A new channel per incident – helpful or harmful?
August 18, 2022 — 9 min read

I caught the tail-end of a Twitter thread the other day which centred around the use of Slack channels for incidents, and whether creating a new channel for each new incident is helpful or harmful. It turns out this is a much more evocative subject than I thought, and since I have opinions I thought I’d share them!
Broadly speaking the two approaches being discussed were:
- Create a new channel for every incident, and provide a central index so folks can find incidents they might be interested in or be able to contribute to.
- Use a central, long-lived channel to respond to an incident, and once it’s clear which team owns it, or what systems are impacted, move the discussion to their existing channel to continue the response*.
I’ll disclose up front that I have a strong preference for the former, and in the interest of getting biases into the open it’s also what we do here at incident.io. I have, however, worked in organizations that used both approaches so you can consider this equal parts personal experience and corporate shilling.
*this is my understanding from the thread. If I’ve misinterpreted, or you think there’s another option I’ve missed, I’d love to hear from you! I'm @evnsio on Twitter 👋
Creating a new channel per incident
In this mode of response, the flow of an incident looks something like this:
- Someone or a system notices something isn’t right.
- They check whether there are any existing/ongoing incidents in a central index channel.
- If so, they dive in to contribute to the ongoing response.
- If not, they create a new incident, along with a new channel as a dedicated space to coordinate.
- The new incident is broadcast to the rest of the organisation, and the process repeats.
This approach leads to each incident having a fresh space to coordinate, which means context loading is easy, and there’s complete clarity over who’s involved in the incident as they’ve explicitly joined. Combined with an incident index – something like a central #incidents channel where each new incident is broadcast – folks can clearly see what’s going on across the org.
Additionally, new channels embrace the messy reality of incidents, where it’s not uncommon for them to be fuzzy-edged and misaligned with existing team structures, so a fresh space for a new ‘ephemeral team’ makes sense.
As with most things, there’s no such thing as a free lunch. With new channels created per incident, it makes it harder to see the details of everything that’s going on at once. Without tooling to help, it can also mean unhappy Slack admins who have to ask folks to clean up old channels 😅
Coordinating in a single central channel, and re-using existing channels for response
In this mode of response, the flow looks like this:
- Someone notices something doesn’t look right and posts in a central channel – something like #incidents or #outages.
- Some amount of communication happens in this channel
- At some point in the incident lifecycle, the coordination of the response moves to permanent channels aligned to teams, products, features, etc.
- No new channels are created for incidents.
With this approach, your main channel for response contains all of the context of what’s going on with your organization. If you stay on top of this channel, you should be well plugged in to the current state of things.
When incidents are understood and/or the ownership is clear, the general approach it to move the response to an existing channel to be mitigated. This means fewer channels being created and more context being kept alongside the other communication for that team/service/product.
The drawback here is that the main tracking channel can get super noisy, so whilst the distribution of information is low, it requires some effort to follow along.
One other downside is that stakeholders and folks in supporting teams who might need to be looped into the response effort now need to join the owning team’s channel. Over time this can converge on everyone being in everyone else’s channels, which in turn can lead to muting and missing information.
The principles of good communication during incident response
Rather than argue the relative merits of each approach, I thought I'd take a step back and come at this from a more principled standpoint. If we agree on the principles, and the resulting implementations follow them, there's really no better or worse, just personal preference.
To us, these principles look like:
- Clarity: It should be clear to anyone who cares (or needs to know) exactly what’s going on. If I arrive late on the scene, I should be able to figure out what things are known about already and whether things I’m seeing are part of that, or a new thing I need to flag.
- Centralisation: As much as is possible, discussion for each distinct issue should gravitate to a single communication place. Having information about a single issue spread over multiple places is actively harmful to response, and makes it much harder to load context when catching up.
- Accessibility: It should be easy for anyone who can contribute, or needs to provide input to the response to do so. This extends beyond those fixing the issue, and includes stakeholders across the organization and supporting functions like customer support, legal, and risk and compliance. Anyone with something to contribute should be able to, and when they get involved, they should be able to easily load the history and context.
- Focus: Responding to incidents should distract as few people as reasonably possible. Organizations should be shooting for minimum viable participation, whilst still responding effectively, to allow them to retain focus.
Both approaches can achieve this, and which works best is likely to depend on the myriad of nuances that exist within your organization!
How we make new channel creation work at incident.io
We’ve taken a pretty opinionated stance at incident.io, and I’d like to walk through why we think this makes sense, and how we’ve mitigated the drawbacks that were flagged in the original Twitter thread.
Have all your incidents announced in a single channel so everyone has a high level view of what’s going on
With a central channel where each incident is announced, everyone can see a concise summary of each incident, who reported it, who’s leading and a number of other useful data points quickly and easily.
Creating new places to talk about [incidents] is adding even more entropy to the responses!
We’re essentially providing a rich index of things going on. An index that makes these events easier to navigate and the linked response channels in a single, easy to find place. No entropy increase here!
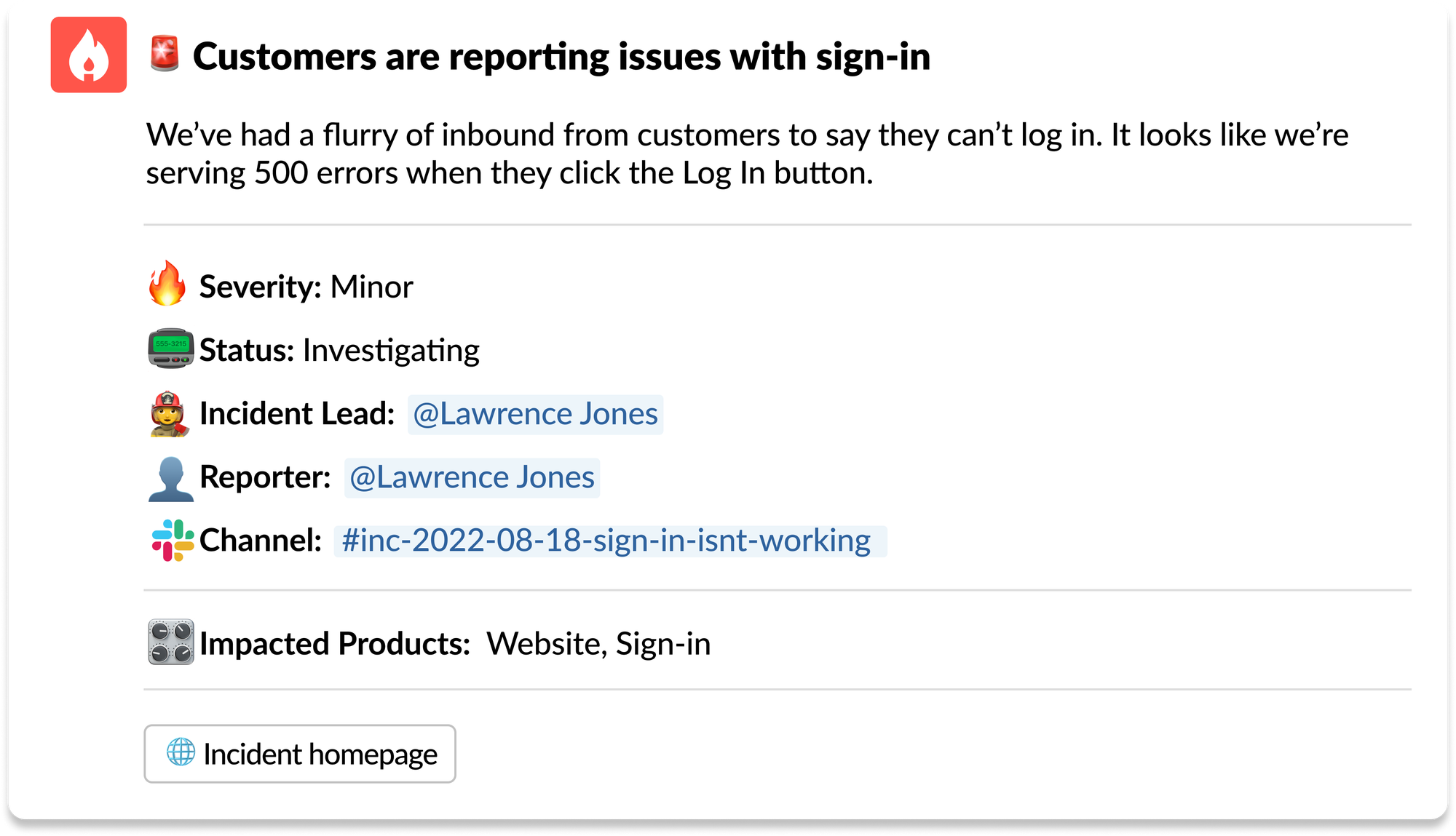
Minimise duplicate incidents by highlighting ongoing ones at the stage of reporting
In a world where new channels are created for each new incident, there’s a definite risk that folks report something that’s already in flight. We’ve been there, so we introduced safeguards that flag recent ongoing incidents at the point of declaration. Infallible? No. But it drastically reduces the likelihood of multiple disparate responses to the same thing.

