Customers over control: how we measure On-call reliability
May 28, 2026 — 12 min read

Our On-call product has a lot of great features: configuring escalation paths, viewing rotas and schedules, requesting cover, etc. However, when framing its reliability, we reduce it down to two critical pieces of functionality:
- Ingesting alerts. An alert is a message we receive from a customer’s observability tooling to tell us that they think something is wrong and needs attention.
- Sending timely notifications to on-call responders so that they can investigate.
It’s not that we’re happy if only these parts are working, but they are the most important parts.
In this post, I'll go into more detail on how we think about their reliability. Specifically, I want to talk about how we put customers at the centre of our reliability thinking. It’s easy to think about reliability from a purely technical perspective, especially for engineers. A customer-driven approach is in the DNA of incident.io, and hopefully I can use this post to show how it improves outcomes all round.
This post assumes knowledge of Service Level Objectives. The Google SRE book is the oft-cited bible, and their intro is pretty good, but I find the rest of it quite a slog, so here’s the gist:
- Service Level Indicator (SLI): a quantitative measure of how the service is actually behaving (e.g. latency, error rate, availability) - the raw signal.
- Service Level Objective (SLO): a target we set for an SLI internally (e.g. "99.9% availability over 30 days") - what "good" looks like.
- Service Level Agreement (SLA): a formal, often contractual commitment to customers based on SLOs, with consequences (e.g. service credits) if we miss it.
How we frame On-call reliability
We model the reliability of the On-call product using two SLIs that cover the two main functions above:
- Alert ingestion availability: a classic HTTP API availability SLI; what proportion of requests we successfully process.
- Notification delivery latency <5m: the proportion of notifications we dispatch “on time”.
Internally, we target a 99.99% monthly SLO for both, with an almost perfect record over the last 12 months:
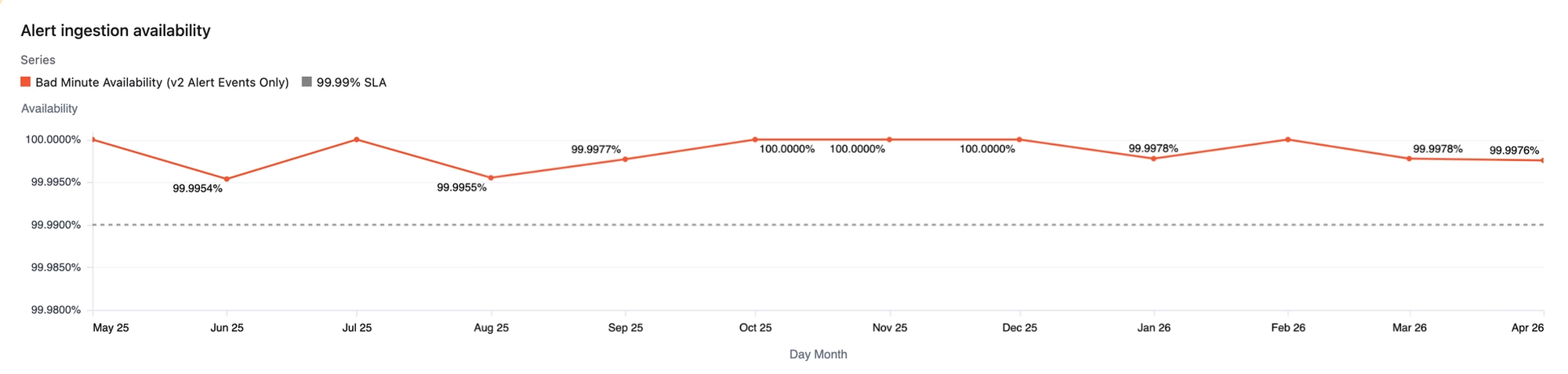
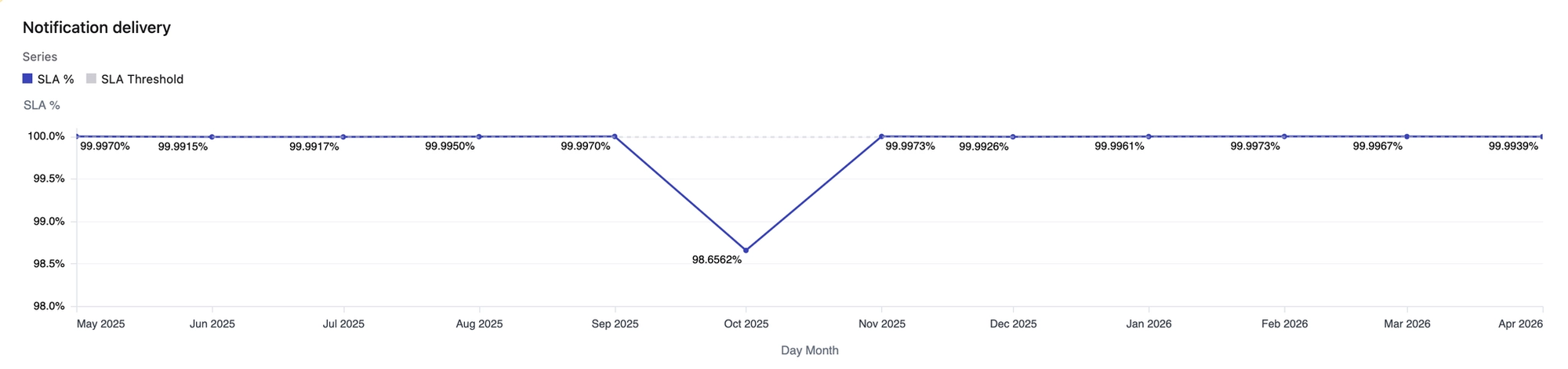
Notifications were delayed in October 2025 by an AWS outage. We learned from this and made improvements, and there’s more on this later in the post.
Our platform is architected with reliability at its core. This is a simplified diagram to illustrate my point - there are many more components, and all of them are replicated:
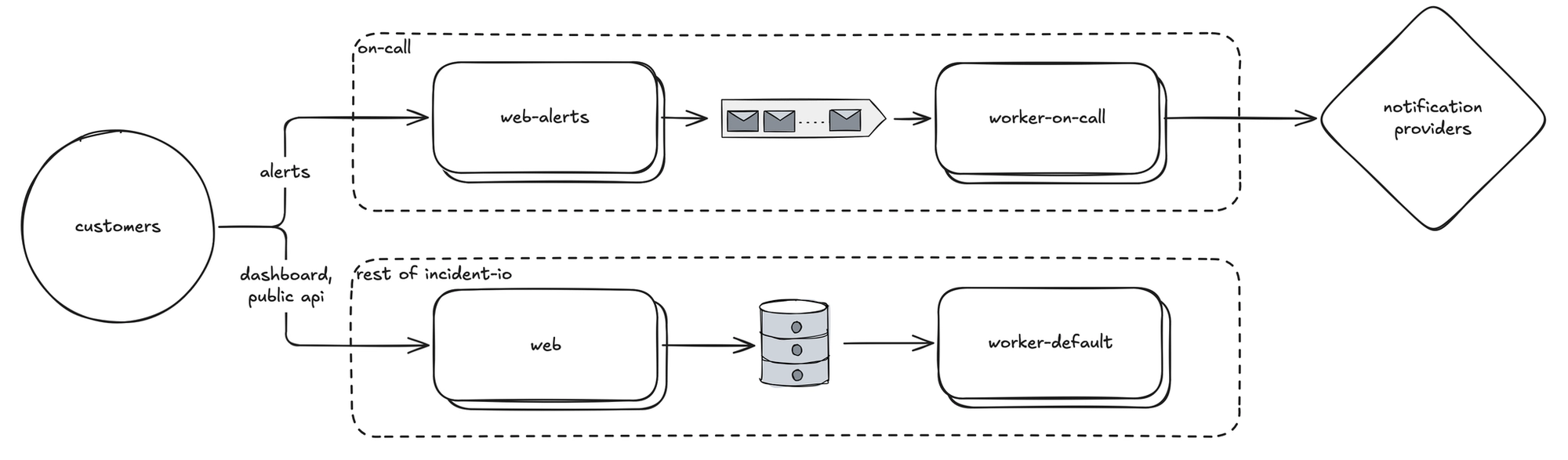
- We use a lightweight ingestion layer to durably write alerts to a queue (
web-alerts). - An async system of message producers and subscribers then applies routing configuration and sends notifications, so we never drop work (
worker-on-call). - All of this runs on dedicated infrastructure, isolated from the rest of the platform.
