Stop juggling 5 tools: The best PagerDuty alternatives for Slack & Jira
December 18, 2025 — 21 min read
Updated December 18, 2025
TL;DR: The "toggle tax" of switching between PagerDuty, Slack, Jira, and monitoring tools costs 15+ minutes per incident in pure coordination overhead. The best alternatives unify incident workflows inside Slack, not just send notifications. incident.io leads for Slack-native response with AI that automates routine work, two-way Jira sync, and sub-hour setup. Rootly fits teams prioritizing customization with true bidirectional Jira sync. Jira Service Management works for Atlassian-committed shops. With Opsgenie sunsetting April 2027 and PagerDuty raising prices 10-15% annually, consolidate tool sprawl now.
The "toggle tax": Why PagerDuty + Slack + Jira is broken
Multiple tools demand attention at once. You acknowledge the alert, jump into metrics, manually spin up a Slack channel, track down the on-call engineer, copy links, create tickets, and update the status page. By the time real troubleshooting starts, minutes have already been lost to coordination overhead.
This is the toggle tax. Workers lose hours weekly to tool fatigue, 100+ hours wasted per year per person. For incident management, the root problem is not alerting. PagerDuty is battle-tested for routing alerts. The problem is alerting is 10% of incident management. The other 90% of coordination, context capture, stakeholder updates, documentation happens across five disconnected tools.
At 15 minutes per incident × 15 incidents monthly × $150 loaded engineer cost per hour, you burn $562.50 monthly ($6,750 annually) on logistics instead of fixes. The solution is not "better integration between five tools." The solution is moving the center of gravity to where your team already works: Slack.
Evaluation criteria: What makes a tool truly "Slack-native"?
Most vendors claim Slack integration. Few deliver on it. Here is the difference:
Slack-integrated (notifications-only):
- Alerts post to Slack channels as messages
- Clicking the message opens the vendor's web UI
- You acknowledge incidents in the web UI, not Slack
- Timeline lives in the web UI
Slack-native (workflow-enabled):
- Alerts auto-create dedicated incident channels
- Slash commands control the entire lifecycle (
/inc escalate,/inc assign,/inc resolve) - Timeline auto-captures from Slack messages, commands, and integrations
- Post-mortems draft automatically from captured data
When evaluating alternatives, use these criteria:
Two-way Jira sync (not just ticket creation)
What to look for:
- Closing a Jira ticket resolves the incident automatically
- Slack commands (
/inc resolve) update Jira status fields - Custom field changes propagate bidirectionally
Most tools offer one-way ticket creation. Few offer full state synchronization. True two-way sync means bidirectional data flow where changes in either system propagate instantly.
Automated timeline capture (not manual note-taking)
What to look for:
- Automatic logging of Slack messages, slash commands, and role assignments
- Real-time incident call transcriptions
- Auto-drafted post-mortems from captured data
- No designated note-taker required
Look for platforms that capture everything automatically. When you type /inc resolve, the timeline should be 80-90% complete without manual input.
Setup speed (days not weeks)
What to look for:
- Jira, Slack, and monitoring connections under 30 minutes
- Opinionated defaults that work out of the box
- Operational in days, not quarters
The best tools are opinionated with strong defaults. Avoid tools requiring six-month implementations and dedicated consultants.
Migration path from Opsgenie or PagerDuty
What to look for:
- One-click importers for schedules, escalation policies, and integrations
- Support for parallel trials (keep PagerDuty running while testing)
- Documented migration timelines and customer success stories
Atlassian announced Opsgenie end-of-life on April 5, 2027. New sales stopped June 4, 2025. For PagerDuty customers, 10-15% annual increases and degraded support drive evaluations. Average contracts run $64,621 per year, with 100-person teams exceeding $119,000 annually.
