Best incident postmortem software for DevOps teams: 2026 guide
February 5, 2026 — 24 min read
Updated February 5, 2026
TL;DR: The best postmortem software captures context from your CI/CD pipeline and chat logs in real-time to automate learning, not just document incidents after the fact. incident.io's AI SRE automates up to 80% of incident response through Slack-native workflows, while PagerDuty is migrating its postmortem feature to Jeli Post-Incident Reviews. Modern DevOps teams need tools that integrate with Datadog, GitHub, and Jira to correlate deployments with failures automatically, reducing the 90-minute "archaeology" of reconstructing timelines to about 15 minutes of refinement.
Post-incident analysis consistently ranks as the most time-consuming part of incident management. Engineering teams spend 60-120 minutes reconstructing what happened from scattered Slack threads, Datadog timestamps that don't align with PagerDuty alerts, and fading memories of who made which decision during the response.
The reconstruction problem compounds with modern micro-services architectures. When a database connection pool exhausts itself and API latency spikes, you need software that automatically correlates the deployment timeline with monitoring alerts and captures the incident response in real-time. Manual postmortems written three days later miss critical context about why the team chose rollback over scaling.
You don't need a better text editor for your retrospectives. You need a platform that connects your CI/CD pipeline, monitoring, and communication tools to write the timeline for you. This guide compares the top postmortem software specifically for DevOps teams, focusing on automation, integration depth, and time-to-value.
Why DevOps teams need specialized postmortem software
Generic documentation tools like Google Docs or Confluence force you to manually reconstruct incident timelines from memory, which is why postmortems take 60-120 minutes to write and teams publish them 3-5 days late when details have faded. Specialized postmortem software captures incident data in real-time as your team responds, reducing manual reconstruction time by 70-90%.
Understanding the difference between process and tools matters here. Teams practice blameless postmortems (learning from failures without assigning blame) separately from choosing the tools that enable them. Google's SRE book defines blameless culture as shifting from allocating blame to investigating systematic reasons why individuals had incomplete information. You can't fix people, but you can fix systems and processes. The right tooling makes that cultural shift sustainable by removing friction.
Modern DevOps stacks running Kubernetes and micro-services generate too much data for manual correlation. When a deployment fails, you need software that automatically links the specific GitHub commit, the Datadog alert showing memory exhaustion, the Slack thread where someone suggested rollback, and the PagerDuty escalation to the database team. Doing this manually with screenshots and copy-paste creates incomplete records.
DevOps postmortems specifically focus on the intersection of code deployment, infrastructure, and operations, which requires deeper CI/CD integration than general incident management tools provide. According to research on SRE practices, reducing toil (manual, repetitive, automatable work that scales linearly as services grow) is a core reliability principle. Manual postmortem reconstruction is pure toil.
Key features to look for in postmortem tools
Integration depth with your existing stack
Your postmortem tool must connect with Datadog, Prometheus, or New Relic for monitoring data, PagerDuty or Opsgenie for alerting context, Jira or Linear for follow-up task tracking, and GitHub or GitLab for deployment correlation. Surface-level integrations that just send notifications aren't enough.
"everything is centralized in incident.io, simplifying incident response significantly" - Alex N. on G2
This centralization eliminates the context-switching tax between five different browser tabs during critical incidents.
Automation that captures timelines in real-time
Auto-drafting timelines from chat logs (Slack or Microsoft Teams) is table stakes. The platform should capture every role assignment, severity change, status update, and Slack thread without requiring a designated note-taker. incident.io's Scribe feature transcribes incident calls via Zoom or Google Meet, extracting key decisions like "rolled back deploy #4872" without pulling an engineer away from troubleshooting.
The difference between manual and automated capture is dramatic. Teams report reducing postmortem completion time from 90 minutes of reconstruction to 15 minutes of editing an AI-generated draft, which is an 83% time savings.
AI capabilities that go beyond log correlation
AI should analyze patterns across logs, metrics, code changes, and historical incidents to suggest root causes, not just dump raw data. incident.io's AI SRE automates up to 80% of incident response by identifying the likely change behind incidents and suggesting next steps based on past similar incidents. This is fundamentally different from competitors adding "AI features" as marketing buzzwords.
