PagerDuty Limitations: 7 Reasons engineering teams are switching in 2026
March 6, 2026 — 18 min read
Updated March 06, 2026.
TL;DR: PagerDuty built its reputation on reliable alerting, and that reputation holds. But in 2026, getting paged isn't the hard part. Coordination, context, and learning from incidents are. PagerDuty's fragmented workflow forces you to juggle five tools during every incident, losing 10-15 minutes on logistics before troubleshooting starts. We built incident.io as a Slack-native alternative that handles the full lifecycle (alert to post-mortem) in one interface. Teams switching to incident.io cut MTTR by up to 80% by eliminating context switches, auto-capturing timelines, and AI-drafting post-mortems in 15 minutes instead of 90.
For a decade, PagerDuty was the default answer to "how do we handle on-call?" Its SMS delivery and escalation policies were battle-tested, and nobody got fired for choosing it. But as infrastructure moved to microservices and communication moved to Slack, PagerDuty stayed focused on the alert rather than the response. We see the result every day: teams juggling PagerDuty, Slack, Jira, Google Docs, and Statuspage during every incident, losing 10-15 minutes per incident on logistics before anyone touches the actual problem.
Here are the 7 structural limitations driving engineering teams to switch in 2026, and what the modern alternative looks like in practice.
1. The context switch tax is increasing your MTTR
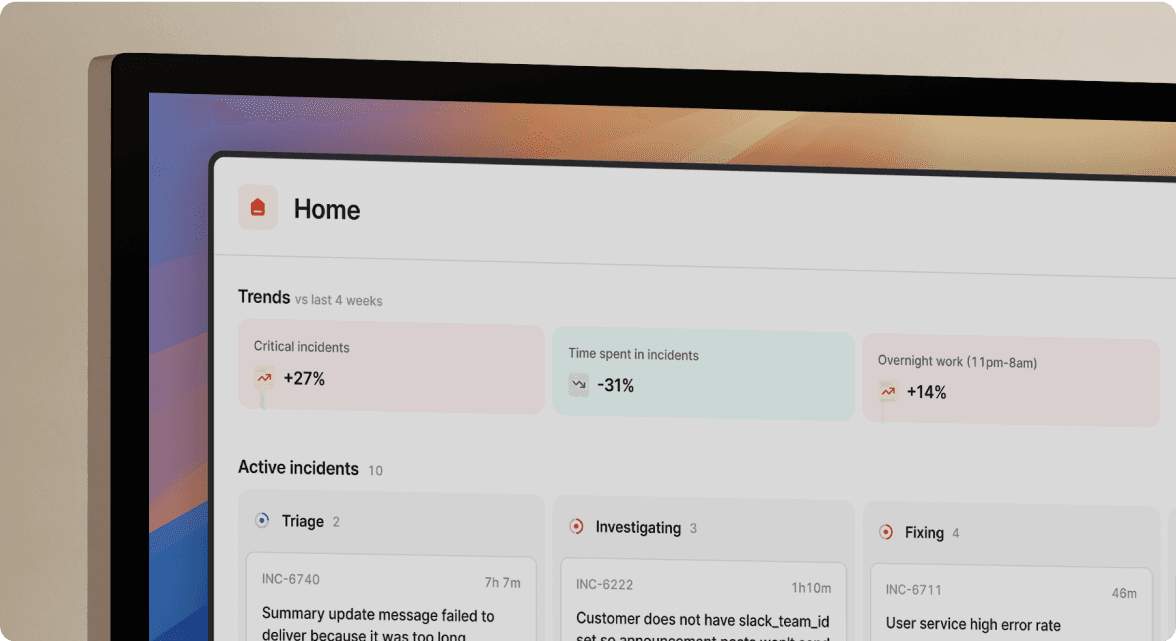
You know the pattern. PagerDuty fires. You open Slack. You manually create a channel, ping teammates one by one, open Datadog, start a Google Doc for notes, create a Jira ticket, remember to update Statuspage. You start troubleshooting 12 minutes later.
