Best incident postmortem software for startup teams: 2026 guide
February 5, 2026 — 20 min read
Updated February 5, 2026
TL;DR: Startups waste 60-90 minutes per incident reconstructing timelines from scattered Slack threads and monitoring dashboards. The best postmortem software automates timeline capture during the incident so engineers focus on fixes instead of archaeology. incident.io leads for Slack-native automation with AI-drafted postmortems, FireHydrant offers structured retrospective workflows, and manual docs work for very early stage teams. Look for tools with free tiers, automatic timeline collection, and two-way Jira integration so action items don't die in a document.
Post-mortem reconstruction wastes 60-90 minutes every single time, forcing teams to search through hundreds of Slack messages and monitoring logs trying to piece together incident timelines days after the fact.
Manual post-mortem reconstruction forces teams to search through chat history, monitoring tools, and call recordings trying to piece together what happened. For a startup handling 10 incidents monthly, that's 15 hours of engineering time spent on documentation archaeology instead of reliability work. The average SRE salary in the United States ranges from $135,888 to $168,897 annually, translating to substantial monthly costs in manual documentation effort.
The problem isn't that engineers are bad at documentation. The problem is asking them to document something after the fact when the data already exists in Slack threads, monitoring alerts, and incident channels. Modern postmortem software automates the administrative toil so your team can focus on learning instead of data entry.
Why startups need specialized postmortem tools
Incident management covers the full lifecycle from alert to resolution to learning. Postmortem tools specifically handle the learning phase, capturing what happened, why it happened, and what you'll do differently next time. The distinction matters because most incident management platforms treat postmortems as an afterthought, a form to fill out manually after you've resolved the issue.
Startups face a specific constraint: every engineer needs to be troubleshooting during an incident. You can't afford the "designated note-taker tax" where one person types timeline updates into a Google Doc instead of helping fix the problem. Critical context from a key conversation or a fleeting metric spike can be overlooked, leading to an incomplete analysis that misses the real root cause.
The traditional approach using Notion or Confluence for postmortems fails at scale for three reasons:
Data is static and disconnected: Your postmortem lives in a doc. Your action items live in Jira. Your metrics live in Datadog. Nothing talks to each other. Follow-up tasks listed in static documents are often forgotten, meaning valuable lessons fail to translate into action items that actually get completed.
Memory decay is brutal: Details fade from memory quickly, and within 24 hours, people begin constructing narratives that make sense of events rather than accurately recalling them. Critical details and exact sequences of events become unclear when team members are asked to reconstruct incidents days after they occur.
No trend visibility: When your VP Engineering asks "why are we having so many database incidents?" you spend four hours manually exporting Jira tickets and building a spreadsheet because postmortem data is scattered across 47 different Google Docs.
Dedicated postmortem software solves this by capturing data where the work happens, typically in your chat platform, and automatically building timelines as the incident unfolds.
Key features to look for
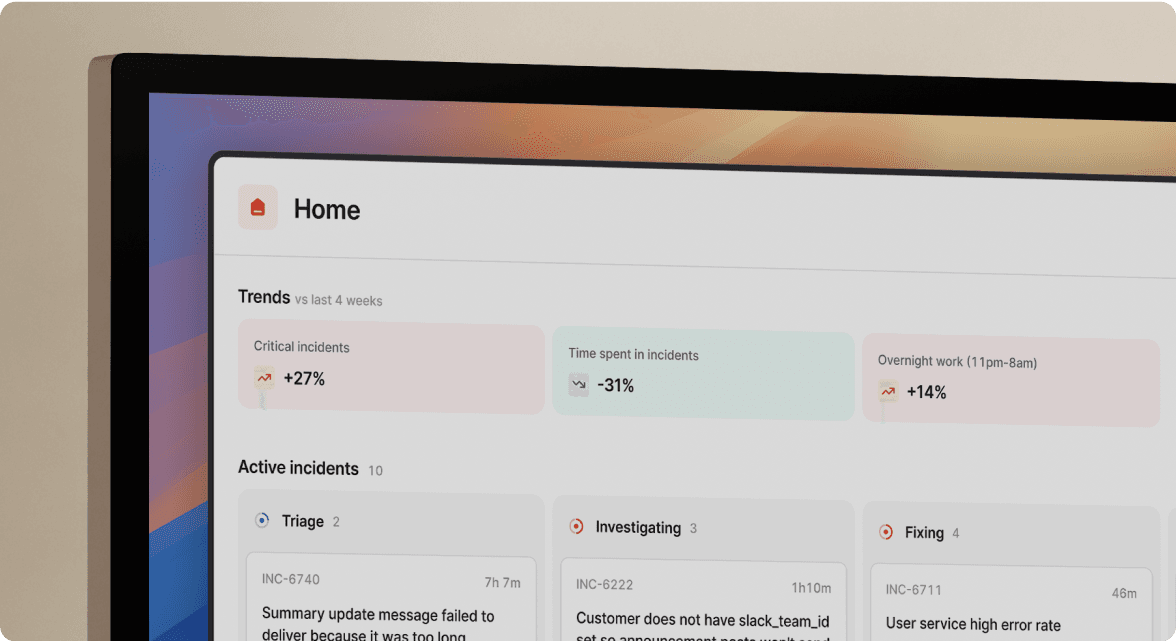
