Best Opsgenie alternatives for SRE teams in 2026
February 20, 2026 — 18 min read
Updated February 20, 2026
TL;DR: For SRE teams using Slack, incident.io offers superior Slack-native coordination and AI-powered post-mortems compared to traditional alerting tools. It combines on-call scheduling with automated incident coordination and AI-drafted post-mortems, helping teams reduce MTTR by up to 80%. Best for legacy compliance: PagerDuty. Best for Grafana ecosystem: Grafana OnCall. Best for monitoring-first teams: Better Stack. Key takeaway: The Opsgenie sunset is your opportunity to fix coordination overhead, not just swap alerting tools.
The Opsgenie sunset isn't just a vendor migration. It's a forcing function to fix broken processes. Atlassian is shutting down Opsgenie for new purchases after June 4, 2025, with full end of support on April 5, 2027. You have two choices: get absorbed into the Jira Service Management monolith, or move to a modern platform that actually fits how SREs work in 2026.
Most SRE teams see median P1 MTTR between 45-60 minutes. The breakdown: 12 minutes assembling the team, 20 minutes troubleshooting, 4 minutes on mitigation, and 12 minutes cleaning up. The problem isn't the technical fix. It's the logistics. This guide compares the top alternatives based on what matters to modern engineering teams: reducing MTTR, automating post-mortems, and eliminating tool sprawl.
Why SREs are leaving Opsgenie (beyond the sunset)
The Opsgenie shutdown deadline gives you cover to fix problems you've tolerated for years. Tab-switching during incidents is cognitively expensive. Every switch from Slack to Opsgenie to Datadog to a web-based incident management UI pulls your attention away from the problem. You lose the mental model you were building. Your alert fires in Opsgenie. You coordinate in Slack. You create tickets in Jira. You write post-mortems in Confluence.
Atlassian's migration path makes this worse. Atlassian forces teams to manage incidents across JSM and Compass, splitting incident management across multiple interfaces and creating friction during critical situations. The community response has been blunt: users question how Atlassian can claim that JSM or Compass can match what Opsgenie does for alert management.
Post-mortem archaeology creates an even deeper problem. Days after a P1 incident, your team scrolls back through incident Slack channels, checks Opsgenie for alert timestamps, and looks at Datadog for metrics. You spend 60-90 minutes creating an incomplete and probably inaccurate post-mortem.
Evaluation criteria: What matters for modern SRE teams
Choose your Opsgenie replacement based on these five criteria:
Slack-native workflow: Can you run the whole incident without leaving Slack? True Slack-native means the incident workflow happens in slash commands and channel interactions, not in a web UI that sends notifications to Slack.
MTTR impact: Does it actually speed up resolution or just wake you up? Teams using Slack-native platforms become operational in 3-5 days versus traditional tools' typical 2-6 week configuration.
On-call experience: Is onboarding a new engineer painful or instant? Modern platforms should make incident response intuitive enough that new engineers can contribute productively within days, not weeks.
Post-mortem automation: Does it eliminate the archaeology work? Look for platforms that auto-capture timelines during incidents rather than forcing you to reconstruct events from memory and scattered tools.
TCO and transparency: Are there hidden costs for enterprise features? Calculate the real cost per user including on-call scheduling add-ons, not just base pricing.