This is the context switch tax, and it compounds with every tool you add. PagerDuty's Slack integration covers basic triage actions like acknowledge and resolve, but creating schedules, editing escalation policies, configuring alert routing, and accessing analytics all require leaving Slack and opening the PagerDuty web UI. Your engineers spin between browser tabs while the clock runs.
Here's what the tool sprawl looks like before and after consolidation:
| Incident step | PagerDuty workflow (5 tools) | incident.io workflow (1 interface) |
|---|---|---|
| Alert fires | PagerDuty pages on-call | Alert auto-creates incident channel |
| Team assembly | Manually ping teammates in Slack | On-call auto-paged, service owner pulled in |
| Coordination | Separate Slack threads, Zoom | Everything in one Slack channel |
| Status updates | Manual Statuspage update | Auto-updated on /inc resolve |
| Post-mortem | 90 min reconstructing Slack + PD history | AI draft ready, 15 min editing |
You reclaim 12 minutes per incident just by consolidating coordination into Slack. Across 15 incidents per month, that's 3 hours of pure logistics overhead eliminated.
We eliminate the swivel chair entirely. When a Datadog alert fires, we auto-create the incident channel, page on-call, and start capturing the timeline, all without your engineers leaving Slack. Favor's engineering teamcut MTTR by 37% after implementing this approach.
"Too many to list - it's a one stop shop for incident management (not just on call rotations like many competitors. Built in and custom automations, great slack integration, automated post mortem generation, jira ticket creation, followup and actions creation, post incident workflows. It takes all the pain out of incident management and lets you focus on working the incident itself." - Verified user on G2
2. Alert fatigue has evolved into alert exhaustion
PagerDuty's noise problem shows up repeatedly in user reviews. Across review platforms, pricing and UI complexity lead the complaints, but alert exhaustion runs close behind. The issue isn't just volume, it's the absence of context. PagerDuty alerts tell you something is wrong. They rarely tell you why or what changed.
When a "CPU High" alert fires at 2 AM, your on-call engineer immediately starts an archaeology project: Which service? Which team owns it? Did anyone deploy recently? What does the runbook say? You're gathering context during the highest-stress window of the response, and the tool isn't helping.
Users consistently describe PagerDuty's interface as unintuitive and overwhelming, particularly for managing schedule overrides, rotations, and configurations. Simple tasks require extra steps that slow you down when you can least afford it.
We address this at the alerting layer through Catalog-aware alerting. Instead of "CPU High," your on-call engineer gets: "CPU High on Payments Service, owned by the Payments team, who shipped a deploy 5 minutes ago." The Service Catalog surfaces runbooks, recent deployments, and team ownership automatically, eliminating the manual context-gathering step that compounds every response. You can also group alerts by catalog-backed attributes to spot patterns across services before they cascade into major outages.
3. Post-mortems are still manual archaeology
After a major incident resolves, you spend 60-90 minutes scrolling through Slack threads, PagerDuty alert history, Datadog event annotations, and half-remembered Zoom call decisions, trying to reconstruct what happened and in what order.
PagerDuty's post-mortem process requires teams to manually populate the document: review the incident log in Slack, identify the relevant metrics, link to third-party dashboards. The timeline doesn't build itself during the incident. You build it afterward, from memory, 3-5 days later when the details have already faded.
The result is incomplete post-mortems published too late to be actionable. Engineers start avoiding them. Your org stops learning from incidents. MTTR stays flat because nobody identifies the root patterns.
We capture the timeline automatically during the incident. Every severity change, status update, and pinned Slack message becomes a timestamped timeline entry tracked via the incident timeline engine. When you type /inc resolve, we've already generated an 80% complete post-mortem draft, including incident summary, key decisions, and suggested action items. Your engineers spend 15 minutes reviewing instead of 90 minutes reconstructing from scratch.
AI Scribe takes this further by transcribing incident calls in real time across Zoom and Google Meet. It proactively surfaces key moments and decisions from the call back into the incident channel as structured updates, so nothing discussed verbally gets lost. After the call ends, Scribe generates structured notes with an overview, key moments, next steps, and participant list, all automatically posted to the incident timeline. You can also add or remove Scribe from any call with a single command.