Quick comparison: The 6 alternatives at a glance
| Platform | Slack-Native | Two-Way Jira Sync | AI Capabilities | Setup Time | Starting Price (annual) |
|---|---|---|---|---|---|
| incident.io | ✓ Full workflow | One-way (workarounds available) | Up to 80% automation | <1 day | $228/user ($19/mo Team) |
| Rootly | ✓ Full workflow | ✓ True two-way | 91% faster resolution claimed | 2-3 days | $240/user ($20/mo) |
| FireHydrant | Interactive | One-way only | Runbook automation | 2-3 days | $240/user ($20/mo Starter) |
| JSM | Notifications | Native (Atlassian ecosystem) | AI summaries, classification | 2-3 months | $240/agent ($20/mo Standard) |
| Splunk On-Call | Interactive | Not documented | None documented | 3-5 days | $246/user ($20.50/mo after discount) |
| Grafana OnCall | ✓ Advanced | Not documented | None documented | 3-5 days | Free tier / $25k minimum |
Key: "Slack-Native" = full incident lifecycle via slash commands; "Interactive" = button-based actions; "Notifications" = alerts only.
Top 6 PagerDuty alternatives for Slack-centric teams
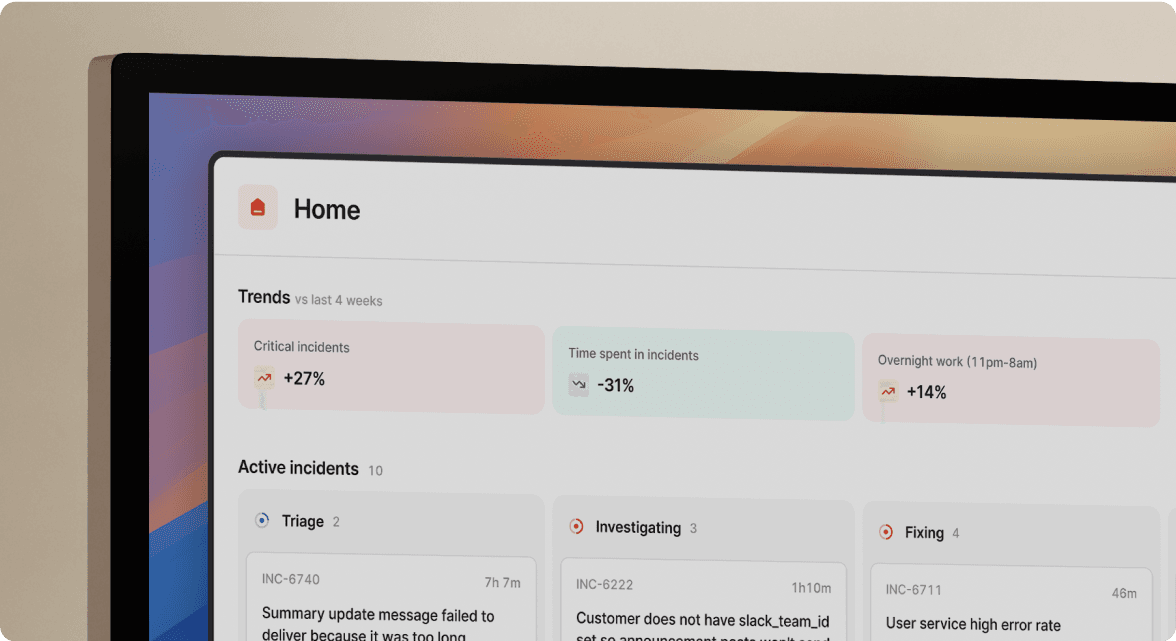
1. incident.io: The Slack-native platform
→ Best for: Teams wanting the complete incident lifecycle inside Slack without context-switching.
incident.io is the only platform architected Slack-native from day one. The entire workflow happens via slash commands: /inc declare, /inc escalate, /inc assign, /inc resolve. When Datadog fires an alert, we auto-create #inc-2847-api-latency, page the on-call engineer, pull in service owners, and start timeline capture.
Key capabilities:
- AI SRE assistant: Handles up to 80% of incident response automatically. Spots the likely pull request behind the incident, generates fix PRs in Slack, and suggests next steps. Scribe transcribes incident calls in real-time.
- Service Catalog: Maps alerts to services and teams, auto-inviting the right people based on ownership. Tracks dependencies automatically.
- Jira integration: Auto-creates tickets with full field mapping and keeps fields synchronized. Status sync requires Jira automation workarounds.
- Confluence export: Post-mortems export to Confluence with one click.
Proven results: Intercom migrated hundreds of engineers off PagerDuty in weeks. Favor reduced MTTR by 37% with 214% increase in incident detection.
