Best incident postmortem software for retail teams: A 2026 guide
February 5, 2026 — 24 min read
Updated February 5, 2026
TL;DR: Your retail downtime costs between $200,000 and $500,000 per hour, with peak season outages reaching up to $2 million per hour during Black Friday. Generic postmortem tools document server uptime without connecting technical failures to business impact like lost transactions and abandoned carts. We built incident.io to solve this by automating timeline capture during incidents, mapping technical services to business functions through Catalog, and generating business-ready postmortems in minutes instead of hours. Start with tools that answer the executive question "how much revenue did we lose?" not just "what broke?"
When your payment gateway fails during a flash sale, your VP of Engineering doesn't ask "what was the database CPU utilization?" They ask "how many customers couldn't check out?" and "how much revenue did we lose?" Your retail incidents get measured in dollars per minute, not just MTTR. You need postmortem software that bridges the gap between "API timeout at 14:32" and "estimated 847 failed transactions totaling $42,000 in lost revenue."
Your downtime costs between $200,000 and $500,000 per hour if you run a mid-size retail operation, according to 2024 Gartner data. During Black Friday or Cyber Monday, you could lose $1 million to $2 million per hour. For 98% of organizations, a single hour of downtime costs over $100,000, with 81% facing costs exceeding $300,000 per hour. Your current generic incident management tools built for SaaS uptime tracking don't capture this business context automatically, leaving you to reconstruct revenue impact from memory days later when you're writing the postmortem.
We evaluated postmortem platforms specifically for your retail and e-commerce operations, focusing on tools that track customer-facing impact, integrate with your payment and inventory systems, and generate reports your CFO can understand without a computer science degree.
Why retail incident management requires specialized postmortems
Your retail incidents have a different anatomy than typical SaaS outages. A database slowdown at a B2B software company might delay some background jobs. The same issue at your e-commerce site during prime shopping hours means hundreds of customers hitting "Place Order" and seeing loading spinners instead of confirmation pages. Those customers refresh twice, give up, and go to your competitor. Your revenue doesn't just pause during the outage. It disappears permanently.
Customer impact tracking and business reporting
You need to quantify "lost baskets" versus just "downtime duration." If you run an organization, a single hour of your downtime costs over $100,000 for 98% of companies, with 81% facing costs exceeding $300,000 per hour. During a payment system incident, you calculate specific losses: number of failed transactions multiplied by average order value, plus the downstream cost of customer acquisition to replace the shoppers who never returned.
Your generic monitoring tools track technical metrics like response times and error rates. Your retail postmortems need to answer business questions: How many customers tried to check out? How many succeeded versus failed? What was the average cart value for failed transactions? Did support ticket volume spike, indicating frustrated customers reaching out? Application Performance Monitoring solutions with auto-discovery of application topology help you understand the full delivery chain, but you still need postmortem software that connects these technical alerts to business outcomes automatically.
Integration with payment and inventory systems
Your e-commerce platform depends on complex third-party integrations. Your checkout flow might involve Stripe or PayPal for payment processing, Shopify or custom cart systems for transaction management, third-party logistics providers for inventory visibility, fraud detection services, and tax calculation APIs. Your payment and checkout pages often rely on third-party payment gateway services, with dependencies spanning multiple cloud providers.
When you deal with an incident involving these integrations, failures cascade across your dependent services. A postmortem that only captures your internal service logs misses critical context about what went wrong at the payment gateway or whether inventory synchronization delays caused overselling. You need software that maps these dependencies and automatically pulls relevant data from integrated systems into the incident timeline.
Key features to look for in retail postmortem software
The difference between a useful postmortem and documentation archaeology comes down to automation, context, and enforced processes that work during the chaos of an active incident.
Automated timeline reconstruction
The single biggest time sink in your postmortem creation is reconstructing what happened when. You scroll back through Slack conversations, cross-reference PagerDuty alerts with Datadog dashboards, check GitHub for recent deployments, and try to remember what you said during the incident call 48 hours ago. Manual postmortem creation becomes a hassle you easily forget, according to Atlassian's own documentation about the challenges your team faces.
