incident.io vs Rootly: Head-to-head comparison for Slack-native teams
April 3, 2026 — 21 min read
Updated Apr 3, 2026
TL;DR: If your team wastes 15 minutes per incident juggling alerts, Jira, and Slack, the decision comes down to one question: do you need a platform that works out of the box, or one you can configure around complex, bespoke runbooks? incident.io is an opinionated, Slack-native platform with preconfigured incident commands and automation that reduces MTTR by up to 80%, automates up to 80% of incident response through AI-assisted triage, investigation, and documentation, and offers transparent pricing so your team reduces on-call cognitive load from day one. Rootly is a configurable automation engine built around conditional logic and multi-tool integrations for teams with complex, non-standard workflows, but requires more setup and ongoing maintenance to reach full effectiveness.
During a database outage, one SRE team discovered the actual technical resolution was fast. The real time drain was coordination overhead: hunting down the DBA on-call, manually spinning up a Zoom link, and watching a critical fix get buried in a Slack thread nobody noticed because half the team was watching the call. The post-mortem, reconstructed days later from memory, missed the key decision point that would have prevented recurrence.
You're evaluating Rootly and incident.io to stop exactly that kind of overhead. Both promise Slack-native incident workflows, but their philosophies differ sharply:
Rootly gives you an automation engine with conditional logic, triggers, and multi-tool integrations for complex, multi-tool processes, while incident.io gives you an opinionated, unified platform built to run incidents primarily inside Slack without requiring weeks of configuration.
Here is a direct comparison across Slack integration depth, timeline automation, AI capabilities, pricing, and MTTR impact.
Choose your platform: incident.io vs Rootly
The table below covers the criteria SRE leads weigh most to identify which platform reduces MTTR fastest.
| Feature | incident.io | Rootly |
|---|---|---|
| Slack-native workflow | Full incident lifecycle via /inc commands, web UI used for config and analytics | Web-first platform with Slack notifications and some workflow triggers |
| AI capabilities | AI SRE: multi-agent root cause analysis, fix PR generation, and incident response automation | AI-assisted incident summarization and alert correlation |
| Post-mortem automation | 80% drafted automatically from captured timeline and call transcriptions | Post-mortem generation available |
| Ease of setup | Operational in 1 to 2 days with opinionated defaults | Setup time varies by configuration complexity |
| Configuration style | Opinionated defaults, limited deep customization | Codeless automation engine with conditional logic and custom triggers |
| Pricing transparency | Public per-user pricing ($25/user/month Pro plan, on-call add-on is $20/user/month) | Contact vendor for pricing details |
| On-call scheduling | Native, included as add-on | Native on-call capabilities |
| Microsoft Teams support | Pro plan and above | Contact vendor for platform support details |
incident.io: MTTR impact and considerations
incident.io uses opinionated defaults that work on day one without custom scripting. The two features that most directly cut MTTR are:
- Command suite:
/inc declare,/inc assign,/inc escalate,/inc severity, and/inc resolveall run in Slack. The incident lead role auto-assigns by default, and our Service Catalog surfaces owners and runbooks inside the incident channel automatically. The web dashboard exists for configuration, analytics, and advanced features, but during a live incident, responders can stay in Slack. - Auto-populating Service Catalog: When an alert fires, we surface service ownership directly in the incident channel. Engineers don't need to hunt Confluence for the runbook or track down the service owner in a spreadsheet.
Rootly: value and trade-offs for SREs
Rootly's automation engine supports multi-step workflows across tools, which suits teams with complex, bespoke processes. Two specific capabilities that differentiate it:
- Workflow automation: Rootly offers automation capabilities for incident workflows. Rootly configures integrations across multiple tools (such as Jira, Slack, and PagerDuty) within a single workflow. Configuration complexity varies by use case.
- Monitoring integration: Rootly integrates with monitoring platforms like Datadog to enhance post-mortem documentation, merging metrics and charts directly into the document for automated inclusion of relevant data.