Automated timeline collection tops your requirements list. You need a tool that captures Slack messages, role assignments, escalations, and key decisions with timestamps as they happen. When post-mortems are drafted automatically from captured timeline data, engineers can focus on refining insights rather than reconstructing events from memory.
Deep integrations separate useful tools from noise. At minimum, you need connections to:
- Your monitoring stack (Datadog, Grafana, New Relic) to pull graphs and metrics
- Your ticketing system (Jira, Linear) to create action items that sync bidirectionally
- Your alerting tool (PagerDuty, Opsgenie) to correlate alerts with timeline events
- Your documentation platform (Confluence, Notion) to publish finished postmortems
Transparent pricing with free tiers matters for startups operating on Series A budgets. Hidden costs or "contact sales" pricing creates procurement friction when you need to move fast. Look for tools that publish per-user pricing upfront and offer functional free tiers for small teams.
Zero training requirement is critical because you'll use this tool during high-stress moments. If it takes a workshop to learn, engineers won't use it when production is down and every second counts. Slack-native tools have an advantage here because engineers already know how to use Slack.
AI assistance separates good tools from great ones. AI that automates up to 80% of incident response by drafting postmortem summaries from captured timelines, transcribing incident calls, and suggesting root causes based on past incidents saves real time. The distinction matters because one approach saves you 5 minutes of reading, the other saves you 30 minutes of investigation.
Top postmortem software options for startups
| Tool | Best for | Pricing model | Key differentiator |
|---|---|---|---|
| incident.io | Slack-first teams wanting automation | $25/user/month, free tier available | AI-drafted postmortems from chat timelines |
| FireHydrant | Teams needing structured retrospectives | $250+/month custom pricing | Branching logic templates, strong runbook automation |
| Manual (Notion/Confluence) | Very early stage (<5 engineers) | Free | Infinite flexibility, zero automation |
Note on PagerDuty: PagerDuty is discontinuing postmortem features in early 2026. If you currently use PagerDuty for postmortems, plan your migration now using incident.io's PagerDuty migration tools.
incident.io
Best for: Engineering teams who live in Slack or Microsoft Teams and want end-to-end automation from incident declaration through postmortem publication.
incident.io's Basic plan delivers free access for up to 5 users with Slack-native incident response and one status page, perfect for startups testing the waters. The Pro plan runs $25/user/month (monthly billing) with on-call scheduling as a separate add-on. (A lower-tier Team plan is available starting at $19/user/month for smaller teams.)
The core value proposition: timeline capture auto-logs messages, assignments, and actions, then exports to post-mortem without manual copy/paste. When a Datadog alert fires, incident.io auto-creates a dedicated Slack channel, pages the on-call engineer, pulls in the service owner based on catalog data, and starts recording a timeline. Engineers use /inc commands to manage incidents without leaving the conversation.
Our AI SRE drastically shortens the time from alert to resolution by automating investigation, connecting telemetry, code changes, and past incidents to surface root causes without manual prompting. For postmortems, the AI quickly drafts a complete document including timeline, contributing factors, and follow-ups based on the captured incident data.