The AI-powered post-incident management approach uses machine learning to recognize patterns like "API latency incidents between 2-4 AM correlate with nightly batch jobs exhausting connection pools," which helps prevent future occurrences rather than just documenting the current one.
Ease of adoption measured in days, not months
You should be operational within 2-5 days, not quarters. incident.io can be installed in 30 seconds and handle your first real incident on day 3 of a trial. Complex platforms requiring six-week implementations with professional services and change management workshops create adoption friction that delays value.
"incident.io is extremely easy to use... allowing users with little training to manage incidents like pros" - Roro O. on G2
This means new on-call engineers can participate effectively in their first incident without extensive training.
Security and compliance for enterprise buyers
SOC 2 Type II compliance is non-negotiable. Your CISO will block any purchase without proper data encryption (AES-256 at rest), GDPR compliance, and SAML/SCIM support for enterprise access controls. incident.io maintains SOC 2 Type II certification with formal data retention procedures.
Top incident postmortem software for DevOps teams
The postmortem software landscape has shifted dramatically. PagerDuty is migrating to Jeli Post-Incident Reviews, Opsgenie is shutting down completely, and modern Slack-native platforms have emerged as the new standard for DevOps workflows. Here's how the leading tools compare for teams running Kubernetes, micro-services, and cloud-native infrastructure.
incident.io
Best for: Teams wanting a unified, Slack-native workflow that eliminates tool sprawl and automates the majority of postmortem drafting through AI.
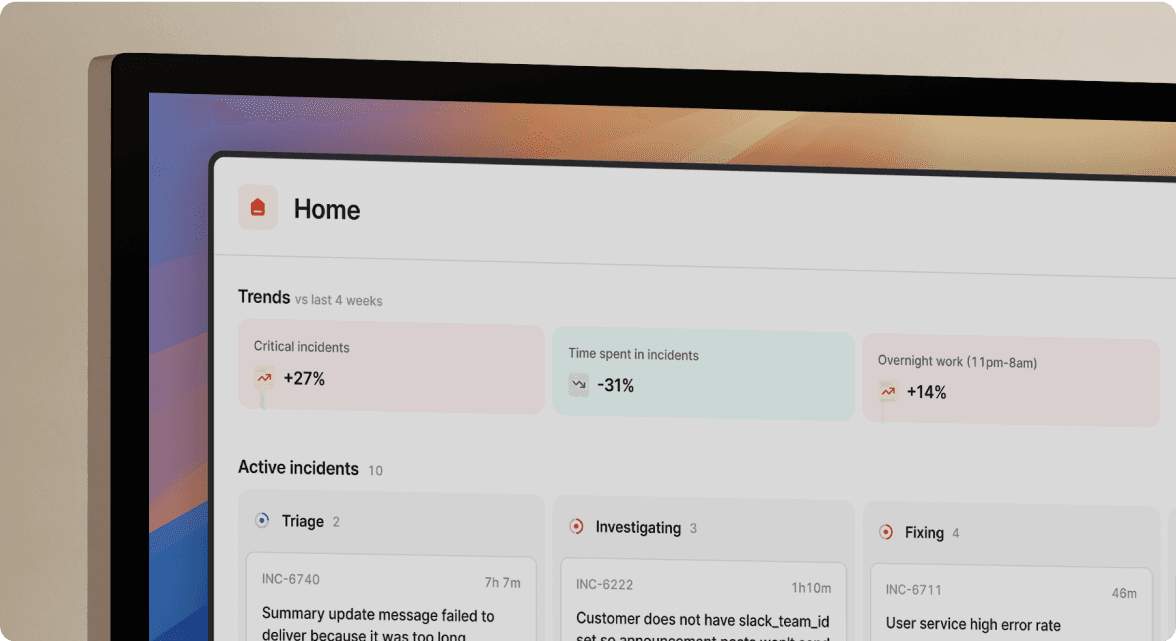
incident.io brings the entire incident lifecycle into Slack, where your team already works during incidents. When a Datadog alert fires, the platform automatically creates a dedicated incident channel, pulls in on-call responders based on service ownership, and starts capturing a timeline in real-time. Every /inc escalate, /inc assign, and status update command auto-populates the postmortem draft.