"incident.io has transformed our incident response to be calm and deliberate. It also ensures that we do proper post-mortems and complete our repair items." - Verified user review of incident.io
Pricing:
- Pro (all-in with on-call): $45/user/month ($25 base + $20 on-call)
- Team (all-in with on-call): $31/user/month ($19 base + $12 on-call)
- Basic (free): Slack-native response, 1 on-call schedule, 1 status page
Pros: True Slack-native, AI that works, bugs fixed in hours, unified platform.
Cons: Opinionated design frustrates "customize everything" teams. Not built for microservice SLO tracking.
2. Rootly: The customizable toolkit
→ Best for: Teams prioritizing cutting-edge AI automation and extensive workflow customization.
Rootly is AI-native, claiming Rootly AI SRE unlocks 91% faster incident resolution. Highly customizable for teams wanting to build workflows from scratch.
Key capabilities:
- True two-way Jira sync: Automatically creates and updates Jira issues when incidents change. Jira updates also flow back to Rootly bidirectionally.
- AI-native platform: Analyzes Slack conversations, GitHub diffs, and observability tools.
- SOC 2 Type II certified: Native Microsoft Teams support.
Pricing:
- Essentials (50 users): $12,000 list ($240/user), typically $10,212 after 15% discount
- Scale (100 users): $42,000 list ($420/user), typically $31,374 after 25% discount
- On-Call add-on: $13,200 for 50 users ($264/user), negotiable to $11,140
Pros: True two-way Jira sync, extensive customization, modern AI capabilities.
Cons: High customization requires more initial configuration. Higher price point, especially at Scale tier.
3. FireHydrant: The process-heavy contender
→ Best for: Teams wanting structured incident processes with comprehensive runbooks.
FireHydrant connects the entire incident lifecycle from alert routing to retrospectives. Smart alerting, AI-powered workflows, and stakeholder communications built-in. Run incidents without leaving Slack, push updates to email and status pages.
Jira integration: Automatic ticket creation via Runbook automation for Jira Cloud and Server. Currently one-way only, Jira changes do not propagate back.
Pricing: Starter at $20/user/month, Advanced at $44/user/month. For 50-user teams, full platform costs approximately $9,600 annually, with on-call adding $4,800 extra.
Pros: Strong runbook automation, comprehensive post-incident reviews.
Cons: UI can feel complex. One-way Jira sync limits flexibility. Some users report it feels tailored to L1 tickets rather than complex SRE scenarios.
4. Jira Service Management: The "All-in-Atlassian" default
→ Best for: Organizations heavily invested in the Atlassian ecosystem and migrating from Opsgenie.
JSM includes alerting, incident response, and on-call features with AI-powered capabilities. Atlassian positions JSM as the Opsgenie replacement alongside Compass.
Key capabilities:
- Native on-call schedules with daily, weekly, or custom rotations
- Escalation policies ensuring ordered notification
- AI-powered features including incident summaries and automatic classification
- Slack integration for dedicated incident channels
Pricing:
| Plan | Price per Agent/Month | Free Tier Limits |
|---|---|---|
| Free | $0 | Up to 3 agents |
| Standard | $20 ($23.80 for 10 users) | - |
| Premium | $40-47 ($53.30 for 10 users) | 50k Assets objects, 1k virtual agent conversations |
| Enterprise | Custom | - |
Hidden costs: Premium includes 50,000 Assets objects and 1,000 virtual agent conversations monthly. Beyond these limits: $0.02/object/month, $0.30/conversation.
Pros: Native Atlassian integration, comprehensive ITSM capabilities, AI-powered features, cost-effective Free tier.
Cons: Heavyweight setup (2-3 months), service-desk-first design clunky for SREs, not built to handle alert storms in real time.
5. Splunk On-Call (VictorOps): The legacy option
→ Best for: Existing Splunk customers needing on-call scheduling bundled with observability.
Splunk On-Call automates time-sensitive actions including escalations and post-incident reviews. Acts as hub for alerts from monitoring tools, filtering and forwarding to notification systems like Slack and Jira.
Slack integration: Acknowledge, reroute, resolve, and snooze incidents using buttons in Slack. Three slash commands including /createincident.
Pricing: $14,100 annually for 50 users (list), typically $12,300-$12,700 after 10-13% discount ($20.50-$21.17/user/month).
