Slack integration for Jira: Does it help reduce incident MTTR?
December 16, 2025 — 18 min read
Updated December 16, 2025
TL;DR: Basic Jira-Slack integrations handle ticket creation and notifications, but they don't reduce MTTR because they miss the coordination layer. You still manually create channels, assemble teams, and reconstruct timelines after the fire. Purpose-built platforms like incident.io automate these coordination tasks inside Slack, reducing manual coordination work by up to 80% and materially improving MTTR.. Favor reduced their MTTR by 37% by switching from DIY integrations to automated incident orchestration. If you're handling 5+ incidents monthly, the coordination tax is costing you more than a purpose-built platform.
The integration promise vs. the incident reality
You connected Jira and Slack. Tickets appear in channels. Updates flow both ways. Problem solved, right?
Not when production goes down at 2 AM. The Atlassian Marketplace offers over 4,000 apps and integrations, yet engineering teams still waste 10-15 minutes per incident just assembling people and finding context. The issue isn't communication—it's coordination.
When a critical alert fires, you manually create the Slack channel, ping the on-call engineer, open five browser tabs for Datadog and PagerDuty, create the Jira ticket, start a Google Doc for notes, and update the status page. Twelve minutes of coordination before troubleshooting starts.
The missing piece isn't another integration. It's a coordination layer that automates team assembly, timeline capture, and post-incident documentation.
What Jira-Slack integrations actually give you
The native Jira Cloud for Slack app provides basic connectivity between your ticketing system and chat platform.
Core capabilities:
- Connect Jira projects to Slack channels using
/jira connect - See automatic previews when someone pastes a Jira URL
- Create tickets from Slack with
/jira create - Receive personal notifications for assigned issues
- View ticket status updates in channels
The setup takes about five minutes. Install the Jira Cloud app from Slack's app directory, log into your Atlassian account, and configure which notifications you want. Turn on personal notifications with /jira notify.
Notification types include:
- Issue created in connected project
- Issue assigned to you
- Status changes on issues you follow
- Comments added to your tickets
- Mentions in Jira comments
The integration reduces context switching during routine ticket work. But there's a critical distinction between routine tickets and incident response. During incidents, you need orchestration, not just notifications.
How to connect Jira and Slack: The basic path
For teams evaluating whether DIY integration meets their needs, here's the complete setup:
1. Install the Jira Cloud app
From your desktop, click "Tools" in the sidebar, select "Apps," search for "Jira Cloud," and click "Add to Slack." Grant access by logging into your Atlassian account.
After logging in, the Jira Cloud app sends you a direct message in Slack. From there, connect your first Jira project to a Slack channel.
2. Connect projects to channels
In any public or private channel, type /jira connect to link that channel to a Jira project. Select which project and configure which events trigger notifications: all issues, only high priority, or specific issue types.
3. Create tickets from messages
Type /jira create into any channel or direct message. A form appears where you select the project, issue type, and fill out summary, description, and assignee fields.
The limitation shows up immediately. Every required field needs manual entry. During a 3 AM incident when you're coordinating five engineers, filling out a Jira form adds friction, not speed.
4. Configure notifications
Use /jira notify to turn on personal notifications. Choose when to be notified: all updates, only mentions, or only assignments. Managing notification volume remains a challenge across many Slack integrations—users often report being swarmed by updates and wish for better grouping of related issues.
This setup works fine for tracking feature requests and bug reports. But it doesn't solve the incident coordination problem.
Why basic integrations fail when production is down
The native Jira-Slack integration has limited bi-directional sync. Comments or updates made in Slack may not fully reflect in Jira. You can't edit ticket fields or change statuses directly from Slack.
Gap 1: No automatic incident orchestration
When Atlassian describes major incident management, incidents are "created in Jira Service Management and managed in Opsgenie." When a major incident is created, "Opsgenie creates a corresponding incident and responder alert."
Notice what's missing: no automatic Slack channel creation, no automatic role assignment, no on-call paging directly from the alert. You're manually setting up the response infrastructure while customers are impacted.
Gap 2: Timeline reconstruction, not capture
The integration doesn't capture what happens during the incident—who did what, when. Which fix attempts failed. What decisions were made in the war room. Google's SRE workbook notes that quality postmortems take time to write, and "when a team is overloaded with other tasks, the quality of postmortems suffers."