The trade-off is ongoing maintenance, which increases as workflows grow in complexity. Rootly is designed for mature SRE organizations that want to build highly customized automation engines. G2 reviewers report the UI can feel overwhelming when numerous workflows accumulate, and complex configurations require ongoing attention as tool APIs change.
Pros and cons summary:
| incident.io | Rootly | |
|---|---|---|
| Pros | Opinionated defaults, Slack-native setup, live in 1-2 days; transparent pricing, AI SRE with fix PRs | Customizable automation capabilities |
| Cons | Less customizable for complex multi-tool workflows | Configuration maintenance burden for complex workflows |
Slack integration depth: how native is native?
You need to understand the architectural difference between a Slack integration and a Slack-native platform. An integration sends notifications from a web application into Slack and requires engineers to click a link, open a browser tab, and act in a separate UI. A Slack-native platform enables teams to manage much of the incident response workflow directly in Slack, reducing context switching between tools during critical incidents.
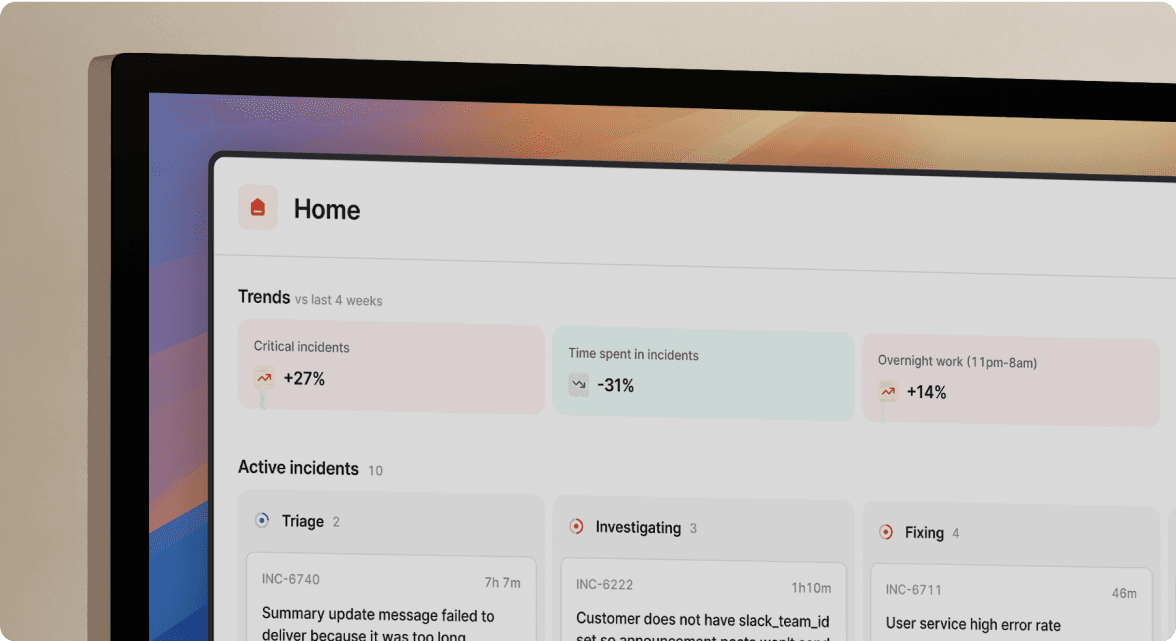
incident.io's streamlined Slack incident flow
When a Datadog alert fires, incident.io automatically creates a dedicated channel like #inc-2847-api-latency-spike, pages the on-call engineer, pulls in the service owner from the Service Catalog, and starts recording the timeline, before responders need to take manual setup steps. From that point, the core response happens in Slack.
