Why teams are leaving PagerDuty for incident.io
April 24, 2026 — 17 min read
Updated April 24, 2026
TL;DR: PagerDuty's web-first architecture creates a "coordination tax" that adds overhead to every incident before troubleshooting starts. Engineering teams are migrating to incident.io because it runs the entire incident lifecycle inside Slack, eliminating browser-tab context-switching. The result: up to 80% MTTR reduction (Intercom saved 40% of their incident time after migrating), automated post-mortems generated from captured timeline data, and transparent Pro plan pricing at $45 per user per month (incident response $25 plus on-call $20 add-on).
Upgrading your monitoring tools won't fix your MTTR if your team still coordinates incidents across five different platforms. The bottleneck in modern incident response is rarely the technical complexity of the problem. It's the organizational friction of assembling people, finding context, and switching tools at exactly the wrong moment.
PagerDuty's alerting is battle-tested. It has over 700 integrations, a proven escalation engine, and years of enterprise credibility. The problem isn't the alerting. The problem is everything that happens after the alert fires. You acknowledge in PagerDuty, coordinate in Slack, log context in Google Docs, track follow-ups in Jira, and update customers in Statuspage. Multiple tools, significant logistics, all before a single engineer writes a diagnostic command.
incident.io eliminates that coordination tax by running the full incident lifecycle inside Slack. This article breaks down exactly how the workflow differs, what the financial impact looks like, and how to migrate without downtime risk.
The browser-tab problem: why PagerDuty feels slow during incidents
Patchwork tools delay incident resolution
The typical PagerDuty-centered stack creates coordination overhead that inflates MTTR before troubleshooting even begins. When an alert fires at 2:47 AM, the workflow looks like this:
- Acknowledge in PagerDuty: Engineer gets paged, opens PagerDuty mobile or web, acknowledges the alert.
- Manually coordinate in Slack: Opens Slack, finds (or creates) a thread, types alert details, starts paging team members.
- Hunt for context: Opens Datadog in another tab, searches for the runbook in Confluence, tries to locate the relevant service owner.
- Wait for assembly: By the time the right people have the right context, 10-15 minutes have passed before troubleshooting starts.
This is the coordination overhead: time lost to assembling the team and gathering context, not the technical complexity of the incident itself.
Browser tabs increase MTTR
For a team running 15 P1 incidents per month, 10-15 minutes of coordination overhead per incident adds up to 150-225 minutes of wasted engineer time monthly, before accounting for post-mortem reconstruction. Each context switch between tools costs focus and introduces the risk of missing a critical status update or escalation window.
At a $150 loaded hourly engineer cost, that's $375-$562 burned on coordination overhead every month before a single line of diagnostic output is read.
Divided attention causes incident errors
Cognitive load during a P0 is already high. Asking on-call engineers to simultaneously manage multiple tools multiplies that load at exactly the worst moment. Status page updates get forgotten. Follow-up Jira tickets don't get created. Post-mortems get delayed because no one captured the timeline during the incident, and reconstruction from Slack scrollback takes 90 minutes when details are already fuzzy.