Engineering teams spend 60-90 minutes after major incidents scrolling through Slack threads, reviewing Zoom recordings, and piecing together timelines from memory. That's 90 minutes of senior engineer time at $150-190 per hour fully-burdened cost (base salary plus benefits, taxes, and overhead), costing $225-285 per incident in post-mortem reconstruction alone.
Gap 3: No service context at response time
When the alert fires, which team owns this service? Who's on-call for the database layer? What changed in the last deployment? The Jira ticket has the issue description. Slack has the conversation. Datadog has the metrics. Your service catalog lives in Confluence. You're alt-tabbing between four tools to assemble context.
Users report that integrations require multiple apps to get even simple workflows functioning reliably. The coordination tax compounds during high-stress moments.
Gap 4: Notification overload, not intelligent routing
The Jira-Slack integration sends notifications to channels based on project configuration. It doesn't understand incident severity or automatically escalate to the right on-call engineer. During an incident, you need laser-focused routing that pulls in exactly the right people based on service ownership, not broadcast notifications to entire channels.
What changes with purpose-built incident management
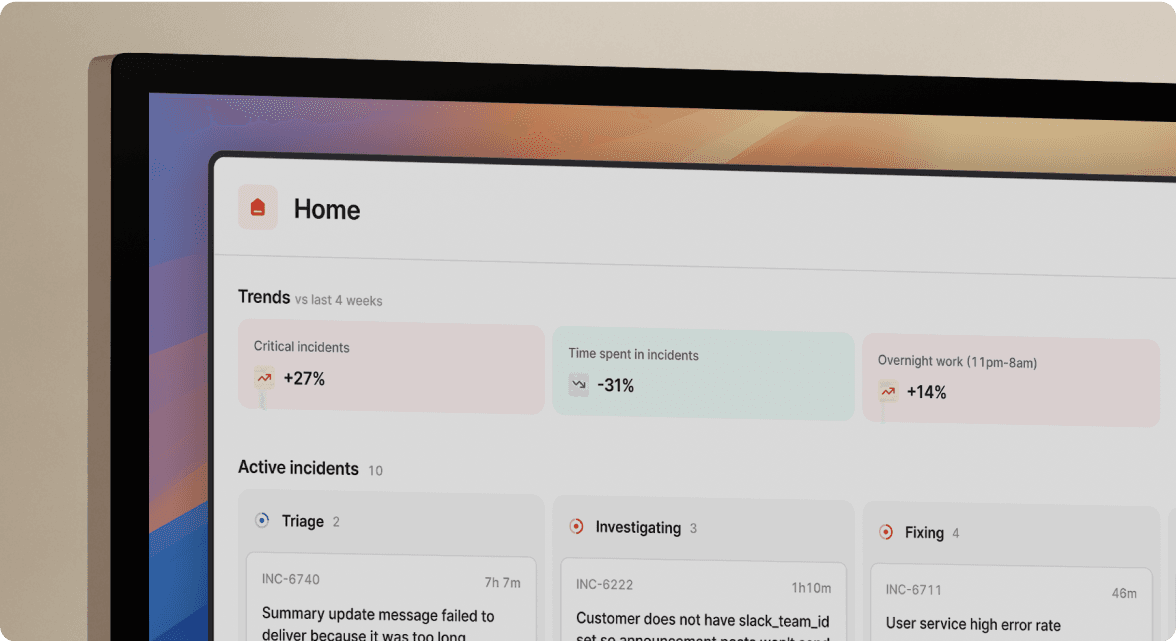
We handle the complete incident lifecycle inside Slack, automating coordination that integrations leave manual. When an alert fires, we auto-create a dedicated channel, page the on-call engineer, pull in service owners based on your catalog, and start capturing the timeline automatically.
Automatic incident declaration and assembly
One Slack command declares the incident. We create #inc-2847-api-latency channel automatically, page the on-call SRE, invite the service owner from the catalog, pin the alert details, and start the timeline.
Team assembly drops from 10-15 minutes to under 2 minutes. For a 100-person engineering team handling 20 incidents monthly, that's 15 minutes saved per incident × 20 incidents × 12 months = 3,600 minutes (60 hours) annually. At a $190 fully-burdened hourly cost for senior engineers, coordination overhead alone costs $11,400 per year.
AI-powered investigation and resolution
Our AI SRE assistant automates up to 80% of incident response by scanning thousands of resources, finding what's broken, sharing context, and recommending next steps. It spots the likely pull request behind the incident so engineers can review changes without leaving Slack. If the root cause is a code issue, the AI generates a fix and opens a pull request directly in the incident channel.