Pros: Reliable alert routing, multi-channel notifications, strong customer support.
Cons: Dated UI, stagnant post-Splunk acquisition, complex bundled pricing, no AI features.
6. Grafana OnCall: The open-source choice
→ Best for: Teams deep in the Grafana ecosystem wanting integrated on-call management.
Grafana OnCall reduces toil through simpler workflows tailored for developers. Part of Grafana Cloud IRM app, ideal for distributed teams. Automated alert routing reduces incident response time.
Slack integration: Advanced Slack App enables complete alert management inside Slack. Slash commands like /escalate page teams directly. Users can acknowledge and resolve alert groups.
Pricing: Free tier available. Minimum $25,000/year for paid plans. Critical: Grafana OnCall OSS entered maintenance mode March 11, 2025, and will be archived March 24, 2026.
Pros: Strong open-source roots, free tier, advanced Slack integration.
Cons: Technical setup required. Community-based support for free version. OSS entering end-of-life 2026. No Jira integration documented.
Deep dive: How to integrate Jira with Slack for incident response
Most teams use Jira for project management and Slack for communication. The question: can you make them work together for real-time incident response without manual copy-pasting?
The difference between "notifications" and "two-way sync"
The official Jira Cloud app for Slack lets you create issues, comment, and get notifications. This saves time by reducing context-switching.
What it does well:
/jira createcommand creates tickets from Slack- Notifications when issues update
- Post issue links that unfurl with details
What it does not do:
- Automatically create tickets when incidents start
- Update Jira status when you resolve incidents in Slack
- Sync custom fields bidirectionally
- Create dedicated incident channels tied to Jira tickets
Purpose-built incident platforms offer deeper integrations:
incident.io: Auto-creates tickets when incidents are declared and maps issue types. Keeps fields synchronized. Can create different tickets in different projects based on custom fields. Status sync requires Jira automation workarounds.
Rootly: Two-way sync automatically creates and updates Jira issues when incidents change. Jira changes also update Rootly bidirectionally.
FireHydrant: Automatic ticket creation via Runbook automation. Currently one-way only.
Step-by-step: Setting up Jira ticket creation from Slack
- Connect Jira Cloud app: Install the platform's app from Atlassian Marketplace, navigate to your Jira site, and connect your organization. OAuth2 handles authentication.
- Map issue types and fields: Specify which Jira project receives tickets, map issue type (Bug, Incident, Task), and configure required fields, summary, description, and priority.
- Configure routing conditions: Create templates that route tickets to different projects based on severity. SEV1 incidents go to "Critical Incidents," SEV3 to "Bugs."
- Test with practice incident: Use
/inc declareto start a test incident and verify the ticket appears in the correct project with proper fields. - Set up status sync (if available): For two-way platforms like Rootly, configure which Jira status changes update incident status. For one-way platforms, use Jira automation rules to call webhooks for status synchronization.
Automating the post-mortem export to confluence
After resolving an incident, you need a post-mortem. The legacy process: spend 90 minutes scrolling through Slack threads, Zoom recordings, and memory to reconstruct what happened.
Modern platforms capture timelines automatically. Every Slack message, slash command, role assignment, and integration event is logged.
- Add Confluence as document destination: Navigate to Settings → Post-incident flows, click "Add destination," and configure the default space.
- Draft post-mortem with AI assistance: Scribe generates detailed notes with "Overview," "Key moments," and "Next steps" sections, 80% complete automatically.
- Export with one click: Hit "Export" at the top. All sections move to Confluence while follow-ups and timeline remain in incident.io's post-incident tab.
Migration guide: Moving off Opsgenie or PagerDuty
With Opsgenie end-of-life on April 5, 2027, thousands of teams face forced migrations. PagerDuty customers tired of 10-15% annual price increases voluntarily evaluate alternatives.
Step 1: audit your current configuration
Document your setup before migration:
- Count on-call schedules and escalation policies: you'll recreate these in the new platform
- List all integrations: Datadog, Prometheus, New Relic, etc.
- Export service definitions: names, owners, dependencies
- Note custom fields: metadata you track beyond standard severity/status
Export your PagerDuty or Opsgenie configuration. We provide dedicated migration tools that import schedules, policies, and integrations automatically. For Opsgenie migrations, similar tools streamline the process.