"I didn't know about incident.io until I've had the opportunity to learn from him at the current company I'm working for. I really like its integration with Slack, quickly and visually alerting us to an issue... It helps a lot on focusing the understanding and emergency solution of the problem, giving us the condition to do a post-mortem associated with the incident later." - Cassio F. on G2
Startup fit: Teams report seamless integration with existing tools, completing rollout in less than 20 days. You can install incident.io in 30 seconds and begin capturing incident timelines immediately.
FireHydrant
Best for: Teams looking for structured retrospective frameworks with customizable templates and strong process enforcement.
FireHydrant pricing starts from $250/month with custom pricing that requires sales conversations. The platform streamlines incident response with repeatable process, automated response, and one-click postmortems.
FireHydrant's retrospective system stands out with branching logic templates, allowing creation of custom questions that adapt based on incident type or severity. This works well for teams wanting to enforce consistency across postmortems, ensuring every P1 incident answers the same core questions.
The platform includes AI-powered voice transcription for Zoom and Google Meet calls with real-time transcription and automatic key point summarization, similar to incident.io's Scribe feature.
Important context: In August 2024, FireHydrant acquired former competitor Blameless, gaining additional functionality along with enterprise customers including CrowdStrike, Palo Alto Networks, and VMware. If you were evaluating Blameless separately, that product is now part of FireHydrant's roadmap.
Trade-offs for startups: Users report setup can be tricky, with integration requiring time and effort, and cost being a concern for smaller teams. The interface feels more complex than Slack-native alternatives because it's fundamentally web-first with chat integration rather than chat-native.
Manual documentation (Notion, Confluence, Google Docs)
Best for: Seed-stage teams with fewer than 5 engineers who handle infrequent incidents.
Manual postmortems in shared documents work when incident volume is low and everyone involved can sit in the same room for the retrospective. You have infinite flexibility to structure postmortems however you want, zero software costs, and no new tools to learn.
The limitations hit fast as you scale. Manual postmortems drain valuable engineering resources as engineers manually collect data from multiple sources like Slack threads, monitoring dashboards, and ticketing systems. Without a standard format, reports vary across teams, making it nearly impossible to compare incidents and identify systemic trends over time.
The math tells the story: 90 minutes per postmortem × 10 incidents monthly = 15 hours monthly = 180 hours annually. At typical SRE compensation rates, you're spending thousands of dollars annually on timeline reconstruction. Compare that to incident.io at $25/user/month × 15 users = $4,500 annually (or $3,600 with annual billing), which pays for itself through time savings while improving postmortem quality.
Manual docs make sense when incident response isn't yet a core competency you're investing in. Once you're hiring for on-call rotations and incidents impact customer SLAs, dedicated tooling pays for itself immediately.
How to choose the right postmortem software
Match tool complexity to team size. Under 10 engineers handling 3-5 incidents monthly? Manual docs or incident.io's free tier work fine. 10-50 engineers with formal on-call rotations? You need automation with paid features (timeline capture, AI assistance, ticketing integration). Over 50 engineers? You need analytics showing MTTR trends and incident patterns by team or service.
Align to your chat platform. If your team lives in Slack and defaults to "did you see that in Slack?" for coordination, choose a Slack-native tool like incident.io where the entire workflow runs in Slack using slash commands, automated channel creation, role assignments, and timeline capture without context switching. Microsoft Teams shops should verify Teams support (we offer this on Pro plans, FireHydrant supports Teams).
Calculate total cost of ownership, not sticker price. A "cheap" tool that requires 90 minutes of engineer time per incident costs more than you think. Include your loaded engineer cost in TCO calculations. incident.io at $25/user/month for 20 users costs $6,000 annually in software. Add engineering time: if AI-assisted postmortems take 15 minutes instead of 90 minutes, you save 75 minutes per incident. At 10 incidents monthly, that's 750 minutes (12.5 hours) saved monthly or 150 hours annually. Manual docs cost $0 in software but consume the full 90 minutes × 10 incidents = 15 hours monthly. The automated tool reclaims 150 engineering hours annually while improving postmortem quality and completion rates.
Test with real incidents during trials. Don't evaluate tools with sandbox data. Run 2-3 real incidents through the platform during your trial period to verify the timeline capture actually works with your monitoring stack, the Slack integration feels natural during high-stress moments, and the AI-drafted postmortems require editing rather than complete rewrites.