Automated timeline reconstruction means your postmortem software captures events as they happen: when the first alert fired, who acknowledged it, what actions you and your responders took, status changes, customer communications, and resolution steps. The incident.io timeline provides exact timestamps for all important events including your Slack messages, alerts, status changes, and manual updates. One G2 reviewer noted how incident.io helps respond quickly and learn loads by providing structure to share learnings from incidents, making postmortem tooling simple yet detailed.
"Incident has transformed our incident response to be calm and deliberate. It also ensures that we do proper post-mortems and complete our repair items." - Mike H. on G2
Blameless culture support
Your retail incidents happen under pressure when you're actively losing money. The natural organizational reflex is to find out "who messed up" so it doesn't happen again. This reflex kills psychological safety and prevents your teams from sharing the full truth about what went wrong, which is particularly damaging in your high-pressure retail environment where learning from failures matters more than assigning blame.
Your postmortem software can enforce blameless culture by providing structured templates that focus on system failures rather than individual mistakes. Look for postmortem tools that guide your teams through root cause analysis frameworks like the five whys, automatically flag blame-oriented language in draft postmortems, and ensure follow-up actions focus on process improvements rather than personnel issues. As one incident.io user explained, the platform helps promote a blameless incident culture by promoting clearly defined roles and showing that dealing with an incident is a collective responsibility.
Security and compliance for PCI DSS and SOC 2
If you process credit card payments, PCI DSS requirement 10 stipulates that you must review logs for all system components at least daily, with audit logs retained for at least one year. Requirement 12 mandates that you must safely store all incident response documentation, including detailed procedures and evidence of incident handling.
Your postmortem software becomes part of your compliance documentation. PCI DSS requires you to have an incident response plan, regularly test it, and maintain a log of all security incidents. You must conduct and document a post-mortem or lessons learned to capture successes, failures, or gaps in your incident response plan. Look for platforms with SOC 2 Type II certification, role-based access controls, encrypted data at rest and in transit, and audit trail features that track who viewed or edited sensitive incident documentation.
Top incident postmortem tools for retail and e-commerce
We compared platforms based on automation capabilities, business impact tracking, integration ecosystems, and how well they serve your team when you're handling high-volume retail incidents with direct revenue implications.
incident.io: Best for unified, Slack-native retail operations
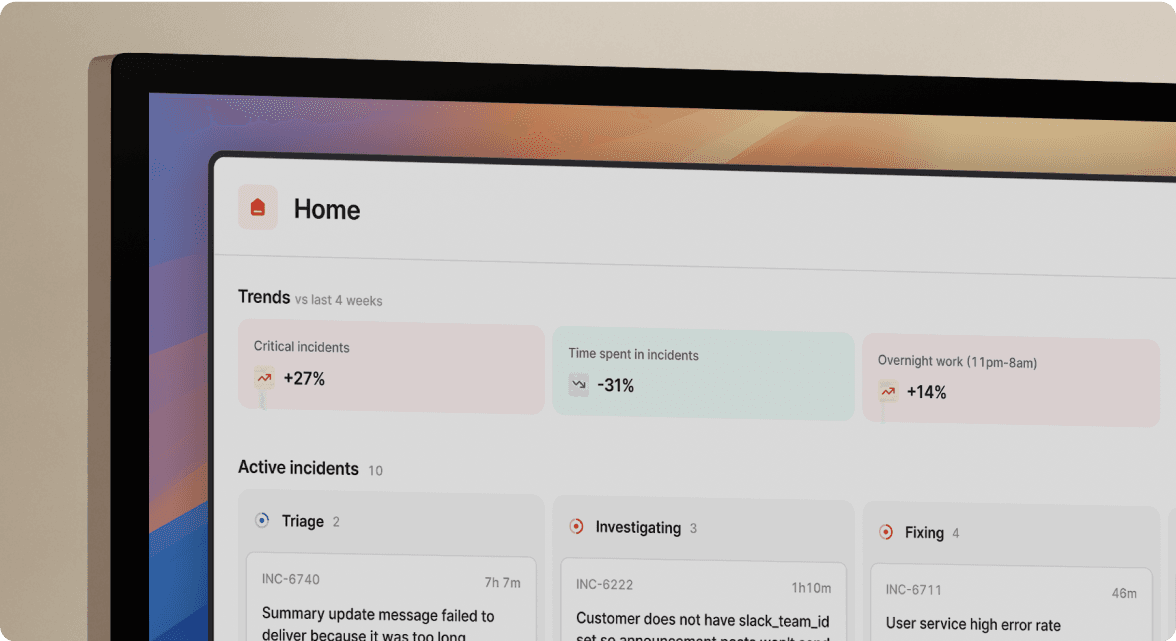
We built the entire postmortem workflow to live in Slack, where your retail engineering team already coordinates during incidents. When an alert fires from Datadog or your monitoring system, incident.io automatically creates dedicated incident channels, pulls in your on-call responders, and begins capturing the timeline without anyone manually taking notes.