Multiple responses to the same incident that aren’t coordinating with each other in the same communications channel is a recipe for complete disaster.
So now we have:
a) Stakeholders don’t know what’s going on
b) You don’t know who is reading what
c) Potentially multiple teams launching their own responses
These points are 100% valid, but since we avoid multiple responses in separate places, they’re founded on a situation that doesn’t materialise.
Clearly load the context for an entire incident when you arrive on the scene
With a freshly created channel near the start of your incident, it’s incredibly easy to scroll back in time and see how things materialised. No need to hunt for the start point, or unpick overlapping responses. Just you, the other responders, and all of the clean context in a single place.
What’s more, with this approach it’s easy to cherry pick interesting points into an incident timeline – a timeline most folks will want to pull together for any material incident.
Inform people who want to know and invite those that need to be involved
A new channel per incident makes it easy to inform anyone who wants to know about incidents, optionally filtering by arbitrary criteria. For those that need to know (or want to be included in a specific responses), they can be invited automatically.
Cleaning up after ourselves with channel auto-archiving
If, like me, you’ve spent many hours painstakingly curating your Slack sidebar to keep things organised, you’ll be pleased to hear our incident channels aren’t going to break that. Nobody wants old channels lying around, so we’ve built a smart archiving feature which understands the state of incidents – and under conditions you control – closes and archives old channels.

Clearly, there is no silver bullet when it comes to incident tooling, and the intention here isn’t to convince you that incident.io will solve all of your problems. Getting good at incident response requires time, effort, trust, training, and a whole lot more. But good tooling built by people who care can certainly make life a lot easier 🙂

Chris Evans
Co-Founder & Field CTO
I'm one of the co-founders, and Field CTO here at incident.io.
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