"incident.io helps my teams focus on the problem itself instead of the tools. It is a really game-changing product during and after the incidents. Before incident.io we were always struggling to collect important information about the incidents." - Tiago C. on G2
Common pitfalls when implementing postmortems
Treating the postmortem as a form to fill out instead of a learning exercise kills psychological safety fast. When engineers feel like they're filing a report for management review rather than discussing how to prevent the next outage, they minimize their own contributions to protect themselves. Tools help here by focusing on systems (what happened, when, in what sequence) rather than people (who made the mistake), building what Google's SRE team calls blameless postmortem culture.
Waiting too long destroys data quality. Ideally, postmortems are drafted immediately after a post-incident review meeting held within 24-48 hours of the incident resolving, and not more than five business days. Memory decays faster than systems recover, with the sweet spot for postmortem meetings being 24 to 72 hours after resolution, soon enough that details are fresh but with enough emotional distance to allow objectivity.
Letting action items die in the document wastes the entire exercise. This is where two-way ticketing integration becomes critical. With Jira connected to incident.io you can export follow-ups via the web dashboard and Slack/MS Teams apps, with information on the ticket such as its title, assignee, and completion synced back to incident.io. Action items identified in postmortems can be automatically synced as tickets in platforms like Jira, Linear, and Asana, placing tasks directly into engineering backlogs where work happens and dramatically increasing the likelihood of completion.
Watch How Incident Response and Postmortem Processes Can Improve your Workflow for a practitioner perspective on building effective postmortem culture alongside the right tooling.
Postmortem software evaluation checklist
Use this checklist when evaluating postmortem tools for your startup:
Timeline capture:
- Automatically captures Slack/Teams messages with timestamps
- Records role assignments and escalations in real-time
- Includes monitoring alerts and metrics in timeline
- Requires zero manual copy-paste during incidents
Integration requirements:
- Two-way sync with your ticketing system (Jira, Linear, Asana)
- Pulls graphs and dashboards from monitoring tools (Datadog, Grafana)
- Exports to documentation platform (Confluence, Notion)
- Connects to alerting system (PagerDuty, Opsgenie)
Startup-friendly criteria:
- Free tier or trial available without credit card
- Transparent pricing published on website
- Operational within 5 days, not 5 weeks
- Zero training required (Slack-native or intuitive UI)
Postmortem quality:
- AI assistance for drafting summaries
- Template customization for different incident types
- Searchable archive for trend analysis
- Action item tracking with status updates
Team adoption:
- Works in existing chat workflow
- No context switching during incidents
- Minimal admin configuration needed
- Support response time under 24 hours
Download and share this checklist with your evaluation team to ensure you test the features that matter most for startup incident response.
Start with automation, not archaeology
Manual postmortem reconstruction is archaeology: digging through scattered artifacts trying to reconstruct what happened days after the event. Modern postmortem software is documentation: capturing what happened as it happens so you can focus on why it happened and how to prevent it next time.
The economic argument is clear for startups. You're either spending substantial engineering hours monthly on manual timeline reconstruction or investing in tools that automate it. The automated path saves time while improving postmortem quality, completion rates, and action item follow-through.
incident.io leads for teams wanting Slack-native automation with AI assistance. Book a demo to see timeline capture and AI-drafted postmortems in action. FireHydrant works for teams needing structured retrospective templates with branching logic. Manual docs remain viable for very early stage teams handling infrequent incidents.
The worst option is what most startups do: continue the manual process because "we'll formalize incident management next quarter." Every incident you run without proper tooling is a learning opportunity wasted and engineering time you'll never reclaim. Start capturing timelines automatically today.
Key terms glossary
Blameless postmortem: A retrospective focused on systems and processes that failed rather than individuals who made mistakes, promoting psychological safety and honest learning.
Timeline capture: Automated logging of incident events, messages, role assignments, and decisions with timestamps as they occur during incident response, eliminating manual reconstruction.
Two-way integration: Synchronization between postmortem tools and project management systems where action items created in postmortems appear as tickets in Jira/Linear and status updates sync back to the postmortem tool.
MTTR (Mean Time To Resolution): The average time from when an incident is detected to when it's fully resolved and services return to normal operation.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