The Scribe feature records and transcribes incident calls, capturing decisions made verbally without requiring someone to take notes manually. When you type /inc resolve, the system generates the postmortem draft within 10 seconds, including incident summary, full timeline with timestamps, transcribed call highlights, and suggested follow-up actions. You spend 10-15 minutes refining context, not 90 minutes reconstructing events from memory.
For DevOps teams specifically, incident.io excels at CI/CD pipeline failure postmortems. The platform pulls the problematic GitHub PR, recent deployments, and relevant past incidents directly into the incident channel, so the investigation uncovers connections between code changes and production failures automatically.
Pricing:
- Team plan: $19/user/month with on-call add-on at +$12/user/month = $31/user/month total
- Pro plan: $25/user/month with on-call at +$20/user/month = $45/user/month total (includes AI postmortems, Teams support, custom incident types)
- Enterprise: Custom pricing with SAML/SCIM, dedicated CSM, sandbox environments
Compare full pricing details.
"incident.io saves us hours per incident when considering the need for us to write up the incident, root cause and actions, communicate it to wider stakeholders and overall reporting" - Pablo P. on G2
PagerDuty
Best for: Enterprise teams deeply invested in the PagerDuty ecosystem who need sophisticated alerting but are aware of significant postmortem limitations.
PagerDuty dominates alerting and on-call scheduling with battle-tested reliability and 200+ integrations, but its postmortem feature is being migrated to Jeli Post-Incident Reviews effective January 30, 2026. While existing postmortems will be automatically converted, the new functionality requires an Enterprise Incident Management plan, representing a fundamental shift in PagerDuty's strategy toward higher-tier offerings.
The core problem with PagerDuty for DevOps postmortems is architectural. The platform focuses on alerting with weak coordination and documentation features. While PagerDuty captures alert data well, it doesn't automatically document coordination happening in Slack or Zoom, requiring manual postmortem assembly or third-party tools. The free plan doesn't include advanced incident response options like postmortems, ticketing, or video conference integration.
PagerDuty's Business plan costs $41/user/month vs. incident.io's $31/user/month Pro plan with on-call included. For a 50-person team, that's a $6,000 annual difference ($24,600 vs. $18,600). Enterprise plans with additional AI features vary by custom agreement and may be higher. If you're already running PagerDuty for legacy alerting and need strong escalation policies, the platform still excels there, but you'll need external tools for postmortem workflows or migration to platforms purpose-built for post-incident learning.
Rootly
Best for: Teams looking for a Slack-native alternative with strong automation and exceptional customer support.
Rootly offers AI-generated retrospectives complete with timelines and context, including follow-up tasks and checklists. The platform provides Slack-native incident management with solid workflow automation and integration coverage for major DevOps tools.
Customer support is a major differentiator. Rootly receives exceptional customer service ratings with a G2 score of 9.9 for quality of support, with users consistently noting responsiveness and helpfulness. Rootly sits between incident.io's cutting-edge AI automation and PagerDuty's legacy alerting focus, making it a solid choice for teams that want modern Slack-based workflows without needing the most advanced AI capabilities.
FireHydrant
Best for: Teams focused on service catalog-driven response with strong service modeling needs.
FireHydrant's AI transcribes video meetings, creates incident summaries and status page updates, and offers AI-enhanced retrospectives that analyze incident data for root cause analysis and contributing factors. The platform takes a service-catalog-first approach, where understanding service dependencies and ownership drives incident response workflows.
Users note responsive and helpful support from the service team. FireHydrant's workflow customization differs from incident.io's opinionated approach, offering more flexibility to configure every aspect of your incident process. This can be valuable for teams with unique requirements but adds setup time compared to incident.io's opinionated defaults that get you operational in days.