The key /inc commands your team will use in every incident:
/inc declare/inc assignrole lead @engineerto assign the incident lead- Common
/inc severity highcommands help teams manage severity, escalations, and incident resolution directly from Slack /inc escalate/inc resolve
"incident.io brings calm to chaos... Incident.io is now the backbone of our response, making communication easier, the delegation of roles and responsibilities extremely clear, and follow-ups accounted for. It's the source of truth for incidents we've always needed." - Braedon G. on G2
Managing incidents with Rootly in Slack
Rootly offers Slack integration for incident management. For standard incidents, Rootly delivers a comparable experience through Slack integration. The difference emerges when you need advanced workflows: Rootly's conditional logic and custom automation rules can be configured via the web interface. You can explore Rootly's Slack integration capabilities in their product documentation.
Reduce incident coordination time
Our auto-created channels and pre-populated service context mean responders can begin troubleshooting quickly. Rootly's channel creation is also automated, but teams needing complex multi-tool routing will need additional configuration time before reaching the same automation level. If your highest-value outcome is reducing coordination overhead immediately without a configuration sprint, incident.io reaches that state faster.
Audit-ready timelines and blameless post-mortems
Manual timeline reconstruction takes 60 to 90 minutes per major incident: scrolling through Slack threads, reviewing Zoom recordings, and cross-referencing memory with Jira timestamps. That time comes out of the next sprint. As we've written about in detail, the post-mortem problem is rarely a documentation skills failure; it's a data capture failure.
Slack-native incident timeline capture
We built Scribe, incident.io's call recording and transcription feature, to automatically join incident calls and capture what matters in real time: detailed notes, summaries, key moments, and the current topic, all fed into the incident channel. Scribe actively pulls key moments from call transcripts into the incident channel, flagging decisions like "we're triggering a rollback" or "new information points to the payment service" as named events in the timeline. When someone joins late, they get up to speed from the timeline rather than interrupting the call to ask what's happened. Scribe significantly reduces the need for a dedicated note-taker, keeping every engineer focused on the technical problem instead.
Rootly's post-mortem documentation
Rootly auto-generates a post-mortem as soon as an incident resolves, populated with the timeline, key metrics, and chat logs. Its standout capability is Datadog integration: it merges charts and metrics directly into the document, so the post-mortem contains embedded telemetry without manual screenshot pasting. For teams whose post-mortems live primarily in a Google Doc with graphs, this is a genuine time saver. The depth of Rootly's post-mortems depends on how much you've pre-configured the data field mappings in your workflows.
AI post-mortem accuracy and completeness
Our AI drafts post-mortems from the captured timeline, call transcriptions, and key decisions logged during the incident, significantly reducing the manual writing burden. Engineers focus on refining and adding context rather than writing from scratch. Rootly generates post-mortems from structured timeline data and embeds richer telemetry charts, but narrative completeness depends on the quality of configured data mappings. Both are meaningfully better than a blank Google Doc at midnight.
AI's precision in root cause detection
The practical question for SRE leads is whether the AI identifies the specific code change or service dependency behind an incident and suggests a concrete next step, rather than returning a list of potentially related log lines.
incident.io AI: smart root cause guidance
We built our AI SRE using a multi-agent system that searches across multiple data sources including code repositories, communication channels, historical incidents, and telemetry data to build root cause hypotheses. The system presents an actionable investigation report in Slack with concrete findings backed by evidence and suggested next steps.
A practical example: an API latency spike fires during an active on-call shift. The AI SRE checks recent deployments, identifies a recently merged PR that modified the database connection pool configuration, and surfaces it as the primary hypothesis before the on-call engineer has typed their first message, acting as a co-pilot rather than a reporting tool.
incident.io's AI is used across various customer environments, though specific precision metrics are not publicly available.
Rootly's AI approach
Rootly's AI suite covers summarization, intelligent routing, and root cause suggestions, integrated throughout the workflow rather than added as a separate module. It provides summaries to new responders joining an active incident and flags probable causes based on the incident timeline and monitoring data.