Top 5 Opsgenie alternatives compared
Workflow and automation capabilities
| Feature | incident.io | PagerDuty | Grafana OnCall | Rootly | Better Stack |
|---|---|---|---|---|---|
| Slack-native | Full lifecycle | Interactive (actions in Slack) | Dedicated UI | Slack-first | Monitoring-first |
| Auto-post-mortems | Yes (AI-generated) | Limited | Yes (timeline-based) | Yes (templated) | Yes (AI-assisted) |
| Post-mortem source | Timeline + AI transcription | Manual with templates | Timeline conversion | Workflow automation | Timeline + Slack history |
Pricing and on-call
| Feature | incident.io | PagerDuty | Grafana OnCall | Rootly | Better Stack |
|---|---|---|---|---|---|
| On-call scheduling | Add-on ($20/user/mo) | Included (Pro+) | Included (all plans) | Native | Included (all plans) |
| Base pricing | $25/user/mo (Pro) | $21-41/user/mo | Free (3 users) to PAYG | Custom | Free tier + PAYG |
| Total with on-call | $45/user/mo | $21-41/user/mo | $20/active user/mo | Custom | Varies by usage |
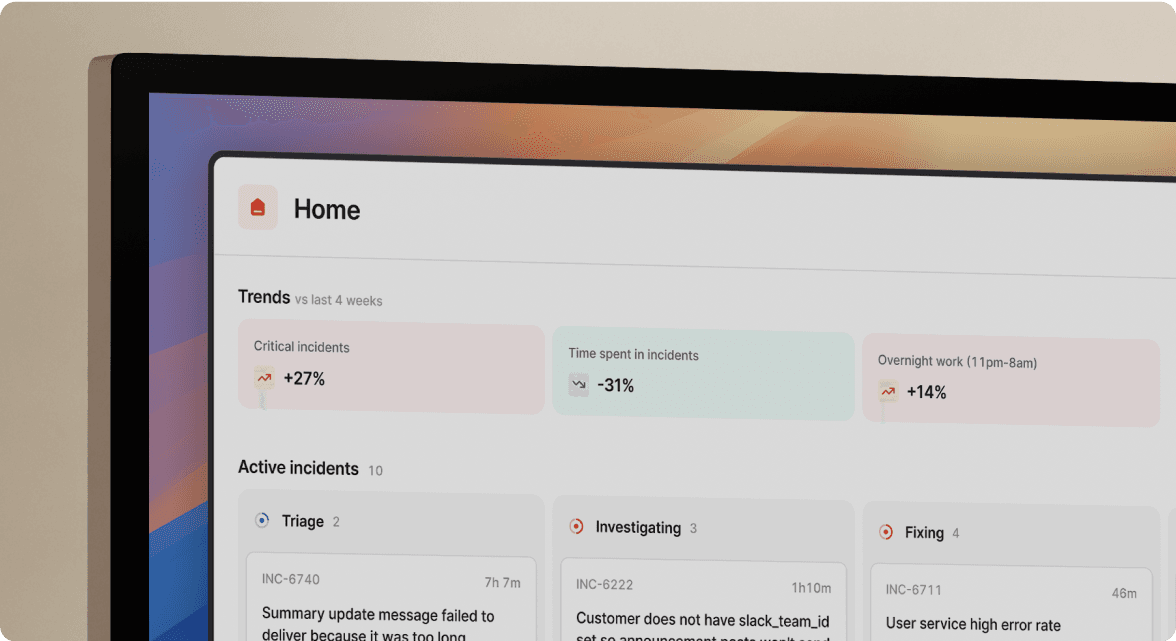
1. incident.io: Best for Slack-native coordination and automation
incident.io combines enterprise-grade on-call with automated incident coordination and AI-powered post-mortems, all within Slack.
Engineers declare, manage, and resolve incidents without leaving Slack using commands like /inc declare, /inc assign, /inc escalate, and /inc resolve. The web dashboard exists for reporting and configuration. During actual incidents, responders stay in Slack.
How it works: Your alert fires from Datadog. incident.io auto-creates a dedicated Slack channel, pages on-call engineers, and pulls in service owners based on your Service Catalog. When you run an incident using /inc commands, every action auto-populates the timeline. Role assignments, severity changes, Slack threads, and shared links all get captured automatically.
Post-mortem automation: incident.io's Scribe joins your Zoom or Google Meet calls automatically and transcribes everything in real-time. When someone says "I think this correlates with the 2:30 AM deployment," Scribe flags it as a key moment. When you type /inc resolve, the platform generates a post-mortem draft within seconds. You get an incident summary, complete timeline, transcribed call highlights, and suggested follow-up actions.
Pricing: incident.io Pro costs $25 per user per month, with on-call scheduling as a $20/user/month add-on for a total of $45/user/month.
Best for: SRE teams at 50-500 person companies who live in Slack and want to eliminate tool sprawl.
2. PagerDuty: Best for enterprise legacy compliance
PagerDuty remains the standard choice for teams who need rock-solid alerting with deep enterprise integrations and comprehensive compliance certifications.
