. FireHydrant's AI Copilot drafts answers to retrospective questions based on gathered context, but emphasizes structured data collection rather than real-time narrative generation. Rootly offers AI-generated incident titles and real-time summarization but with less depth than autonomous investigation.
Security and governance for enterprise scale
We maintain certification with complete, immutable audit trails showing who accessed incidents, what changes were made, and when actions occurred. During incident reviews, audit logs show exactly when teams joined and what information they had at decision points.
Organizations can mark incidents as sensitive and restrict access to specific teams or roles. When responding to data breaches or security vulnerabilities, the entire engineering org doesn't see sensitive customer data or unpatched vulnerability details in incident channels.
Organizations on Enterprise and newer Pro plans can enable SSO using SAML to manage access via an Identity Provider like Okta. SCIM is available to customers on our Enterprise plan and complements SAML authentication by adding automatic provisioning, deprovisioning, and authorization control.
We support granular permission models. You can assign Incident Managers the Admin role and give IT teams a custom role with only "Can manage security settings" permission. SREs manage incidents without accidentally changing SAML configuration, and security teams audit access without seeing every production incident.
Deep integrations with your existing stack
Enterprise teams can't replace their entire stack overnight. We integrate deeply with Jira for task tracking, ServiceNow for enterprise service management, and monitoring tools like Datadog.
Our webhooks send real-time notifications to external systems so closing an incident in incident.io updates the corresponding Jira ticket automatically. For inbound data, our API enables pulling information from external tools into incident timelines, creating a comprehensive integration ecosystem beyond simple notifications.
Watch for competitors whose "integrations" just send Slack notifications. PagerDuty's postmortem feature offers the ability to include Slack discussions by connecting to your Slack account and selecting channels, but requires manual channel selection and data gathering rather than automatic real-time capture.
"The platform's compatibility with multiple external tools makes it an excellent central hub for managing incidents. Another handy feature is its ability to automate routine actions, such as postmortem reports generation." - Vadym C. on G2
Top incident postmortem software for enterprise teams
incident.io: Best for automated, Slack-native workflows
Best for: Enterprise teams wanting zero-friction adoption with automated timeline capture and AI-powered postmortem drafting.
We built the entire postmortem workflow inside Slack and Teams with automatic timeline capture. When Datadog alerts fire, we auto-create dedicated incident channels, pull in on-call responders, and start capturing timelines without anyone opening a web browser. Engineers type /inc summary "API latency spike" and /inc severity high as natural Slack messages.
Our AI SRE can automate up to 80% of incident response by analyzing logs, metrics, and traces from observability stacks and surfacing root causes without manual prompting. Within 10 seconds, you get a complete post-mortem draft. Engineers spend 10-15 minutes refining instead of 90 minutes writing from scratch.
Enterprise security: We maintain SOC 2 certification with GDPR compliance and offer SAML on Enterprise and Pro plans, with SCIM available on Enterprise. Private incidents with granular access controls let security teams restrict breach response visibility to specific roles.
Pricing: Pro plan runs $45/user/month for full capabilities including unlimited workflows, custom fields, on-call schedules, Microsoft Teams support, and AI-powered post-mortem generation. Enterprise adds SAML/SCIM, dedicated Customer Success Manager, and sandbox environment at custom pricing.
"Incident has transformed our incident response to be calm and deliberate. It also ensures that we do proper post-mortems and complete our repair items." - Mike H. on G2
PagerDuty: Best for alerting-first incident management
Best for: Enterprise teams heavily invested in PagerDuty's ecosystem who need battle-tested alerting with basic postmortem capabilities.
PagerDuty dominates alerting with sophisticated routing, escalation policies, and 200+ monitoring integrations. Postmortems curate timelines of activity in PagerDuty and Slack for analysis, and AI can summarize incidents after resolution for post-incident reviews. However, building comprehensive timelines requires connecting to Slack to search and select channels to include rather than automatic real-time capture.
Enterprise security: PagerDuty maintains SOC 2 certification with SAML/SCIM support for enterprise customers. Strong compliance posture given established market position and enterprise customer base.
Pricing: Per-seat pricing escalates with add-ons for noise reduction, AI features, and runbooks. No public pricing requires "contact sales" conversations.