"Another handy feature is its ability to automate routine actions, such as postmortem reports generation. This automation can significantly reduce the time spent on manual, repetitive tasks, reusing the incident communication channel on Slack as a basis for the postmortems summary." - Vadym C. on G2
4. On-call onboarding takes weeks, not days
New engineers joining your on-call rotation face a PagerDuty configuration maze: Services, Escalation Policies, Schedules, and User Roles are built as separate objects that connect in non-obvious ways. Editing a schedule override requires deleting and recreating the entry rather than a simple drag-and-drop. The mobile app notification preferences sit in a separate configuration layer from the web app.
User reviews consistently flag "complexity of initial set-up, pricing, not a very user-friendly UI" as the leading friction points. For a junior engineer added to the on-call rotation, opening PagerDuty at 2 AM during their first P1 and navigating that interface is its own incident.
When your process lives inside a complex web UI rather than inside the communication tool your team already uses, cognitive load doubles at the worst possible moment.
We run entirely inside Slack, where your engineers already work. The /inc command structure is intuitive: /inc declare, /inc escalate, /inc assign, /inc resolve. If your team can use Slack, they can run an incident from day one. New on-call engineers don't need weeks of shadowing to feel confident. The incident tutorial lets them practice in a safe environment without creating real incidents or triggering billing.
"Now engineers are comfortable that when the proverbial alarm bells ring at 3am, they won't miss out important process while dealing with chaos, or have to be reading through long incident-management runbooks that aren't related to the problem at hand. Ability to focus entirely on resolving the issue while incident.io makes sure every box is checked has been keenly felt within the engineering teams." - Jack S. on G2
5. Pricing models punish you for scaling reliability
PagerDuty's pricing structure creates a disincentive for the behavior you want to encourage: broad participation in incident response. Here's what the add-on model actually looks like in 2026:
- Base Business plan: $41/user/month
- AIOps (noise reduction): $699/month additional
- PagerDuty Advance (AI features): $415/month additional
- Status Pages: $89/page per 1,000 subscribers
- View-only stakeholder licenses: $150 for 30 users/month
- Alert grouping: $24/user/month additional
On top of the $41/user/month base, you're paying $1,114/month in add-on fees just to get AI noise reduction ($699/month) and generative AI assistance ($415/month). Features that should be core to any modern incident management platform. That pricing complexity means teams routinely discover the real cost during procurement, which erodes trust and creates friction at renewal.
The stakeholder licensing model is particularly punishing. You want your customer support team to see incident status. You want your product manager to follow along during a major outage. You want your VP of Engineering to have visibility. Each of those people costs you money in PagerDuty. Teams end up limiting incident visibility to cut costs, which works directly against the shared ownership culture that reduces MTTR.
Our Pro plan is $45/user/month with on-call included. No separate AI add-on purchase. Our pricing reflects a clear philosophy: more people involved in reliability is better, not a billing opportunity.
"We like how we can manage our incidents in one place... The recent addition of on-call allowed us to migrate our incident response from PagerDuty and it was very straight forward to setup." - Harvey J. on G2
6. AI features are bolt-on, not built-in
PagerDuty has invested in AI capabilities, and their noise reduction results are real: PagerDuty AIOps targets significant alert volume reduction. But the architecture of how that AI is delivered creates two problems for your team.
First, the cost structure. Noise reduction (AIOps) and generative AI assistance (PagerDuty Advance) are separate purchases at $699/month and $415/month respectively. Treating AI as a premium add-on means smaller teams can't access the features that would benefit them most, and larger teams absorb costs that compound quickly at scale.
Second, the context gap. PagerDuty's AI focuses on signal correlation and noise reduction, which is valuable. But it doesn't have visibility into your incident conversation, your team's decisions during response, or your historical post-mortem data. It can tell you that three alerts are related. It can't tell you that the last three times this pattern appeared, the fix was a specific configuration rollback documented in an older post-mortem.
We built our AI on the incident data we capture: timelines, pinned messages, Scribe transcripts, and historical post-mortems. The AI assistant surfaces relevant context from similar past incidents. AI-suggested summaries keep stakeholders updated without pulling engineers away from troubleshooting. AI-suggested follow-ups generate action items automatically from the incident timeline. The AI has context because we captured the data during your incident, not just the alert signals. Rory Malcolm, a product engineer at incident.io, walks through how incident.io built AI with incident context in mind from the ground up.