"Incident provides a great user experience when it comes to incident management. The app helps the incident lead when it comes to assigning tasks and following them up... In a moment when efforts need to be fully focused on actually handling whatever is happening, Incident releases quite a lot of burden off the team's shoulders." - Verified user review of incident.io
Automated post-mortem generation
When you type /inc resolve, we draft the post-mortem automatically using the captured timeline, including contributing factors and follow-ups. Engineers spend 15 minutes refining the draft instead of 90 minutes writing from scratch.
The time savings compound. If post-mortem writing drops from 90 minutes to 15 minutes across 20 incidents monthly, that's 75 minutes saved × 20 incidents = 1,500 minutes (25 hours) per month, or 300 hours annually. At $190 per hour, that's $57,000 in reclaimed senior engineer time per year.
On-call scheduling that pages the right people
We unify on-call management with incident response, creating schedules directly in the platform with rotations, multiple layers, and calendar sync via iCal. When you declare an incident, we automatically page responders based on who's currently on-call.
Override schedules by clicking directly on the calendar. Escalate to the next level with one slash command when the initial responder needs backup. Our escalation paths include round robin distribution, page everyone simultaneously, or custom sequences based on severity. Sync schedules with Slack user groups so @mentions automatically route to whoever's currently on-call.
"Clearly built by a team of people who have been through the panic and despair of a poorly run incident. They have taken all those learnings to heart and made something that automates, clarifies and enables your teams to concentrate on fixing, communicating and, most importantly, learning from the incidents that happen." - Verified user review of incident.io
Real MTTR reduction: The Favor case study
Favor, the food delivery service powering H-E-B's home deliveries across Texas, reduced MTTR by 37% by automating incident coordination in Slack with incident.io. The improvement came from eliminating coordination friction that plagued their previous DIY setup.
Etsy's engineering team made "tangible improvements to the way it manages site outages" after adoption. Engineers now proactively declare smaller incidents because the friction disappeared.
For implementation speed, one customer with a 15-person engineering team integrated in less than 20 days, calling the onboarding "outstanding." A larger organization with 200+ people fully implemented incident.io across multiple teams in just 45 days, noting that "structured workflows and Slack-native approach" made adoption frictionless.
incident.io integrates WITH Jira, not instead of it
You don't have to choose between incident.io and Jira. We integrate bidirectionally with Jira, Datadog, PagerDuty, and Confluence, plus 50+ other tools in your stack, so you can keep using what works while automating the coordination layer.
How the integration works:
You automatically create tickets representing an incident in Jira when declaring an incident in Slack. We keep fields and variables in sync, updating the Jira ticket with the latest information as the incident progresses.
What syncs automatically:
- Incident severity changes
- Status updates
- Assigned responders
- Custom field values
- Follow-up action items
One caveat: direct status synchronization is not available between incident.io incident status and Jira ticket status. You can implement a workaround using string custom fields and Jira automations if bidirectional status sync is critical.
The integration preserves your existing Jira workflows for follow-up tasks while moving real-time incident coordination into Slack where your team already works. You get incident.io for speed during the fire, Jira for structured tracking afterward, and Confluence or Google Docs for post-mortem storage.
Pricing reality: What the full stack actually costs
Here's the transparent cost comparison for a 100-person engineering team:
| Cost Component | DIY Jira-Slack Stack | incident.io Unified |
|---|---|---|
| Jira Software Cloud | $815–$980/month ($8.15–$9.80 per user) | Included in workflow |
| Slack Pro | $725/month | $725/month |
| PagerDuty/On-call tool | $4,100/month ($41/user) | Included (on-call add-on) |
| Statuspage | $29-$99/month | Included in status pages |
| incident.io Pro + On-call | — | $2,500–$4,500/month ($25/user on Pro) |
| Monthly Total | ~$5,669–$6,204 | $5,225 |
| Annual Total | ~$68,028–$74,448 | $62,700 |
| Annual savings | — | $5,328–$11,748 |
The platform approach saves $5,300–11,700 annually on tool costs alone. But the real ROI comes from engineering time savings:
Time saved per incident:
- Assembly time: 13 minutes faster (15 min → 2 min)
- Post-mortem: 75 minutes faster (90 min → 15 min)
- Total per incident: 88 minutes saved
Annual impact:
- 20 incidents/month × 88 minutes = 1,760 minutes saved monthly
- 21,120 minutes (352 hours) saved annually
- At $190/hour fully-burdened cost = $66,880 in reclaimed engineering time
Combined, this delivers $72,000–$78,000 in total annual value for a 100-person team..