Tool connections: plug-and-play setup
incident.io connects to Datadog, Prometheus, New Relic, Grafana, and PagerDuty without custom scripting, surfacing alert context inside the incident channel automatically. We provide migration guides for PagerDuty and Opsgenie covering schedule imports and routing configuration. Rootly provides connections to common monitoring and alerting platforms, though complex conditional routing requires more web UI configuration time.
Both platforms create Jira and Linear tickets automatically when incidents resolve. Our Linear integration exports follow-ups and creates tickets in Linear to track post-incident work. Rootly's codeless automation engine handles more complex Jira routing scenarios, including field mapping and project-specific templates.
Our opinionated defaults mean most teams handle real incidents within three days of signup.
Rootly's standard setup is achievable quickly for simple workflows, but complex multi-tool automation requires more pre-build time before those workflows run reliably.
Pricing models: incident.io vs. Rootly
Transparent pricing matters more than it might seem at contract renewal time. An unexpected add-on discovered during a budget review creates friction with Finance and erodes trust in the vendor relationship.
incident.io per-user cost and plans
Our Pro plan pricing is fully public:
- Incident response: $25/user/month
- On-call add-on: $20/user/month
- Total with on-call: $45/user/month
We separate the on-call add-on from the base Pro price because most SRE teams need on-call scheduling. Use $45/user/month as your planning number. That's the honest total-cost figure to bring into budget conversations, and we'd rather you know it now than discover it later.
Rootly's pricing structure
Rootly does not publish per-user rates on their website, which makes self-serve cost estimation more difficult during the evaluation phase.
Real TCO: 25 vs. 100 on-call engineers
Here's the incident.io Pro plan math at two common team sizes:
| Team size | Monthly cost | Annual cost |
|---|---|---|
| 25 engineers | 25 × $45 = $1,125/month | $13,500/year |
| 100 engineers | 100 × $45 = $4,500/month | $54,000/year |
Rootly requires a direct quote to produce equivalent numbers. If budget predictability is a priority for your VP of Engineering or Finance, our published pricing removes one variable from the approval process.
MTTR impact: measured outcomes from real teams
Favor's engineering team reduced MTTR by 37% and increased incident detection by 214% after adopting incident.io. The MTTR reduction traces to two changes: auto-created channels that eliminated manual team assembly delays, and automatic timeline capture that removed the post-incident reconstruction burden. While trivial and minor incidents increased as teams caught issues earlier, major and critical incidents dropped significantly.
Centering incident management in Slack removes the question of "which tool do I open next" from the responder's mental stack entirely. The Slack-native interface, including /inc commands, helps new on-call engineers adopt the workflow more quickly, and the Service Catalog surfaces the right runbook inside the incident channel automatically.
Intercom reduced MTTR and resolved incidents faster after switching to incident.io, driven by automated summaries, real-time highlights, and auto-created channels. Torq consolidated fragmented tooling and achieved MTTR reduction, as detailed in the Torq case study.
Rootly: complex workflow automation
Rootly reduces MTTR by eliminating manual steps in complex, multi-tool workflows. For teams with bespoke processes requiring conditional logic across multiple tools, Rootly's codeless engine can meaningfully reduce toil. The platform provides analytics that help SRE leads identify patterns across incident categories, supporting proactive reliability investments.
Cognitive load reduction
Both platforms reduce on-call burnout by removing process toil. We focus on eliminating tool-switching overhead so engineers can focus on the technical problem. Rootly reduces load by automating complex decision trees that would otherwise require senior engineers to guide junior responders through. The choice depends on whether your cognitive load problem is primarily coordination overhead (incident.io's strength) or complex workflow execution (Rootly has an edge).