You can map your technical services to business functions using the Catalog feature. You define "Checkout Service" as a catalog entry, link it to your payment gateway integration, tag it with the revenue impact level, and associate it with the engineering team that owns it. During an incident affecting checkout, incident.io automatically surfaces this business context for you. When your VP of Engineering asks "which services were affected?" your postmortem already contains that information derived from Catalog relationships, not manually added later.
Our AI SRE handles up to 80% of incident response, pulling data from alerts, telemetry, code changes, and past incidents to identify root causes. Once you resolve the incident, AI SRE drafts the postmortem including timeline, contributing factors, and follow-ups. One user noted that AI SRE summarized their incident call so clearly they pasted it into the postmortem without editing.
Pricing: Our Team plan at $19/user/month (monthly) or $15/user/month (annual) covers incident response with basic features. On-call scheduling adds $12/user/month for the Team plan, bringing your total cost to $31/user/month (monthly) or $25/user/month (annual). Most retail teams need the Pro plan at $25/user/month base plus $20/user/month for on-call, for a total of $45/user/month, which includes Microsoft Teams support, unlimited workflows, AI-powered postmortem generation, and custom incident types.
Pros:
- Zero context switching during incidents, everything happens in Slack
- Catalog connects technical failures to business impact automatically
- AI-generated postmortems save significant manual writing time per incident
- Transparent pricing with no surprise enterprise features behind paywalls
- Fast support velocity shipping features in days, not months
Cons:
- Opinionated workflow design limits customization compared to PagerDuty
- Requires Slack or Microsoft Teams as primary communication platform
- Not built for deep micro-service SLO tracking if that's a priority
"Without incident.io our incident response culture would be caustic, and our process would be chaos. It empowers anybody to raise an incident and helps us quickly coordinate any response across technical, operational and support teams." - Matt B. on G2
PagerDuty: Best for enterprise alerting and legacy stacks
PagerDuty dominates the on-call and alerting market, particularly for large enterprises with complex escalation policies and established processes. If you're running legacy infrastructure or need sophisticated alert routing rules, PagerDuty's maturity shows. However, users report that PagerDuty lacks real incident management functionality beyond alerting and paging, with one reviewer noting "The 'incident management' functionality they advertised wasn't really there. No serious workflow management, terrible visibility, reporting tools too simple and rigid to be valuable."
For your retail team, this limitation matters during the coordination phase of incidents. PagerDuty alerts you that checkout is timing out, but it doesn't help you assemble the response team, capture the timeline, draft the postmortem, or calculate business impact. You still need separate tools for documentation, which brings back the context-switching problem.