Trade-offs: Maximum alerting flexibility comes at complexity cost. Web-first UI requires extensive training compared to chat-native alternatives.
Jira Service Management: Best for Atlassian-committed shops
Best for: Organizations standardized on Atlassian tools who need basic incident management without adding vendors.
JSM tracks every incident as a Jira issue with followup issues for postmortems and uses Confluence for documentation. The platform automatically creates postmortem reports with incident timelines, but automation is limited to what exists within JSM itself.
The fundamental limitation is three-tool coordination. Chat room in Slack, Confluence page for incident state, and Jira tracking creates the exact tool sprawl postmortem software should eliminate. For every postmortem action, teams must raise Jira work items manually.
Migration context: Atlassian announced Opsgenie sunset in April 2027, forcing customers to migrate. Our Opsgenie migration tools help teams evaluate alternatives.
Best use case: Organizations with existing Atlassian Enterprise agreements where adding vendors creates procurement complexity.
FireHydrant: Best for service catalog-centric workflows
Best for: Platform teams building comprehensive service catalogs who want incidents automatically associated with service ownership.
FireHydrant emphasizes service catalog as the foundation. When incidents occur, the platform automatically pulls service owners, dependencies, and recent deployments from the catalog. AI Copilot uses incident data to answer questions within retrospectives, reducing manual lookup time.
AI-powered voice transcription for Zoom and Google Meet provides real-time transcription and automatic key point summarization. Differentiation comes down to service catalog depth versus autonomous AI investigation.
Rootly: Best for Slack-native incident coordination at smaller scale
Best for: Teams wanting Slack-first incident management with AI-assisted summaries without enterprise complexity.
Rootly offers AI-generated incident titles from alert payloads and real-time incident summarization so new responders get up to speed quickly. The "Ask Rootly AI" feature uses conversational prompts for troubleshooting suggestions.
Rootly offers Slack-native incident management similar to incident.io but with less feature depth in AI capabilities and voice transcription.
Best fit: Growing startups (50-200 engineers) wanting modern Slack-native workflows without enterprise complexity.
"The customization of incident.io is fantastic. It allows us to refine our process as we learn by adding custom fields, severity types or workflows to tailor the tool to our exact needs." - Nathael A. on G2
Comparing the top solutions
| Capability | incident.io | PagerDuty | JSM/Atlassian | FireHydrant |
|---|---|---|---|---|
| Real-time timeline capture | Automatic from Slack/Teams | Manual channel selection | Separate Confluence docs | Automated from catalog |
| AI postmortem drafting | ~80% automation, 10-15 min refinement | AI summarization available | Template-based only | AI-assisted answers |
| Autonomous investigation | Proactive root cause analysis | Manual investigation | Manual investigation | Structured data collection |
| SOC 2 compliance | Certified | Certified | Certified | Contact vendor to confirm |
| SAML/SCIM | SAML on Enterprise + Pro; SCIM on Enterprise | Enterprise tier | All enterprise products | Enterprise tier |
| Private incidents | Granular RBAC | Role-based access | Jira permissions only | Limited documentation |
| Time to operational | 1-2 days | 2-8 weeks | 1-4 weeks | 2-3 weeks |
| Pricing transparency | Public pricing | Contact sales | Complex bundling | Limited public info |
| Native chat integration | Built for Slack/Teams | Web-first with notifications | Separate chat tool | Slack-native options |
How to calculate ROI for postmortem software
The time savings formula
Start with credible hourly cost data. Senior DevOps Engineer salaries average $85 per hour with typical ranges from $145,246 to $220,286 annually. Use the conservative mid-range rate for ROI calculations.
Manual reconstruction wastes 60-90 minutes per incident compared to 10-15 minutes reviewing AI-generated drafts. This represents approximately 60-75 minutes saved per incident.