7. Support feels transactional, not collaborative
PagerDuty's support model has shifted as the company scaled. For teams on non-enterprise plans, you get asynchronous ticket responses during business hours. When production is down at 3 AM, that response window is the wrong answer.
The frustration shows up consistently in user reviews across G2 and Capterra, alongside pricing and configuration complexity as the most common factors driving teams to evaluate alternatives.
We operate differently. Customers get direct access to a shared Slack channel with our engineering team, a support model built around real-time conversation rather than ticket queues. Bugs you raise get resolved quickly, without the delays typical of ticket-based support queues. When you're evaluating the platform, our support responsiveness is something you can see, not just a promise.
"I personally have been spoiled by their customer support, it makes every other customer support process seem like a chore." - Pablo P. on G2
The support model matters most during a migration. If you're rebuilding your on-call process and something breaks on a Friday night, the difference between a Slack response in 30 minutes and a ticket queue is material.
How to evaluate the switch without the risk
The "rip and replace" fear is legitimate. Incidents don't pause for tool migrations, and your team can't afford a gap in coverage while you switch. A parallel approach works better:
- Keep PagerDuty for alerting initially. PagerDuty is the smoke detector. incident.io is the fire response team. They complement each other. incident.io ingests PagerDuty alerts via webhook, so your existing escalation policies keep working while you build the new coordination workflow in Slack.
- Run your first real incident through incident.io quickly. Not a drill. Connect Datadog or your primary monitoring tool, configure one on-call schedule, and let the next actual incident run through the new workflow. Teams reach their first live incident through incident.io faster than most expect, often within days of connecting their monitoring stack.
- Measure MTTR against your baseline. Take your last 30-day MTTR average before the trial. Compare it after 30 days with incident.io handling coordination.
One additional factor worth noting in 2026: Atlassian stopped new Opsgenie purchases on June 4, 2025, and the Opsgenie shutdown in April 2027 is confirmed. Atlassian is pushing users toward Jira Service Management, which most engineering teams describe as a ticketing system with alerting layered on top, not a purpose-built incident management platform. If you're migrating from Opsgenie, the window is now. If you're on PagerDuty and watching that situation, it's a useful reminder that "industry standard" is not the same as "future-proof."
"I'm new to incident.io since starting on a new job, after many years using Atlassian's Statuspage and PagerDuty. Three things that I believe are done very well in incident.io: integration with other apps and platforms, holistic approach to incident alerting and notifications, and customer/technical support. It's on a very different level (much better) from other vendors." - Verified user review of incident.io
You don't need a better pager. You need a better process. PagerDuty solved getting you out of bed. We solve everything that happens after you wake up.
Book a demo to walk through the alert-to-post-mortem lifecycle with a real engineering scenario.
Key terms
MTTR (Mean Time To Resolution): The average time from incident declaration to resolution. Reducing MTTR by 30% across 20 incidents per month at a loaded engineering cost of $150/hour saves approximately $4,500 per month in engineering time alone.
Context switch tax: The time cost of moving between tools during an incident. Toggling between PagerDuty, Slack, Jira, Google Docs, and Statuspage adds 10-15 minutes of logistics overhead to every incident before troubleshooting begins.
Slack-native: Tools built to run entirely inside Slack using slash commands and channel workflows, rather than tools that send Slack notifications but require a separate web UI for core functions.
Post-mortem: A structured document written after an incident that captures the timeline, root cause, contributing factors, and follow-up actions. High-quality post-mortems published within 24 hours are the primary mechanism for reducing incident frequency over time.
AI Scribe: incident.io's real-time call transcription feature that joins Zoom and Google Meet calls during incidents, transcribes decisions and actions as they happen, and posts structured summaries to the incident Slack channel automatically.
Catalog-aware alerting: Alerting that automatically enriches notifications with service ownership, recent deployment history, and related runbooks from a service catalog, eliminating the manual context-gathering step at the start of every incident.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