PagerDuty's Professional tier costs $21 per user/month and adds chat integrations, escalation policies, status pages (250 subscribers), basic ticketing, SSO, and predefined incident roles. The Business tier costs $41 per user/month and offers custom fields, advanced ITSM integrations, internal status pages, and business response features.
PagerDuty's Slack integration allows you to acknowledge, resolve, and escalate incidents directly from Slack with bi-directional syncing. However, PagerDuty remains web-first rather than Slack-native. Your core workflow still lives in the web dashboard.
The trade-off: Your alert fires in PagerDuty. You coordinate in Slack. You create tickets in Jira. You write post-mortems in Confluence. You're still juggling multiple tools during high-stress incidents.
Best for: Large enterprises with complex ITSM requirements who prioritize vendor stability and comprehensive compliance certifications including SOC 2, ISO 27001, and FedRAMP.
3. Grafana OnCall: Best for teams deep in the Grafana ecosystem
Grafana OnCall is the natural choice for teams already invested in Grafana dashboards and alerting. Its data-native approach links alert details, visualization, and on-call handoff so responders move from signal to action quickly.
Grafana OnCall offers a free tier for up to 3 active users per month. Grafana Cloud Pro Pay As You Go starts at $8 per active user per month. Grafana OnCall is part of Grafana Cloud IRM and bills based on monthly active IRM users.
Grafana's incident management capabilities automatically convert timelines into structured post-incident review documents, streamlining the review process with pre-populated incident data.
The limitation: If your stack isn't Grafana-centric, you'll find less flexibility and more lift to integrate equivalent context from other observability tools. Grafana OnCall OSS entered maintenance mode in March 2025 and will be archived in March 2026, though the cloud offering continues.
Best for: Teams running the full Grafana stack (LGTM: Loki, Grafana, Tempo, Mimir) who want native integration with their existing observability platform.
4. Rootly: A configurable Slack-based alternative
Rootly positions itself as an AI-native platform with extensive workflow automation, allowing teams to orchestrate complex incident response processes across their existing toolchain. Rootly offers native on-call scheduling built into the platform.
Rootly's no-code workflow engine provides comprehensive incident orchestration where you configure triggers based on any incident property. You get deep customization capabilities with their templated post-mortem system.
The consideration: Rootly requires more upfront configuration than incident.io's opinionated defaults. You trade faster deployment for flexibility. incident.io uses opinionated defaults where most teams become operational in days. Teams wanting infinite customization may invest weeks or months in configuration.
Best for: Engineering teams who need extensive workflow customization and have dedicated resources for initial setup and ongoing maintenance.
5. Better Stack: Best for monitoring-first teams
Better Stack combines logs, metrics, monitoring and alerting in one visually polished product. Its on-call features integrate tightly with its monitoring capabilities.
Better Stack offers automated post-mortems based on the incident timeline and Slack history. Their incident management features include the ability to assign incident roles and ensure clarity and accountability.
Better Stack provides a free plan with 10 monitors and heartbeats, email alerts with 3-minute checks, 1 status page, and a 2-month incident history. Paid plans scale based on usage.
The positioning: Better Stack excels at monitoring and basic incident alerting. Teams focused primarily on uptime monitoring and simple alerting workflows find it intuitive and cost-effective. For mature SRE teams needing advanced incident coordination, runbook automation, or a comprehensive service catalog, you'll need to supplement Better Stack with additional tools.
Best for: Startups and small engineering teams who need monitoring and alerting combined in one tool and don't yet require complex incident management processes.
Feature deep dive: Automating the "designated note-taker" tax
The designated note-taker problem kills MTTR. During every major incident, one engineer (often the incident commander) gets stuck typing timeline updates into a Google Doc instead of troubleshooting. They miss critical technical details. They slow down their contribution. They create a bottleneck where if they aren't taking notes, you have no post-mortem data.
incident.io's approach eliminates manual note-taking entirely through automatic timeline capture and AI transcription.
Automatic timeline capture: During active incidents, incident.io automatically captures every Slack message, role assignment, and command in a structured timeline. When you type /inc escalate @database-team, incident.io records that decision with a timestamp. When someone shares a Datadog dashboard link, incident.io captures it. When you change severity from P2 to P1, the timeline updates automatically.
