Do you need incident post-mortem software? Signs your team has outgrown manual processes
February 16, 2026 — 16 min read
Updated February 16, 2026
TL;DR: Manual post-mortem processes work for teams handling 2-3 incidents monthly. When timeline reconstruction takes 60-90 minutes (based on engineering teams incident.io works with) and costs your team in coordination overhead $20,000-$54,000 annually, you've hit the coordination tax threshold. Five signs you've outgrown manual processes: reconstruction takes longer than fixes, post-mortems are consistently late, new engineers fear on-call, you can't measure improvement, and someone always stops troubleshooting to take notes. Dedicated software reclaims 83% of post-mortem documentation time (reducing reconstruction from 90 to 15 minutes), while teams typically see MTTR improvements of 25-40% through faster coordination.
You closed the incident 3 days ago. The site is stable. Production is humming. Now comes the hard part. You open a blank Google Doc. What time did the alert fire? Who joined first? What was that Datadog graph someone shared? Did we try rolling back before or after the database fix? You open Slack and start scrolling. Fifteen minutes later, you're still hunting through 200+ messages across three channels. This is post-mortem archaeology. You're not learning from the incident. You're trying to remember it.
At a certain scale, manual processes break. When your team spends more time managing the incident process than fixing the incident itself, you've crossed a threshold. Here are the signs it's time to automate.
The hidden cost of manual incident management
The problem isn't the outage time. It's the cleanup time.
Coordination tax is the non-technical time spent assembling responders, sharing context, updating tools, and synchronizing information during incidents. The formula: Annual Cost = (Incidents/Month) × (Engineers per Incident) × (Coordination Minutes + Post-Mortem Minutes) ÷ 60 × (Hourly Rate) × 12.
For a 100-person engineering team handling 12 incidents monthly, the math breaks down: 4 engineers spend 15 minutes per incident on coordination (creating channels, paging people, updating status pages) = 1 hour. One engineer spends 90 minutes reconstructing the post-mortem = 1.5 hours. Total per incident: 2.5 hours. At $150 loaded engineer rate (based on average SRE salary of $168,897/year per Glassdoor, 2026), that's $4,500 monthly or $54,000 annually in coordination overhead. That's money spent on logistics, not fixes.
5 signs you need an incident management tool
1. You spend more time reconstructing the timeline than fixing the issue
Manual post-mortem reconstruction wastes 60-90 minutes per incident as teams search through chat history, monitoring tools, and call recordings trying to piece together what happened.
The pain looks like this: You check alert origins across multiple platforms, scroll through Slack to find who said what when, dig through Datadog for graphs people shared, and try to recall decisions made during Zoom calls. Critical context gets lost when conversations happen across video calls, chat threads, and dashboards.
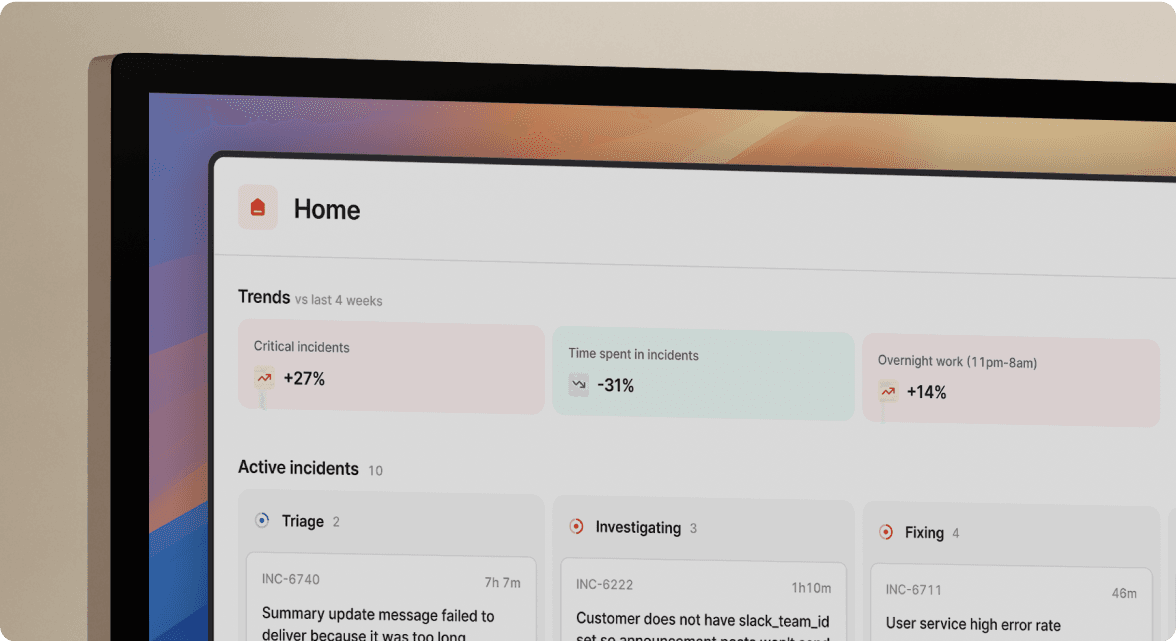
Automated timeline capture solves this by recording events as they happen. Our Timeline feature automatically creates events using incident updates like severity changes, status changes, and pinned Slack messages. The timeline builds itself while you focus on troubleshooting.