Pros:
- Industry-standard alerting with proven reliability
- Massive integration library covering monitoring, ticketing, and communication tools
- Mobile apps rated 4.8 stars on iOS for on-call engineers
Cons:
- Expensive per-seat pricing with critical features behind add-on paywalls
- Post-incident workflow support requires additional products or integrations
- Complex UI requiring training for new team members
Blameless: Best for SRE-focused reliability tracking
Blameless positions itself as the industry's first end-to-end SRE platform, focusing on SLOs, error budgets, and reliability insights. The platform calculates error budgets automatically and ties incidents to service level objectives, making it powerful for organizations practicing formal Site Reliability Engineering.
For your retail team if you're primarily concerned with rapid incident response and business reporting, Blameless may be more than you need. The SLO-first approach works well if you're mature enough to have defined service level objectives for checkout, payment processing, and inventory systems. If you're still working on getting incidents documented consistently and reducing MTTR, the additional reliability engineering features add complexity without immediate value.
Pricing: Essentials plan at $20/user/month for the first 50 users includes integrations, automated workflows, and data retention.
Pros:
- Deep reliability metrics and SLO tracking for mature SRE teams
- Strong postmortem templates and automated workflows
- Good integration with monitoring and incident tools
Cons:
- UI could be more polished and intuitive, particularly for searching and reporting
- Focused on reliability engineering practices that may feel like overkill for coordination-first retail teams
- Separate from alerting, requiring integration with PagerDuty or similar tools
Confluence + Jira: Best for manual documentation storage
Many organizations default to documenting postmortems in Confluence because they already pay for Atlassian products. You create a postmortem template, someone manually fills it out after the incident, link it to Jira tickets for follow-up actions, and file it away in a Confluence space that nobody reads unless preparing for an audit.
This approach costs nothing extra if you're already using Atlassian tools, but the hidden cost is time. For every action from a postmortem, you manually raise a Jira work item in the backlog, link it from the postmortem issue, and hope someone actually completes it. Postmortems need to be both easy to fill in and quick to create in order not to be skipped, yet the manual effort means they often are skipped or completed weeks late when details have faded.
Pros:
- You likely already pay for Confluence and Jira
- Flexible templates let you customize documentation format
- Good for long-term storage and historical searching
Cons:
- 100% manual entry requires significant time investment
- No automatic timeline capture during incidents
- No business impact calculation or integration with monitoring tools
- Easy to skip or delay when team is busy with next incident
Comparison: Key features across platforms
| Feature | incident.io | PagerDuty | Blameless | Confluence + Jira |
|---|---|---|---|---|
| Auto-timeline capture | Yes, captures Slack messages, alerts, and actions in real-time | No, requires manual documentation | Partial, via integrations | No, fully manual |
| Business impact tracking | Yes, via Catalog mapping and Custom Fields | No, technical metrics only | Limited, SLO-focused | No, manual entry only |
| Slack-native | Yes, entire workflow in Slack | No, separate web UI | No, separate web UI | No, separate Confluence UI |
| AI postmortem generation | Yes, AI SRE drafts based on captured data | No | No | No |
| Pricing model | $45/user/month (Pro + on-call) | $40+/user/month with add-ons | $20/user/month for first 50 | Included with Atlassian license |
| Best for | Retail teams needing business reporting | Enterprise alerting | SRE reliability engineering | Budget-conscious manual workflows |
How to conduct a payment system incident postmortem
Payment system incidents require specific investigation steps beyond generic server troubleshooting because they involve third-party services, sensitive transaction data, and clear financial impact.
Specific data points to investigate
Start with your transaction logs from your payment gateway showing request IDs, timestamps, response codes, and failure reasons. Payment gateway failures during your high-traffic sales events lead to transaction failures, so compare your normal transaction volume to incident period volume. Check for HTTP status codes: 502/503/504 indicate gateway unavailability, 429 indicates rate limiting, 400-series codes suggest malformed requests potentially from your recent code changes.
Review your fraud detection logs for false positive spikes. Sometimes your fraud systems become overly aggressive during unusual traffic patterns, blocking legitimate customers. Cross-reference your internal application logs with payment gateway API logs to identify where the failure occurred, whether in your checkout service, network layer, or the payment provider's infrastructure.