Comparing DIY integration vs. purpose-built platform
| Capability | Jira + Slack Integration | incident.io Platform |
|---|---|---|
| Channel creation | Manual - create channels by hand | Automatic dedicated channel |
| On-call paging | External tool required (PagerDuty) | Built-in scheduling and paging |
| Timeline capture | Manual notes in Google Doc | Automatic capture of all actions |
| Post-mortem generation | 90 min manual writing | 15 min AI-drafted from timeline |
| Service context | Lookup in Confluence | Catalog surfaces owners automatically |
| Status page updates | Manual in Statuspage tool | Automatic updates on incident changes |
| AI root cause identification | Not available | Up to 80% automation with pattern recognition |
| Implementation time | Weeks of configuration | 20 days for 15-person team, 45 days for 200+ |
| MTTR impact | No measurable reduction | 37% reduction at Favor |
| Annual cost (100 users) | ~$68,028–$74,448 | $62,700 ($5,300–11,700 savings) |
| New responder training | 2-3 weeks to confidence | 2-3 days with guided workflows |
Security and compliance for incident data
DIY integrations using custom webhooks and scripts often lack proper audit trails. When your CISO asks "who had access to this incident channel?", reconstructing the answer takes hours of log analysis.
We provide SOC 2 Type II certification, meaning an external auditor verified that we meet high security standards for how our software is managed and operated, and how we handle security, availability, and privacy of data.
We retain and remove data in accordance with GDPR, storing data only as long as necessary and removing it on request within 30 days. Primary data residence is in the EU with AES-256 encryption for data at rest and secure protocols for data in transit.
For enterprise customers requiring SSO and SCIM provisioning, the Enterprise plan includes SAML/SCIM support for centralized access control. Organizations can manage private incident channels for security incidents that require restricted access.
When DIY integration is actually fine
Basic Jira-Slack integration works well for:
Low-frequency, low-severity scenarios:
- Tracking feature requests from customer feedback
- Bug reports that need triage over hours, not minutes
- Internal IT tickets for account access and equipment
- Project management updates for non-time-critical work
If your team handles 1-2 production incidents per quarter, the coordination overhead probably doesn't justify a dedicated platform. The ROI threshold appears around 5-10 incidents monthly when time savings compound.
When you need maximum Jira customization:
- Complex approval workflows with 10+ approval stages
- Highly customized fields specific to your vertical
- Deep integration with other Atlassian tools (Bitbucket, Bamboo)
However, when production is down at 3 AM and customers are impacted, manually creating channels and pinging people adds 10-15 minutes before troubleshooting starts. That's when the DIY approach breaks down.
Get started with purpose-built incident management
If you're ready to eliminate coordination overhead and reduce MTTR, try incident.io. The Basic plan includes Slack-native incident response, 1 on-call schedule, 1 status page, and core automation to test the workflow with your team.
For teams handling 10+ incidents monthly, the Pro plan at $25/user/month with on-call unifies scheduling, response, status pages, and post-mortems in one platform. Schedule a demo to see the full workflow: alert fires → channel created → team assembled → timeline captured → post-mortem drafted automatically.
Favor's 37% MTTR reduction came from eliminating coordination friction during their proof of concept evaluation. By the time a major incident hit, the muscle memory was there. The coordination happened automatically. Engineers focused on troubleshooting, not logistics.
Not ready to try the product yet? Read more customer stories showing measurable MTTR improvements, or explore our guides and recordings for best practices on incident management and on-call processes.
Key terms glossary
MTTR (Mean Time To Resolution): The average time from when an incident is detected until it's fully resolved and services return to normal operation. Measured in minutes or hours.
Incident coordination: The process of assembling the response team, assigning roles, capturing timeline data, and managing communication during an incident. Distinct from technical troubleshooting.
Service catalog: A structured inventory of services, teams, owners, dependencies, and runbooks that enables automated routing and context surfacing during incidents.
Post-mortem: A blameless document created after an incident that captures the timeline, root cause analysis, contributing factors, and follow-up actions to prevent recurrence.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