Where each platform falls short for SREs
Pricing transparency gaps
The on-call add-on costs $20/user/month on top of the $25 base Pro plan. We document this clearly on the pricing page, but teams that don't read carefully face a surprise at budget sign-off. Rootly's approach, where per-user rates aren't publicly listed, creates a different problem: you can't self-serve a cost estimate without a sales call, which adds friction to the evaluation process.
Rootly: maintenance overhead
Rootly's highly configurable approach creates a specific operational risk. When your automation engine relies on complex custom workflows, those workflows can break when upstream tool APIs change, and the institutional knowledge of how the automation was built often lives with one engineer. If that engineer leaves, the maintenance debt lands on whoever is next on-call. Our opinionated defaults mean less surface area for breakage and no custom logic for a departing engineer to take with them.
"They have built a system with sane defaults and building blocks to customize everything. Their product is responsive and reliable, and the new features are all well thought out." - Bertrand J. on G2
incident.io vs Rootly: your team's best fit
Automate post-mortems and cut MTTR
Choose incident.io if your primary pain is coordination overhead: the minutes lost assembling the team, the 90 minutes spent reconstructing post-mortems from Slack scroll-back, and the junior engineer who freezes on their first on-call shift because the process lives in someone else's head. Our opinionated defaults get you operational in three days, the AI SRE automates up to 80% of incident response, and transparent pricing at $45/user/month with on-call removes budget surprises. For teams also evaluating their broader incident management stack, our runbook automation guide covers how these components fit together.
Rootly: automate complex incident workflows
Choose Rootly if your team runs highly bespoke incident processes requiring complex conditional logic across multiple tools, and you have a dedicated engineer to build and maintain those automation workflows. Rootly's codeless engine handles scenarios that our opinionated defaults can't accommodate, and its Datadog-embedded post-mortems are genuinely richer for monitoring-heavy teams. The trade-off is setup time, ongoing maintenance, and pricing that requires a sales conversation to quantify.
Running your incident platform POC
The fastest way to make this decision is to run a real incident in both platforms.Schedule a demo and we'll show you how engineering teams reduce MTTR by up to 80% and walk through exactly how incident.io gets you there, from alert to resolution, without leaving Slack.
Key terms glossary
AI SRE
incident.io's AI-powered assistant that automates up to 80% of incident response tasks, including timeline capture, stakeholder updates, and post-mortem drafts. It handles coordination overhead so your engineers focus on the fix, not the paperwork.
MTTR (Mean Time To Resolution)
The average time from when an incident is detected to when it is fully resolved. MTTR is the primary benchmark for incident response performance. Reducing MTTR by eliminating coordination overhead is one of the fastest ways to improve reliability without adding headcount.
POC (Proof of Concept)
A time-boxed evaluation of a tool or process in a real or simulated environment. For incident management, a POC typically runs two to four weeks and measures MTTR impact, adoption rate, and integration reliability before full rollout.
Post-mortem
A structured document written after an incident that records what happened, why it happened, and what steps will prevent recurrence. Post-mortems are blameless by design and focus on system failures, not individual errors. incident.io uses "post-mortem" consistently not "retrospective" or "post-incident review."
Root cause analysis (RCA)
The process of identifying the underlying system, process, or configuration failure that triggered an incident. RCA goes deeper than the immediate symptom to find the contributing factor that, if addressed, prevents the same incident from recurring.
Scribe
The role responsible for capturing the incident timeline in real time during an active response. A scribe records key actions, decisions, and findings as they happen, so the post-mortem can be written from fact rather than memory.
SRE (Site Reliability Engineer)
An engineer responsible for the reliability, availability, and performance of production systems. SREs design and maintain on-call processes, set SLOs, run post-mortems, and reduce MTTR through both tooling improvements and cultural practices.
TCO (Total Cost of Ownership)
The full cost of adopting and running a tool, including licensing fees, implementation time, training, integration work, and ongoing maintenance. TCO comparisons are more accurate than per-seat price comparisons when evaluating incident management platforms.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