Quantifying the blast radius
Calculate your affected users versus total traffic during the incident window. If 10,000 users hit your checkout page during a 30-minute outage and 2,000 successfully completed transactions, your blast radius is 8,000 affected users (80% failure rate). Multiply those 8,000 users by your average order value to estimate lost revenue.
You can use a standard industry formula to calculate lost profits: (annual revenue / annual operating hours) x hours of downtime. Shopify recommends a simpler approach: multiply your average hourly revenue by the number of downtime hours. For a typical e-commerce site generating $50,000 per hour during peak times, a 1-hour outage costs $50,000 in immediate revenue. During non-peak hours, the same site might generate $15,000 per hour, making a 1-hour outage cost $15,000.
If you use incident.io, the Custom Fields feature lets you tag incidents with "Revenue Impact" estimates that automatically populate in your postmortems and executive dashboards. The platform allows you to escalate incidents to executives based on severity or affected surfaces, ensuring business leadership has visibility into significant incidents.
Building a blameless culture in high-pressure retail environments
Your retail incidents happen when you're losing money in real time, creating organizational pressure to find someone responsible. This pressure undermines the psychological safety you need for honest postmortems that lead to systemic improvements.
The five whys technique for retail
The five whys technique moves from surface symptoms to underlying process failures by asking "why" repeatedly until you reach a root cause. Here's how you apply the five whys to a retail checkout incident your team might face:
Problem: The checkout system crashed during peak traffic, preventing customers from completing purchases.
- Why did the checkout system crash? The payment processing service became unresponsive
- Why did the payment service become unresponsive? The service reached its maximum number of concurrent connections
- Why did it reach connection limits? The load balancer failed to distribute traffic properly
- Why did the load balancer fail? The configuration was incorrect, routing too much traffic to one server
- Why was the configuration incorrect? A recent update to the load balancer was not properly tested
Root cause: Insufficient testing of configuration changes in the load balancing system. The fix isn't "fire the person who deployed the bad config" but rather "implement staging environment parity and require load testing for infrastructure changes."
Choosing the right postmortem software for your retail team
Pick your postmortem tool based on your team size, incident frequency, and whether you need business impact tracking or pure technical documentation.
Choose incident.io if:
- You handle 10+ incidents monthly and want to eliminate manual timeline reconstruction
- Your executives need to understand business impact, not just technical root causes
- You want everything to happen in Slack without context switching
- You value fast support and regular product improvements
Choose PagerDuty if:
- Alerting and on-call management are your primary needs
- You already use PagerDuty and need incremental incident coordination improvements
- You're a large enterprise requiring extensive customization and legacy integrations
Choose Blameless if:
- Your team practices formal SRE methodology with defined SLOs and error budgets
- Reliability engineering maturity is more important than coordination speed
- You want deep reliability metrics beyond incident response
Choose Confluence + Jira if:
- You handle fewer than 5 incidents per month and manual documentation is sustainable
- Budget constraints prevent new tool adoption
- You need maximum documentation flexibility and already pay for Atlassian
Schedule a demo to see how automated timeline capture and AI-drafted postmortems work for retail incidents. You'll see in a 30-minute session whether the time savings justifies the investment. For your retail and e-commerce team where that time savings directly translates to faster root cause fixes and revenue protection, the ROI calculation is straightforward.
Key terms glossary
Blast radius: The total number of users or transactions affected by an incident, calculated as failed transactions divided by total traffic during the incident window.
Blameless postmortem: A post-incident review process that focuses on system and process failures rather than individual mistakes, encouraging honest reporting without fear of punishment.
Five whys: A root cause analysis technique that asks "why" five times to move from surface symptoms to underlying systemic causes.
MTTR (Mean Time To Resolution): Average time from incident detection to full resolution, measured in minutes or hours.
Service Catalog: A directory mapping technical services to business functions, ownership, dependencies, and impact levels for incident context.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