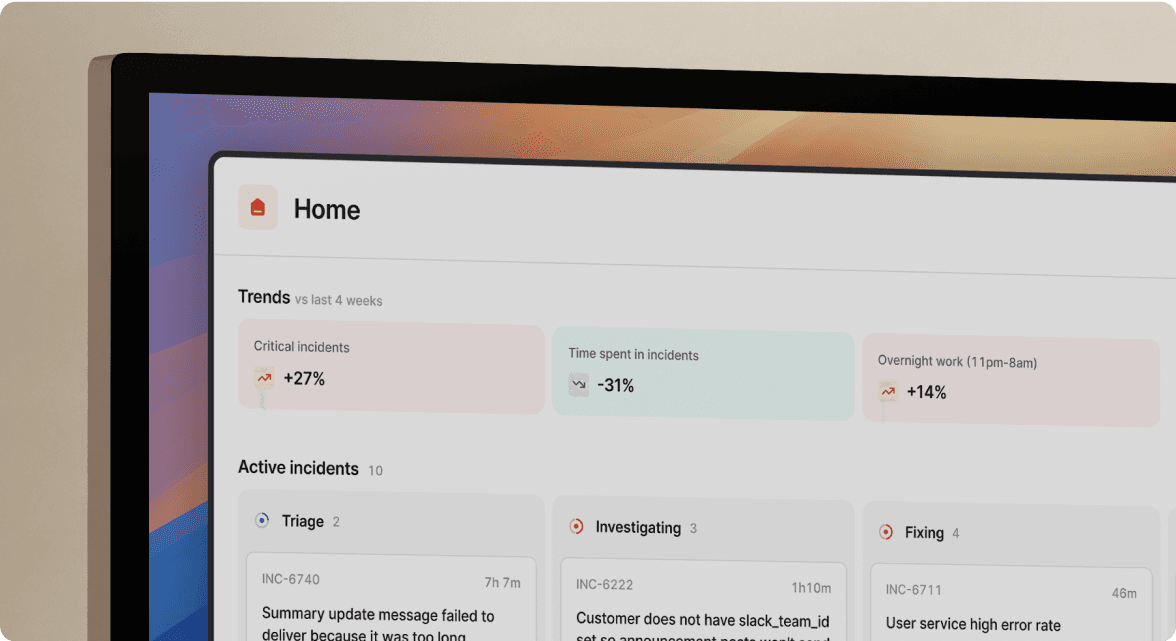
Slack-native incident management: how it works
Slack-native incident management runs the entire incident lifecycle inside Slack using slash commands and auto-created channels. This is architecturally different from a Slack integration. A typical Slack integration sends notifications to Slack and links back to a web UI for the actual work. incident.io performs the actual work inside Slack, with a web dashboard available as a supplement rather than a requirement.
Unified coordination and execution
When a Datadog alert fires and routes to incident.io, the platform automatically creates a dedicated incident channel like #inc-2847-api-latency-spike, pulls in the relevant on-call engineer, surfaces service ownership data from the Catalog, and starts capturing a live timeline. The on-call engineer opens Slack to a fully prepared incident room, not a raw alert notification.
Every incident management action then runs as a /inc command inside that channel. The commands feel natural because they are messages:
/inc assign @sarah-srenames the incident commander/inc severity highsets severity and assigns roles/inc escalate @database-teampages additional responders/inc updateposts a live status update to the channel/inc resolvecloses the incident and triggers the post-incident flow
As the escalation documentation explains, you can type /incident escalate or /incident page within an incident channel to manually escalate to the right individual or team at any point.
Automated timelines and post-mortems
Every /inc command, every role assignment, and every message in the incident channel gets captured automatically into an immutable timeline. No one needs to take notes or remember to start the Google Doc. The platform builds the post-mortem as the incident unfolds, not after it ends.
incident.io's AI Scribe transcribes incident calls via Google Meet or Zoom, extracting key decisions and flagging root cause correlations in real time. When an engineer mentions a recent deployment during the call, Scribe logs the timestamp and the connection to the current incident automatically. Because the timeline captures everything, the AI-drafted post-mortem is 80% complete at the moment of /inc resolve, leaving about 10 minutes of refining versus 90 minutes of manual reconstruction from Slack scrollback.
On-call coordination and resolution
incident.io routes alerts to the correct on-call engineer based on configured schedules and escalation policies. When a database alert fires, the platform automatically pages the database team lead rather than requiring manual routing decisions.
When an engineer types /inc resolve, incident.io closes the incident and begins the post-incident flow. Status page updates and follow-up task creation can be automated through workflows. The post-mortem document can be generated from the captured timeline data through configured workflows.
"The separation of functionality between Slack and the website is extremely powerful. This gives us the ability to have rich reporting and compliance controls in place without cluttering the experience and the workflow for the incident responders working to solve the incident during the live phase. All essential tasks during the incident live phase can be handled or initiated inside Slack." - Joar S. on G2
Zero-training onboarding and mobile access
The intuitive /inc tutorial commands and opinionated defaults mean engineers can participate effectively in their first incident without a formal training session. For context, the alternative is often a lengthy Confluence runbook that's out of date, followed by weeks of shadowing before a new engineer feels confident handling a P1. That bottleneck becomes acute when you're trying to scale your on-call rotation quickly.