Atlassian (Jira Service Management)
Best for: Organizations already running everything on the Atlassian stack who need tight Jira integration for follow-up tasks.
The Atlassian approach comes with significant caveats. Opsgenie is being shut down with no new purchases or trials starting June 4, 2025, and end of support on April 5, 2027. After that date, all Opsgenie data will be deleted. Atlassian's official migration documentation directs customers to migrate to either Jira Service Management or Compass, splitting incident management features across tools.
The manual postmortem creation process is a major pain point. Users note that manually creating postmortem documentation in Confluence is "a hassle and easy to forget," and the lack of automated postmortem generation from Opsgenie into Confluence breaks a huge part of the workflow. For every postmortem action item, teams must raise Jira work items separately and track them in a different tool, creating fragmentation.
According to industry downtime research, the average cost of IT downtime now reaches $14,056 per minute for organizations, rising to $23,750 for large enterprises. JSM isn't built to handle alert storms, automate escalations, or coordinate response in real time the way purpose-built platforms can during high-cost incidents.
If you're deeply invested in Atlassian Cloud with enterprise licensing, JSM provides adequate postmortem documentation through Confluence integration. But teams using Opsgenie today face a forced migration, and many are evaluating incident.io, Rootly, or FireHydrant instead of moving to JSM's fragmented approach.
Comparison of postmortem software features
This comparison focuses on features SRE teams prioritize: Slack-native workflow (eliminate context-switching), AI automation (save 70-90 minutes per postmortem), on-call scheduling (consolidate tools), setup time (operational in days not weeks), and support quality (bugs fixed in hours not weeks).
| Feature | incident.io | PagerDuty | Rootly | FireHydrant | Atlassian JSM |
|---|---|---|---|---|---|
| Slack-native workflow | Yes (entire lifecycle in Slack) | Partial (multi-platform with Slack integration) | Yes | Partial | No |
| AI postmortem automation | Yes (automates up to 80% of response) | Removed Jan 30, 2026 | Yes (AI retrospectives) | Yes (AI summaries, RCA) | No (manual creation) |
| On-call scheduling | Add-on (+$12-20/user/mo) | Included | Included | Included | Via Opsgenie (sunsetting) |
| Setup time | 1-2 days | Variable | Hours | Variable | Complex |
| Support quality | Exceptional (hours response) | Mixed reviews | 9.9/10 G2 score | Responsive | Variable |
| Pricing (with on-call) | $31-45/user/mo | $60-80/user/mo | Contact sales | Contact sales | Bundled with Atlassian |
For a 50-person DevOps team, cost differences are significant: incident.io at $31/user/month = $18,600 annually, while PagerDuty at $70/user/month = $42,000 annually, a $23,400 difference that funds additional infrastructure investment.
How to automate postmortems for CI/CD pipeline failures
Deployment incidents are the most common category for DevOps teams, and automated CI/CD failure postmortems save the most time because the correlation between code changes and production failures is often obvious in hindsight but requires manual detective work during incidents.
Step-by-step automated workflow for deployment failures:
- Alert triggers from deployment impact: A Datadog alert fires for API latency following a deployment. incident.io creates
#inc-2847-api-latency-spikein Slack automatically, pages the on-call engineer, and pulls in the API service owner based on catalog metadata. - Context auto-populated with deployment details: The incident channel contains the triggering Datadog alert, recent deployments from the last 2 hours (including commit SHAs from GitHub), runbook links from your service catalog, and a live timeline that's already recording every message and action.
- Incident declared with severity: The on-call responder types
/inc summary "API response times spiking post-deploy"and/inc severity highbecause checkout is affected. These Slack commands feel natural, not like learning a new tool. - Call transcription captures verbal decisions: Scribe joins the Zoom call automatically and transcribes everything in real-time, flagging key moments and capturing decisions like "let's rollback first, then investigate."
- GitHub integration surfaces the problematic code: The responder clicks through to GitHub from the incident timeline, finds the root cause with memory usage graphs, and identifies the specific PR that introduced the issue. Next steps are laid out based on how the team has responded to similar incidents before.