Time value calculation for 100-user deployment handling 15 incidents monthly:
Direct time savings: 15 incidents/month × 1 hour saved × $85/hour × 12 months = $15,300/year in reclaimed engineering time
Additional value factors:
- Reduced repeat incidents: Complete postmortem archives help identify patterns. Preventing even one major incident quarterly (4 hours MTTR, 6 engineers) saves 24 hours = $2,040 quarterly or $8,160 annually
- Faster on-call onboarding: Clear timelines and role definitions visible in past incidents reduce onboarding time for new engineers joining rotation, conservatively worth $5,000-8,000 annually for teams adding engineers to on-call rotation
Total annual value: $28,460-31,460
Total cost comparison
Current state (manual process):
- PagerDuty alerting: $41/user/month × 100 = $49,200/year
- Statuspage: $399/month = $4,788/year
- Confluence allocation: ~$3,000/year
- Engineer time: 15 incidents × 1.5 hours × $85 = $1,912/month = $22,950/year
- Total: $79,938/year
Future state (incident.io Pro):
- incident.io Pro with on-call: $45/user/month × 100 = $54,000/year
- Engineer time: 15 incidents × 0.25 hours × $85 = $319/month = $3,825/year
- Total: $57,825/year
Net annual savings: $22,113 plus additional value from prevented incidents and faster onboarding creates total value realization of $35,273-38,273 annually.
Implementation efficiency
incident.io requires 1-2 days for full setup with opinionated defaults getting teams operational quickly. PagerDuty implementations typically require 2-8 weeks with configuration complexity and training sessions. This represents immediate value before considering ongoing operational savings.
"It was a really game-changing product during and after the incidents. Before incident.io we were always struggling to collect important information about the incidents." - Tiago C. on G2
Choosing the right tool for your scale
Decision framework for enterprise teams
- Choose incident.io if you prioritize automation over customization, want deployment in days not months, and need Slack/Teams-native workflows. Our AI SRE's autonomous investigation and real-time call transcription eliminate manual data capture. Best for teams handling 10-30 incidents monthly where postmortem speed impacts learning velocity.
- Choose PagerDuty if you have deep investment in their alerting ecosystem with complex routing rules refined over years. Accept that postmortem functionality requires more manual effort for timeline building. Best where alerting sophistication trumps postmortem efficiency.
- Choose JSM if your enterprise is standardized on Atlassian tools with existing agreements. Accept three-tool coordination (Slack, Jira, Confluence) and manual action item tracking. Best for IT service management teams extending Atlassian footprint.
- Choose FireHydrant if service catalog maturity is your primary focus and you want incidents automatically contextualized with ownership and dependencies. Best for platform engineering teams treating service catalog as foundational infrastructure.
Scale considerations
50-200 engineers: Prioritize ease of adoption and time-to-value. Slack-native workflows require minimal training because engineers already know how to use chat. Avoid platforms requiring 6-week implementations with professional services.
200-500 engineers: Security and compliance features become mandatory. SAML/SCIM, private incidents, and SOC 2 certification aren't optional. Multi-team coordination complexity demands automated timeline capture across departments.
500+ engineers: Enterprise features like sandbox environments, dedicated CSMs, advanced RBAC, and multiple status pages become critical. Look for platforms with Fortune 500 customer logos proving they can handle enterprise scale and security requirements.
Book a demo to watch our AI draft a complete postmortem in 10 seconds from captured timeline data, and run your first incident through our platform and experience Slack-native workflows firsthand.
Key terminology
MTTR (Mean Time To Resolution): The average time from incident detection through recovery and verification. Enterprise teams target sub-30 minute MTTR for P1 incidents with automated coordination reducing assembly time from 15 minutes to under 3 minutes.
Root Cause Analysis (RCA): Systematic method to identify primary causes of problems by collecting and examining relevant data rather than addressing symptoms. Distinguishes between immediate triggers and underlying systematic failures requiring process improvements.
SOC 2: Compliance standard for managing customer data requiring documented controls, audit trails, and security policies. Type II certification demonstrates controls operated effectively over time, essential for enterprise software handling sensitive incident data.
ChatOps: Managing operations and incident response directly in chat applications like Slack using slash commands instead of separate web UIs. Connects people, tools, process, and automation in a transparent workflow.
Blameless culture: Environment where mistakes are seen as opportunities to strengthen systems rather than reasons to punish individuals. Originated in healthcare and aerospace where learning from failure is critical for safety, enabling psychological safety for transparent incident discussion.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