"Less time spent putting together an accurate timeline of an incident. It's so easy to pin important messages and updates and automatically it creates the timeline for you." - Verified user on G2
2. Your post-mortems are consistently late (or empty)
When reconstruction is hard, people procrastinate. Many companies target completion within 36-48 hours, but manual post-mortems fail repeatedly because they ask engineers to perfectly remember and document high-stress events days later, as Google's SRE Workbook documents.
When teams are overloaded with other tasks, post-mortem quality suffers. Subpar post-mortems with incomplete action items make incident recurrence far more likely.
Auto-drafted post-mortems solve this. Our AI assistant instantly drafts post-mortems complete with timeline, contributing factors, and resolution, saving hours of manual write-up. Teams using automated generation complete post-mortems in 10-15 minutes instead of 60-90 minutes spent on reconstruction.
"1-click post-mortem reports - this is a killer feature, time saving, that helps a lot to have relevant conversations around incidents (instead of spending time curating a timeline)." - Adrian M. on G2
3. New engineers are terrified of going on-call
The process lives in "tribal knowledge" or stale runbooks. When key employees leave or retire, essential information may be lost, leading to inefficiencies and increased training costs.
If critical information exists only in someone's head and they're unavailable during an incident, recovery stalls.
Guardrails and workflows solve this by codifying the process. Our Workflows feature provides automated channels that auto-create incident channels and invite owners by service. Roles and checklists assign Incident Commanders and load severity-specific checklists automatically. Timeline capture auto-logs messages, assignments, and actions.
New engineers handle their first P2 using intuitive /inc commands without memorizing 47-step runbooks. The platform guides them with clear next actions, reducing onboarding from weeks to days.
"Amazing slack integration makes handling incidents completely in slack a breeze. This lets our team not have to think about yet another service and instead handle it in a more human and integrated way." - Brandon O. on G2
4. You have no data to answer "are we getting better?"
Leadership asks "Is MTTR improving?" and you have to manually scrape Jira tickets and PagerDuty history to find out. Teams built custom Jira REST API scripts just to track how many incidents by severity still lack root cause fixes. Engineering managers review these lists regularly, highlighting the difficulty in accessing basic reliability metrics.
Manual tracking means exporting data from multiple tools into spreadsheets, manual data cleaning, and quarterly reporting instead of real-time insights. You can't optimize what you can't measure.
Structured data and dashboards solve this. Our Insights Dashboard provides auto-generated trends and analytics including MTTA/MTTR tracking, top incident types, and service-level breakdowns. When you can show the board that median P1 MTTR improved by 25-40% over 90 days, you're proving reliability investment ROI with evidence, not anecdotes.
5. You're suffering from "designated note-taker" fatigue
During every major incident, one engineer (usually the Incident Commander) stops troubleshooting to type timeline updates into a Google Doc. This approach has dual negative impact: it removes a valuable troubleshooter from the response and creates a single point of failure where "if Sarah isn't taking notes, we have no post-mortem data."
The designated note-taker misses critical technical details while typing, their contribution to the fix is slowed, and they become a bottleneck. Multiple responders should contribute to timelines simultaneously during complex incidents.
Automated documentation eliminates this tax. Our Scribe feature records and transcribes incident calls, capturing decisions made verbally without requiring a dedicated note-taker. Timeline events are automatically logged as the incident unfolds. Engineers focus entirely on resolving the issue while the platform handles documentation.
"Spend more time in post mortems looking at problem solving and long term improvements instead of worrying about paperwork." - Verified user on G2
Incident management software vs. post-mortem tools: What's the difference?
The terminology matters because the solution scope differs.
Post-mortem software focuses on documentation after the incident. These tools help you write better reports, but they don't help during the response itself.
Incident management software handles the entire lifecycle from detection through resolution and learning. The platform integrates with Slack, monitoring tools, and ticketing systems to capture events as they happen. Real-time capture means when an engineer types /inc assign, the role change is recorded with timestamp and context. When someone shares a Datadog graph, it's preserved. The timeline builds during the response, not after.
You need a holistic platform because the quality of your post-mortem depends entirely on data captured during the response. Point solutions create the tool sprawl you're trying to escape.