So far, this all seems pretty simple! However, we don’t have to poke at those SLI definitions much before we unearth some complexity.
Alert ingestion: measuring what customers feel
I introduced this SLI as “a classic HTTP API availability SLI”:
1 - 5xx responses / total responses
We observe responses at the point closest to the customer that we can, which for us is a GCP load balancer. Requests have a few hops to make between the load balancer and our application layer, and we want to make sure the SLI covers all of that. If we misconfigure our load balancer and route requests to the wrong place, application-level metrics will show low error rates because there are no requests to return errors for!
We alert on per-request error rates at this layer and proactively investigate. That means whenever a transient network blip occurs, one of us wakes up and checks everything is OK. This happens very rarely and, in the vast majority of cases, a self-healing system quickly takes care of it.
There are multiple components covered by our alerting that we’re not directly in control of. For example, the load balancer and Kubernetes control plane are operated by GCP. Measuring and alerting like this has helped us identify and fix issues that are “outside” of our stack but that impact alert ingestion.
When we frame the reliability of alert ingestion, we don’t want to include this “noise” in the signal. What we actually measure is good minutes / total minutes:
- Slice the month up into minutes.
- Measure the error rate for each minute.
- “Good” minutes have an error rate <10%.
This approach means that short-lived, self-healing blips are considered part of the norm. When the SLI is <100%, customers have been meaningfully impacted. It also encourages customers to ensure that their alert dispatching systems are designed with this level of fault tolerance in mind, for example, by using retries with backoff. We hold ourselves to a high standard, but this realistic view of complex systems is how we maximise our chances of ingesting alerts.
Third-party dependencies: when “not our fault” isn't good enough
Now let's poke at notification delivery latency. We target dispatching notifications within 5 minutes of ingesting an alert — but when does the clock actually stop?
The easy answer: when we hand the notification off to a provider like Twilio or APNs. If they're degraded, that's not our fault. Right?
It’s easy to fall into debating “whose fault should this be” when thinking about dependencies between systems.
We focus on customer experience — how do we make sure you get paged?
For SMS and phone calls, we run two telecom providers active-active. If one can't dispatch, we try the other. This is exactly the gap we closed after missing our SLO in October 2025, when our sole telecom provider was caught up in the AWS outage. (This gap was actually a known risk and we had work planned, but it bit us before we got to it.)
Some providers are monolithic — there's only one APNs API for iOS push notifications, so we can't run redundancy ourselves. Instead, the product nudges users to layer multiple notification methods (push and SMS and phone), so we always have another way to reach them.
So "dispatched on time" means acknowledged by any provider within 5 minutes. We own redundancy on our side; we encourage it on the customer's side. That combination is what makes a notification reliable.
User-configured delays: measuring the bits that are hard to measure
Our notification delivery latency SLO measures the time it takes for a notification to be delivered from the moment an alert is ingested at the edge. However, our On-call product supports a bunch of different ways for customers to introduce “delay” into the escalation path:
- If something happens overnight, isn’t important enough to wake someone up, but does need looking at, you can delay an escalation until working hours begin.
- If you configure alert grouping, we’ll wait a little bit before notifying you, so that we have a window to check for duplicate alerts. This allows us to only notify a user once when many alerts come in for the same reason.
