How incident.io helps to reduce alert noise
April 17, 2025 — 5 min read

We're often asked: "How does incident.io help reduce alert noise?" And it’s a fair question. It’s typically much easier to add new alerts than to remove existing ones, which means most organizations slow-march into a world where noisy, un-actionable alerts completely overshadow the high-signal ones that indicate a real problem.
Most commonly, people try to solve this with silencing rules or better thresholds — a reactive approach that our guide to preventing alert fatigue shows consistently falls short without systemic visibility.
If you want to actually fix alert noise, you need on-call tools that give you visibility into which alerts are causing problems, context to understand them, and the ability to act on what you find.
1. Start by making alerts easier to understand
It sounds basic, but the first step to reducing noise is understanding what’s actually making the noise.
Our alerting systems integrate tightly with Catalog—the source of truth for your services, teams, owners, environments, and more. When an alert fires, we can enrich them with that metadata: who owns the service, what team is responsible, what environment it’s in, etc.
This turns a noisy, contextless alert like “CPU > 90%” into something much more actionable: “High CPU on cart-service in production, owned by the checkout team.” And in case you’re wondering, making the title more human readable with AI is something we allow you to opt-in or out of.
With this in place, we have alerts that are enriched, connected to real entities in the organization, and with human friendly names that make them easier to decipher.
2. Group and route alerts to reduce noise
Not every alert needs to be an incident. Not every incident needs to page somebody.
That’s why we give you grouping and routing controls that help you bundle up related alerts and send them to the right place.
Our grouping logic allows for combinations or time-based (i.e. arriving within a defined window) and attribute-based (i.e. all alerts for the same team) grouping, and we also allow you to ungroup alerts in real-time during an incident.
Looking at an example of our dynamic ungrouping, let’s imagine we’re grouping by time-window only, and two alerts arrive within the window.
The first one creates an incident, and the second is grouped into the first incident by default due to grouping logic.
The responder is notified of this in Slack and has the option to ungroup at this point, and send that alert to be dealt with elsewhere.
Effective grouping doesn't solve an underlying problem with noisy alerts, but it reduces the burden on teams carrying an on-call schedule whilst you work on the proper fixes.
Ultimately with grouping set up, a spike in alerts from one flaky service doesn’t result in five separate incidents or three unnecessary pages.
3. Understand what happens after the alert fires
Because alerts are directly tied to incidents in incident.io, we can track what actually happens after the alert fires.
- Did someone acknowledge it?
- Did they escalate to someone else?
- Did they decline it entirely?
- How long did they spend resolving it?
That turns every alert into a feedback loop. Over time, we can tell you which alerts are frequently ignored, which ones cause the most disruption, and which ones are quietly eating up your team’s time.
This is the goldmine. Without this kind of visibility, all you can really do is guess which alerts are a problem.
4. Use the Alerts Insights dashboard to do the triage
To make all of this useful, we wrap it up in our Alerts Insights dashboard, where you can slice and dice alert data any way you like.
Here’s what you’ll find:
- Trends over time, grouped by any alert attribute—good for spotting noisy services or seeing which teams are drowning in alerts.
- Top offending alerts, sortable by count, number of pages, and number of incidents created.
- Acceptance rates, so you can see which alerts are actually being worth responding to.
- Decline rates — a core metric inreducing alert fatigue in incident management — give you a hit list of alerts to kill or tune.
If you see an alert that’s declined 90% of the time, it’s not just noise, it’s someone actively telling you, “this isn’t useful.”
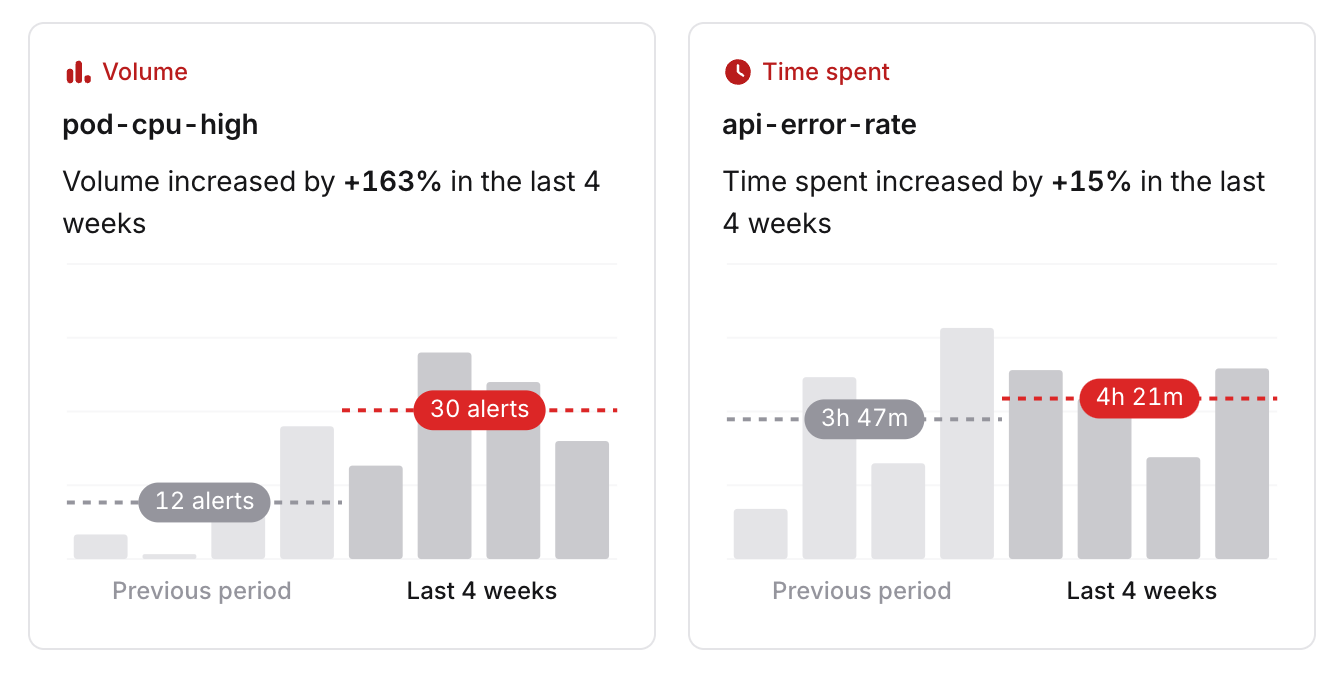
5. Coming soon: Alert Intelligence
The plan for Alert Intelligence is to go beyond dashboards and actually do the analysis for you. Instead of asking you to sift through graphs and tables, we’d surface insights like:
“You’ve spent 90% more time dealing with this alert in the last 4 weeks.”
Or:
“This alert has been declined 22 times in a row by 3 different people.”
To do that, we’ll tap into all the data we already collect, like smart time tracking during incidents, to paint a picture of what’s really going on with each alert, and what’s worth fixing.
The core of SRE alerting best practices is not just tweaking alerting rules. It's about connecting the alerts that are firing to the reality of what happens when people respond to them on an ongoing basis. And that’s exactly where incident.io shines.
If you want a walkthrough of how this looks in practice, we’d be happy to show you. Just give us a shout.

Chris Evans
Co-Founder & Field CTO
I'm one of the co-founders, and Field CTO here at incident.io.
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