Real-time call transcription: Scribe generates detailed, structured call notes in real time featuring sections like "Overview," "Key moments," and "Next steps" along with the list of participants. These notes update automatically throughout the call. You see them in Slack, Microsoft Teams, and the dashboard. Scribe proactively pulls out decisions and actions from calls, pushing concise updates into incident channels for everyone to see.
AI-generated post-mortems: Using captured timelines, incident.io's AI generates post-mortem drafts that include incident summary, timeline of events, contributing factors, and suggested action items. You spend 10-15 minutes reviewing and refining instead of 60-90 minutes writing from scratch.
Example workflow: You start a Zoom call where Scribe joins automatically and transcribes everything in real-time. Someone says "I think this correlates with the 2:30 AM deployment." Scribe flags it as a key moment. You decide to "rollback first." Scribe captures that decision. You type /inc resolve. The platform generates a post-mortem draft within 10 seconds with your incident summary, complete timeline, transcribed call highlights, contributing factors, and suggested follow-up actions.
"Incident.io brings calm to chaos... It's the source of truth for incidents we've always needed." - Braedon G. on G2
Migration guide: Moving from Opsgenie without downtime
Run a parallel pilot rather than a big-bang cutover.
Week 1: Setup and integration
Connect your monitoring tools (Datadog, New Relic, Prometheus) and set up Slack or Microsoft Teams integration. Configure initial workflows for P1, P2, and P3 incidents. incident.io offers tools to make migrating from Opsgenie easier, including schedule import capabilities.
Week 2: Schedule migration
Import on-call schedules from Opsgenie using incident.io's migration tools. Set up escalation policies and configure alerting rules. Map your existing Opsgenie integrations to incident.io's Opsgenie integration.
Week 3: Parallel run
Test workflows alongside your existing system. Validate alert routing and train team members using the built-in /inc tutorial functionality. Run real incidents through both systems. Compare results. Identify gaps or configuration adjustments needed.
"Incident has a very responsive and competent team. They have built a system with sane defaults and building blocks to customize everything." - Bertand J. on G2
Week 4: Full switchover
Cut over completely and decommission Opsgenie. You can migrate to Slack-native incident response in 30 days, not six months, because the entire workflow lives where your engineers already work.
Common migration pitfalls to avoid:
Don't migrate during peak hours or major releases. Schedule your cutover during a maintenance window. Don't skip the parallel run phase. Running both systems for 1-2 weeks helps you catch configuration gaps before they affect real incidents. Don't forget to update runbooks and documentation with new workflows. Your team needs to know where to find incident channels and how to use /inc commands.
Summary and recommendation
If you want speed and modern workflow, choose incident.io. If you want legacy status quo with enterprise compliance, choose PagerDuty. If you're deep in the Grafana ecosystem, choose Grafana OnCall.
The Opsgenie sunset forces you to decide: migrate to another point solution that perpetuates tool sprawl, or upgrade to a platform that handles coordination, automation, and learning in one place.
Favor achieved a 37% MTTR reduction after implementing incident.io. For a team with a 48-minute median P1 MTTR handling 15 incidents per month, a similar reduction would save 270 minutes monthly, or 4.5 hours of engineering time you reclaim for proactive reliability work.
"Without incident.io our incident response culture would be caustic, and our process would be chaos." - Matt B. on G2
Schedule a demo to see your specific migration path from Opsgenie and run your first incident in Slack.
Key terminology
MTTR (Mean Time To Resolution): The average time from when you detect an incident to when you fully resolve it. Industry benchmarks for P1 incidents range from 30-60 minutes.
Slack-native: A platform where the entire incident workflow happens in Slack using slash commands and channel interactions, not just receiving notifications from a web-based tool.
Post-mortem archaeology: The painful process of reconstructing incident timelines after resolution by scrolling through Slack threads, alert histories, and dashboard snapshots, typically taking 60-90 minutes.
Tool sprawl: The fragmentation of incident management across multiple disconnected tools (alerting in Opsgenie, coordination in Slack, tickets in Jira, documentation in Confluence), creating context-switching overhead.
On-call rotation: A schedule determining which engineer responds to production alerts during specific time periods, typically rotating weekly or daily.
Incident commander: The designated role responsible for coordinating the incident response, making decisions, and communicating with stakeholders, separate from the technical troubleshooting work.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