- Automated postmortem draft generated on resolution: Upon typing
/inc resolve "Rolled back deploy, system stable", the system generates the postmortem draft within 10 seconds with incident summary, complete timeline with exact timestamps, transcribed call highlights, and suggested follow-up actions. - Export and follow-up task creation: The responder spends 10 minutes refining the AI draft to add context, then exports to Confluence with one click. Follow-up tasks auto-create in Jira with the full incident context attached, so the engineering team has complete information without manually copying data.
This workflow reduces deployment incident postmortems from 90 minutes of manual timeline reconstruction to 15 minutes of contextual refinement, an 83% time savings. The key enabler is real-time capture during the incident, not after-the-fact documentation.
Checklist for conducting effective DevOps postmortems
Based on Google SRE best practices and industry-standard incident management, follow these steps for every significant incident:
- Capture the timeline automatically during the incident: Use real-time capture tools that record Slack messages, slash commands, role assignments, and call transcriptions as the incident unfolds. Manual timeline reconstruction from memory introduces errors and omits critical context.
- Document specific impact with numbers: Specify which infrastructure was affected, which services or functions were disrupted, and quantified user-facing effects with specific metrics and timeframes.
- Perform root cause analysis using the 5 whys technique: Start with the symptom and ask "why?" at each level until reaching the final root cause, which is the thing that needs to change to prevent this class of incident from happening again. Document each level of causation, not just the immediate trigger.
- Create and assign specific follow-up action items: Phrase each action as a sentence starting with a verb, define scope narrowly to make clear what is and isn't included, and word each action to indicate how to tell when it is finished.
- Publish and share learnings within 5 days: Teams complete postmortems within five days of every major incident, prioritized over planned work. This ensures memory is fresh and demonstrates organizational commitment to learning.
- Schedule a blameless review meeting: Gather incident responders for a 30-45 minute discussion focused on system improvements, not individual fault. Blameless culture originated in healthcare and avionics where mistakes can be fatal, treating every error as an opportunity to strengthen the system.
- Track completion of follow-up items with accountability: Ensure action items are vetted and approved by technical leads of the affected service, assigned to specific owners with due dates, and tracked to completion in your project management tool.
Stop treating postmortems as writing assignments
The best DevOps teams don't write postmortems from scratch. They refine auto-generated drafts built from real-time incident data, CI/CD integration, and AI analysis of historical patterns. If you're still spending 90 minutes reconstructing timelines from Slack scroll-back three days after an incident, you're competing with one hand tied behind your back. Book a demo to see the CI/CD integrations pull GitHub PRs directly into your incident analysis.
For teams currently using Opsgenie (shutting down April 5, 2027), migration tools make the switch easier than rebuilding your process from scratch.
Key terminology
Toil: Manual, repetitive, automatable, tactical work devoid of enduring value that scales linearly as a service grows, including manual releases and regular password resets.
Incident management: The end-to-end process of responding to, resolving, and learning from IT service disruptions, with SREs tasked with system performance optimization, coordination, and automation.
Observability: A practice providing granular visibility into the internal state of a system by analyzing its external outputs (logs, metrics, traces) using software instrumentation to collect and analyze data across the computing environment.
AI SRE: Artificial intelligence systems designed to investigate incidents, identify root causes, and suggest fixes alongside human engineers, using machine learning to analyze patterns across logs, metrics, code changes, and historical incidents.
Blameless postmortems: Incident reviews focused on systemic causes rather than individual human error, encouraging transparency by removing fear of punishment and promoting a culture of learning and continuous improvement.
AI-powered post-incident management: Using AI to automate timeline creation, summarization, and pattern recognition in incidents, saving teams hours per incident by capturing context in real-time rather than reconstructing it from memory afterward.
DevOps postmortems: Written layouts of postmortem analysis that describe incident impact, resolution steps, root cause, and follow-up actions to prevent recurrence in the CI/CD process.
Incident management software: Tools that help SRE, DevOps, and IT teams detect, respond to, and resolve outages faster by centralizing alerting, on-call scheduling, escalation policies, communications, and postmortems to reduce downtime.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