Step 2: Run a parallel trial (the "Pepsi Challenge")
Don't rip out PagerDuty on Day 1. Keep it running while you test the new platform. When an alert fires:
- PagerDuty still pages the on-call engineer
- The new platform also creates an incident channel in Slack
- Run the incident in the new platform's Slack workflow
- Document MTTR and team feedback
After 5-10 incidents, you have data: "Resolution in incident.io took 28 minutes vs 45 minutes in PagerDuty because we eliminated browser-hopping."
Step 3: Import configuration and cut over
Once confident, import full PagerDuty configuration. Migrate Datadog monitors to incident.io or equivalent tool for alternatives.
Update alert destinations: change Datadog webhook URL from PagerDuty to incident.io. Do this service-by-service or all at once depending on risk tolerance.
Timeline: Most teams complete migration in 14-30 days with parallel trials.
Choose the tool that fits your workflow
Choose incident.io if:
- You want true Slack-native response where the entire lifecycle happens in chat
- You value support that fixes bugs in hours and ships features in days
- You need AI that automates up to 80% of response, not just correlates logs
- You want a unified platform replacing PagerDuty, status pages, and post-mortem docs
Choose Rootly if:
- You prioritize cutting-edge AI automation and extensive customization
- You need true two-way Jira sync where changes flow bidirectionally
- You are willing to invest time in configuration
Choose JSM if:
- You are committed to the Atlassian ecosystem and migrating from Opsgenie
- You need comprehensive ITSM capabilities beyond incident management
- You can accept 2-3 month implementation timelines
Choose FireHydrant if:
- You want strong runbook automation and structured processes
- You prioritize comprehensive post-incident reviews
- One-way Jira sync is acceptable
Choose Splunk On-Call if:
- You are already a Splunk customer with existing investment
- Reliable alert routing matters more than modern UX
Choose Grafana OnCall if:
- You are deep in the Grafana ecosystem
- Open-source roots appeal to you
- You can handle technical setup (note: OSS enters end-of-life March 2026)
The toggle tax is real. Every minute spent switching between PagerDuty, Slack, Jira, Confluence, and status pages is a minute not spent fixing the actual problem. Teams can start with incident.io’s Pro plan at $25 per user, which delivers Slack-native incident response, built-in on-call, and AI-assisted workflows without the overhead of legacy tools. The best alternative is not the cheapest alerting tool but the platform that eliminates tool sprawl by unifying incident response where your team already works.
Here's the question for your next incident: will your team spend 15 minutes coordinating or 2 minutes assembling and 13 minutes solving?
Book a demo of incident.io to see Slack-native incident management in action, including two-way Jira sync, AI-powered post-mortems, and automated timeline capture.
Key terminology
Two-way sync: Real-time bidirectional data mirroring between platforms where changes in either system propagate automatically. Closing a Jira ticket resolves the incident, and resolving the incident updates Jira status.
Slack-native: Platform architecture where the entire incident workflow happens inside Slack via slash commands and channel interactions. Zero browser tabs required for incident coordination.
MTTR (Mean Time To Resolution): Average time from incident detection to full resolution. Favor reduced MTTR by 37% by eliminating coordination overhead.
Toggle tax: Productivity cost of context-switching between multiple tools during incidents. Includes time lost orienting yourself in each tool and manually syncing data between systems.
Timeline capture: Automatic logging of incident events (Slack messages, slash commands, role assignments, call transcriptions) without manual note-taking. Modern platforms use captured data to auto-generate post-mortems.
Service Catalog: Structured map of services, teams, and ownership that powers intelligent alert routing. Ensures the right people are notified automatically based on affected service.
Post-mortem: Blameless incident retrospective documenting what happened, why, and follow-up actions. AI-powered platforms draft these automatically from captured timeline data rather than requiring 90 minutes of manual reconstruction.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

What are the biggest objections to migrating off PagerDuty, and how do you solve them?
Most PagerDuty migration objections aren't about the product. They're about risk, budget, timing, and who owns the project internally. incident.io has run migrations for Zendesk, DocuSign, Intercom, Pure Storage, and dozens of other companies — the same seven objections come up almost every time.
 Eryn Carman
Eryn CarmanJuly 10, 2026

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
Eryn CarmanJune 9, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