On-call engineers can also manage active incidents from their phone using the Slack mobile app, running the same /inc commands they use on desktop.
MTTR reduction: incident.io's proven approach
Real customer results
incident.io customers can reduce MTTR by up to 80%. Favor reduced MTTR by 37% after adopting incident.io. Intercom consolidated their incident management toolchain with incident.io and saved 40% of their incident time.
The key takeaway: MTTR improvements at incident.io customers come primarily from eliminating the coordination overhead, not from optimizing monitoring or alerting. The technical fix is often already known within minutes. The delay is in assembling the team and getting everyone into the same context.
Automated root cause discovery
incident.io's AI SRE assistant investigates incidents the moment they're declared. It pulls metrics and logs into Slack, surfaces the likely change behind the incident, and suggests next steps based on past incidents. If the root cause is a code change, the AI SRE can generate a fix and open a pull request directly from Slack.
In practice, "automates up to 80% of incident response" means the AI takes on 80% of the response work: triage, root cause correlation, and fix suggestion. Engineers focus on the 20% that requires human judgment: the actual decision to deploy a fix or rollback a change.
Automated status page updates
When incident state changes in Slack, the status page updates automatically. Customers see accurate, real-time status rather than a stale "investigating" message from six hours ago. Status pages auto-update when incident state changes in Slack, reducing the manual work of keeping customers informed via the status page integration.
Quantifying ROI: incident.io vs. PagerDuty's spend
What's included in incident.io's price
incident.io's Pro plan costs $25 per user per month for incident response, plus $20 per user per month for on-call capabilities. Your all-in cost is $45 per user per month. That covers workflows, custom incident types, private incidents, AI-powered post-mortem generation (beta), and Microsoft Teams support.
For a 100-person engineering team, Pro with on-call runs approximately $54,000 per year.
Hidden costs in PagerDuty's pricing model
PagerDuty's Business plan pricing varies based on features selected. Vendr's market data on incident.io pricing provides additional context on how total costs compare at scale.
| Cost factor | incident.io Pro | PagerDuty Business |
|---|---|---|
| Base price (per user/month) | $25 | $41 |
| On-call (per user/month) | $20 add-on | Included |
| AI features | Included | Paid add-on (AIOps from $699/month; Advance credits extra) |
| Post-mortem tooling | AI-drafted from captured timeline data (beta) | Templates + Narrative Builder (AI add-on) |
| All-in (100 users, annual) | ~$54,000 | ~$49,200+ (AI features extra) |
Making the business case for your manager
If you need to bring your engineering manager or CTO along, here's the math to make the case.
The coordination overhead savings alone generate significant ROI beyond tool cost comparison. For a team running 15 incidents monthly:
Time saved per incident: Approximately 10-15 minutes (coordination) + 80-90 minutes (post-mortem reconstruction) = approximately 90-105 minutes per incident.
Monthly engineering hours reclaimed: Approximately 1,350-1,575 minutes (22-26 hours) across 15 incidents.
Annual value at $150 loaded cost: Approximately 264-312 hours × $150 = $39,600-$46,800 in reclaimed engineering time.
Net position: Against a Pro plan cost of $54,000 for 100 users, you reclaim significant engineering time annually, before accounting for faster customer recovery and reduced SLA breach risk.
The specific scenarios PagerDuty still owns
High cost of migration from complex routing setups
Teams that have spent years building complex, conditional alert routing rules inside PagerDuty face real switching costs. Recreating sophisticated escalation policies with branching logic across multiple services takes time, and that migration effort needs to be weighed against the coordination tax savings.
For a broader look at how to evaluate incident management software against your team's specific requirements, incident.io's buying guide covers the decision criteria in detail.