The ROI of dedicated post-mortem software
The hard costs are calculable using this formula: Annual Cost = (Incidents/Month) × (Engineers per Incident) × (Coordination Minutes + Post-Mortem Minutes) ÷ 60 × (Hourly Rate) × 12.
Example calculation for a 100-person engineering team:
| Activity | Manual Time | Engineers Involved | Monthly Cost (12 incidents) | Annual Cost |
|---|---|---|---|---|
| Coordination (channel creation, paging, status updates) | 15 min | 4 engineers | $1,800 | $21,600 |
| Post-mortem reconstruction | 90 min | 1 engineer | $2,700 | $32,400 |
| Total coordination tax | $4,500/month | $54,000/year |
With automated software, coordination drops from 15 minutes to 2 minutes through auto-created channels and auto-paging. Post-mortem reconstruction drops from 90 minutes to 15 minutes using AI-drafted timelines. New calculation: 2.5 hours reduced to 0.5 hours per incident represents significant time savings per month.
Soft benefits compound the value. Less chaotic incident response reduces engineer burnout and turnover. Replacing a senior engineer can cost 50-200% of their annual salary in recruiting and onboarding. Faster status updates build customer trust during outages. SOC 2 Type II certification requires immutable audit trails showing exactly what happened, and manual copy-pasting creates audit gaps.
Real customer evidence backs this. Favor reduced MTTR by 37% (per incident.io customer case study) by eliminating manual coordination overhead. Teams typically reduce MTTR by 25-40%, with some achieving up to 80% reduction depending on incident volume and process maturity.
When to implement a post-mortem platform
Common triggers indicate it's time:
Team size and incident volume: When you cross 20 engineers handling production support, manual processes start breaking. Coordination overhead scales non-linearly. Teams handling 5+ incidents monthly spend enough time on documentation that automation pays for itself within months.
SOC 2 preparation: For SOC 2, incident response is an absolute must. The criteria requires that you evaluate security events and have procedures for detecting, analyzing, and resolving incidents. Manual processes with gaps in documentation create compliance risk.
Tool sprawl pain: If engineers are juggling 4+ tools during incidents (PagerDuty for alerts, Slack for chat, Datadog for metrics, Jira for tickets, Confluence for docs, Statuspage for customers), consolidation saves cognitive load and reduces errors.
Opsgenie migration: Atlassian's Opsgenie sunset forces affected teams to re-evaluate their entire incident management stack. This is the natural time to move to a modern platform rather than migrating to another legacy tool.
Stop the archaeology
Process debt slows down reliability work the same way technical debt slows down features. You can't learn from incidents if you can't remember them accurately. You can't improve MTTR if you can't measure it. You can't scale on-call rotations if the process lives in senior engineers' heads.
The coordination tax compounds every incident. At 12 incidents monthly, $54,000 annually disappears into manual timeline reconstruction and tool-switching overhead. That's budget you could spend on actual reliability improvements.
For teams preparing business cases, schedule a demo to see the Insights dashboard, AI post-mortem generation, and workflow automation that reduce documentation time by 83% (reducing reconstruction from 90 to 15 minutes). We'll show you the same integration approach that helped organizations deploy fully across multiple teams in 45 days (per incident.io customer data).
Glossary
Coordination Tax: The cumulative time and effort spent on manual incident response activities like creating channels, updating stakeholders, copying information between tools, and reconstructing timelines. This overhead compounds with team size and incident frequency.
Incident Commander (IC): The designated person responsible for coordinating the overall response to an incident. The IC manages communication, delegates tasks, and makes key decisions during active incidents.
Mean Time To Acknowledge (MTTA): The average time between when an alert is triggered and when a responder acknowledges they are working on it. Lower MTTA indicates faster initial response.
Mean Time To Repair/Recovery (MTTR): The average time between when an incident is detected and when normal service is restored. A key reliability metric that directly impacts customer experience and business outcomes.
On-call: The rotation schedule where engineers are designated as first responders for incidents during specific time periods. On-call engineers are expected to respond quickly when paged.
P1/P2 (Priority Levels): Incident severity classifications. P1 typically indicates critical incidents affecting production and customers, while P2 represents high-priority issues with significant but non-critical impact.
Post-mortem/post-mortem: A structured review document created after an incident that includes timeline, root cause analysis, impact assessment, and action items to prevent recurrence. Also called incident reviews or retrospectives.
Root Cause Analysis (RCA): The process of identifying the fundamental reason an incident occurred, going beyond immediate symptoms to understand underlying system or process failures.
Runbook: Documented procedures for handling specific types of incidents or operational tasks. Runbooks provide step-by-step instructions to help responders resolve issues quickly and consistently.
Site Reliability Engineering (SRE): Engineering discipline that applies software engineering principles to infrastructure and operations, focusing on system reliability, scalability, and automation.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