My favourite - users can define delays in their notification rules. Here are mine:
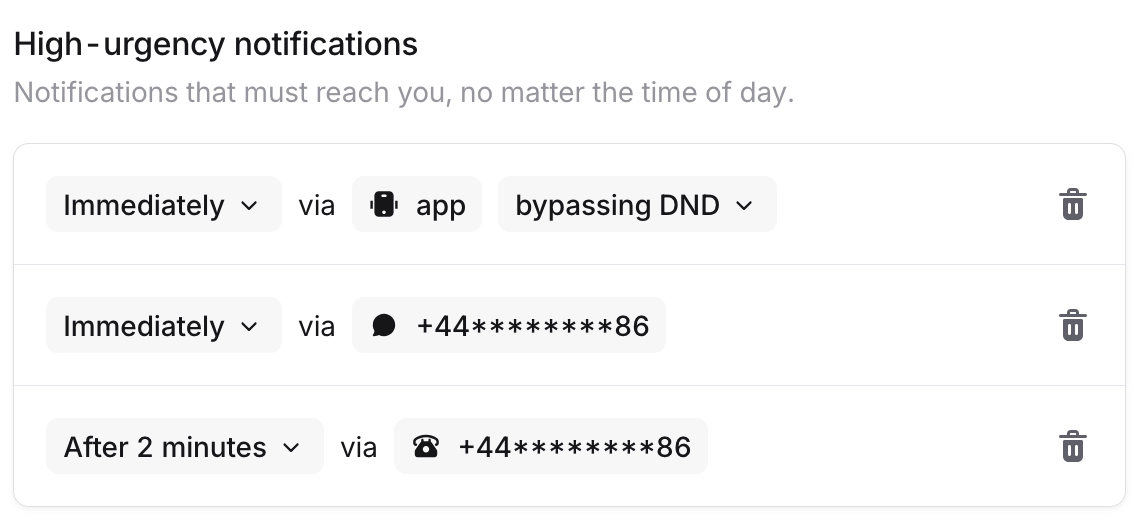
- Whenever I’m being paged, I immediately get a push notification and SMS. Having two methods gives me some redundancy. I get notified on my smartwatch, which has a good chance of waking me up, and a low chance of waking my wife up.
- After 2 minutes I get a phone call. This is another layer of redundancy, both in notification methods, and for if I accidentally go back to sleep after the first round of notifications. This has a high chance of waking me up properly, but will also probably wake up my wife.
Being able to layer up notification methods based on how “disruptive” they are is a really useful tool. It adds up to a significant quality of life improvement in my house over a week of being on call!
From the moment an alert is ingested, incident.io owes me some notifications immediately, and some a few minutes later (redundancy is the exception, not the rule). If there’s something wrong with our system and notifications are delayed, it’s easy to detect against the immediate notifications. It’s tricky for us to measure the latency of any that include intentional delay - it’s been intentionally latent. The system hasn’t been designed to be observed in this way.
The simplest option here would be to say that we only care about the reliability of “immediate” notifications. They’re the ones that matter most, right? My notification settings are cute, but I should be getting up when I receive the first one; the rest is on me.
We disagree! In the previous section we covered the best practice of having multiple notification methods set up for redundancy. This “retry with backoff” approach is another form of redundancy that we encourage. If my watch doesn’t wake me up, and I don’t get my phone call until 20 minutes later due to an issue in incident.io’s notification systems, and now things are really on fire, that’s not good enough.
The excuse that this is hard for us to measure doesn’t pass the “red face test”. We’d be embarrassed to tell a customer that a delayed notification wasn’t our fault, because they introduced a delay, when we’re the ones that told them that this is best practice!
Calculating notification delivery latency then looks like:
- Pick a start time - usually when an alert is ingested, but there’s other cases like manual escalations.
- Pick an end time - the first time we get an acknowledgement from any of our notification providers.
- Calculate “configured delays” - sum up all the different ways you could have delayed the notification on purpose (there’s a lot and it’s some truly spectacular BigQuery SQL).
latency = end time - start time - configured delays
Any time between start and end that wasn’t intentionally introduced is our processing time and should be as fast as possible.
Reliability is a customer experience problem
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
In all three scenarios above, this produces the best outcomes:
- Instead of focussing on our API being “up”, we instead have to think about maximising the chance an alert is received and ingested successfully.
- Instead of saying “that’s not in our control” when a third-party dependency is degraded, we instead proactively assume they will go down, and design a system specifically to cope with it.
- Instead of saying “ugh, that’s going to be really hard to measure”, we embrace the complexity, deliver a better experience, and ensure our customers don’t have to pay the price.
In a world of metrics and uptime graphs, it’s easy to get sucked into narrowly measuring whether an individual component is ”up”, and forget that it’s a key part of a customer experience.
Customer outcomes matter more than any individual piece of the machine, and we aim to always build and measure our platform with that in mind.

Mike Fisher
Product Engineer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