If Slack isn't your core incident hub
incident.io is built for teams where Slack or Microsoft Teams is the central nervous system of engineering communication. If your organization coordinates incidents primarily through email, phone bridges, or a different chat platform, incident.io is not the right fit. The platform requires a communications platform, and the entire value of Slack-native incident management disappears if Slack isn't where your team already works.
Migrating from PagerDuty to incident.io
The most common objection to migration is downtime risk. The answer is a parallel-run strategy where both platforms operate simultaneously until the new system is fully validated.
Run a parallel pilot for zero-downtime migration
Run incident.io alongside PagerDuty with two or three teams for a pilot period. Configure both systems to receive alerts during the pilot period so your pilot team can run real incidents through incident.io's Slack-native workflow. Your existing PagerDuty configuration stays untouched while you validate performance. Once you've confirmed that incident.io catches every alert, switch your monitoring integrations to route alerts exclusively to incident.io and maintain PagerDuty access during the transition as a safety measure until you're confident the new setup is catching every alert.
The pricing and migration cost analysis covers this approach in detail, including how to structure the handoff for teams with complex routing rules.
On-call data migration
incident.io provides PagerDuty migration documentation to help you transition when connecting the two platforms.
Alert routing migration: You can update alert routing to point to incident.io without recreating monitors manually.
Historical data: Historical incident data from PagerDuty does not transfer into incident.io's timeline format, but your alert routing and on-call configurations can be migrated.
"The recent addition of on-call allowed us to migrate our incident response from PagerDuty and it was very straight forward to setup." - Harvey J. on G2
If your team spends significant time per incident on coordination overhead, the ROI math on migrating from PagerDuty to incident.io is straightforward. The coordination tax is costing you more than the tool itself.
Schedule a demo of incident.io to walk through the Slack-native workflow with your actual alert stack and get a custom ROI calculation for your team size.
Key terms glossary
Coordination tax: The time lost per incident assembling the response team, finding context, and switching between tools before any troubleshooting begins. For teams running web-first tools, this overhead can run 10-15 minutes per incident.
Slack-native incident management: An architecture where the full incident lifecycle, including declaration, escalation, timeline capture, and resolution, runs inside Slack via slash commands and auto-created channels. This differs from a Slack integration, where Slack acts as a notification relay for a web-first platform.
MTTR (Mean Time To Resolution): The average elapsed time from when an incident is declared (typically when /inc declare is run or an alert auto-creates a channel) to when it is marked resolved with /inc resolve. MTTR includes both coordination overhead and technical resolution time.
AI SRE assistant: incident.io's AI SRE investigates incidents by pulling logs and metrics into Slack, surfacing likely root causes from past incidents, and opening fix pull requests directly in Slack when the root cause is a code change.
Parallel run: A migration strategy where both the legacy tool (PagerDuty) and the new tool (incident.io) receive alerts simultaneously during a validation period, eliminating downtime risk during the switchover.
Post-mortem: A structured document capturing what happened during an incident, why it happened, and what follow-up actions will prevent recurrence. incident.io auto-generates post-mortems that are 80% complete from captured timeline data at the moment of incident resolution, leaving about 10 minutes of human refining versus 90 minutes of manual reconstruction.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

incident.io launches PagerDuty Rescue Program
incident.io just launched the PagerDuty Rescue Program, making it easier than ever for engineering teams to ditch their decade-old on-call tooling. The program includes a contract buyout (up to a year free), AI-powered white glove migration, a 99.99% uptime SLA, and AI-first on-call that investigates alerts autonomously the moment they fire.
 Tom Wentworth
Tom WentworthMay 13, 2026

Humans aren’t fast enough for 4 9’s
Hitting 99.99% isn't a faster version of what you already do. It's a different problem to be solved: autonomous recovery, dependency ceilings, redundancies, and the discipline to build systems that buy you 15-30 minutes before you're needed at all.
 Norberto Lopes
Norberto LopesMay 11, 2026

Who's on call? How Claude helped us calculate this 2,500x faster
A look at how on-call schedules work, and how we made rendering them 2,500× faster — through profiling, smarter algorithms, and some Claude.
 Rory Bain
Rory BainApril 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization



