Best incident management tools for MSPs: Mastering multi-tenant coordination
January 26, 2026 — 24 min read
Updated January 26, 2026
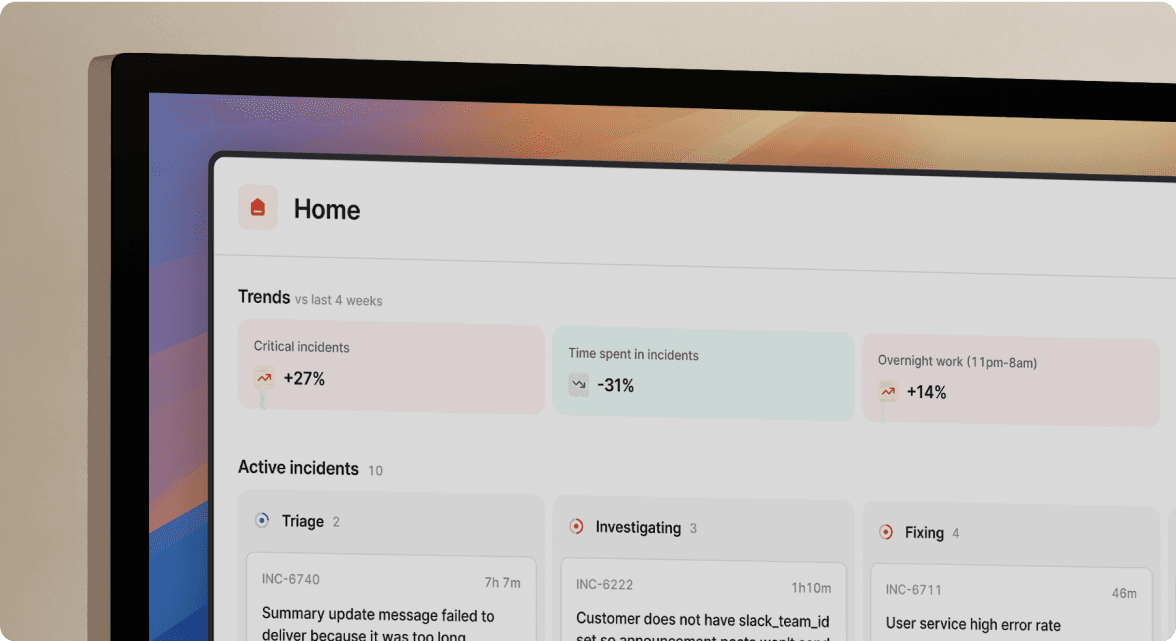
TL;DR: If you run an MSP managing incidents across 20, 50, or 100+ client environments, you face a unique architectural challenge. You need strict data isolation so Client A's credentials never leak to Client B, automated SLA tracking per customer tier, and instant context delivery so your responders don't waste 15 minutes identifying which client owns an alert. Legacy tools like Jira and ServiceNow force you to choose between speed and isolation. We built incident.io's Service Catalog to eliminate that trade-off. Map services to customer objects, use Private Incidents for data boundaries, and automate customer-specific workflows. You get unified operations with per-customer reporting.
Managing incidents for one company is hard. Managing them for 50 companies simultaneously is a different problem entirely. The challenge isn't technical complexity. It's operational architecture. You need strict data isolation (Client A's credentials never leak to Client B), variable SLA adherence (15-minute response for premium clients, 4-hour for standard), and automated context delivery (which client owns this alert?) without burning out your on-call rotation.
Context switching drains up to 40% of productivity daily. For MSPs managing 50+ clients, that tax compounds exponentially. Your engineers lose 15 minutes per incident just identifying the customer, logging into the right VPN, and assembling the client-specific response team. Gloria Mark's research shows it takes an average of 23 minutes and 15 seconds to fully regain focus after an interruption.
We built this guide to show you how modern MSP incident coordination eliminates that overhead. You'll learn how to architect multi-tenant workflows that scale from 10 to 100 clients without adding headcount, using tools like incident.io's Service Catalog to automate the "who, what, and where" that legacy platforms require manual lookup.
What is multi-tenant incident management for MSPs?
We define multi-tenant incident management as a single platform instance serving multiple MSP clients while maintaining strict data boundaries. Unlike single-tenant deployments requiring separate tool instances per client, our approach shares infrastructure while keeping each customer's data isolated through access controls and private channels.
For incident response specifically, this architecture lets you oversee 50+ client environments from one operational dashboard. Your team works in one Slack workspace, one incident.io instance, and one set of workflows, but Client A's database credentials never appear in Client B's incident channels.
As the industry explains, "The architecture ensures that each tenant's data stays completely separate, even though they share the same platform."
How this differs from internal SRE work:
Internal SRE teams manage one technology stack, one organizational culture, and one set of service level objectives (SLOs) without financial penalties. MSPs operate under a fundamentally different model. You're a third-party company remotely managing multiple customers' IT infrastructure under contractual SLAs with financial penalties for breaches. This creates a one-to-many external service relationship requiring strict tenant isolation, varied SLA response windows, and diverse technology stacks managed simultaneously.
The unique challenges of MSP incident response
The isolation vs. efficiency tension:
You face a structural paradox. Your contracts demand strict data separation. Client A's database credentials, incident discussions, and post-mortems must remain invisible to anyone working Client B's issues. Yet your operational efficiency demands a single pane of glass where you see all active incidents, prioritize by SLA tier, and route alerts without logging into 50 different tool instances.
Legacy approaches fail here. Users report: "You end up copying data across portals, so efficiency decreases. Your reporting becomes a nightmare since the data's all over the place, some in the MSP space, some in email inboxes."
SLA complexity at scale:
SLA breaches carry severe financial consequences: "A percentage of the monthly fee refunded for each hour of unplanned downtime beyond the agreed limit. SLA breaches can cost anywhere from thousands to millions of dollars." For enterprises, downtime costs $300,000-$400,000 per hour.
Managing varied SLAs manually doesn't scale. Client A pays premium for 15-minute P1 response. Client B's contract allows 4-hour response. Client C has custom SLAs by service tier. Without automated SLA mapping to incidents, your responders either treat everything as urgent (burning out) or miss contractual obligations (triggering penalties).
The context-switching tax:
For MSP responders switching between client VPNs, separate Slack workspaces, distinct Jira projects, and client-specific runbooks, the cognitive load becomes unsustainable. One MSP engineer described the reality: logging into Client A's Jira, finding the incident ticket, opening Client A's Datadog in a separate browser profile, joining Client A's Slack workspace to communicate, then repeating the entire sequence for Client B when their alert fires 10 minutes later. Twenty minutes of tool navigation, zero minutes of problem-solving.
Why per-customer tracking is non-negotiable
Granular reporting for client trust:
You can't walk into Client A's QBR and say "your MTTR improved 30% this quarter" when your dashboard lumps all 50 clients together. We built per-customer tracking into incident.io's Catalog so you filter dashboards by client, export client-specific timelines, and demonstrate measurable improvements that justify contract renewals.
The Catalog supports custom "Customer" types specifically for this use case: "The categories that this type belongs to, to be shown in the web dashboard. Possible values are: customer, issue-tracker, product-feature, service, on-call, team, user."
Billing and compliance audit trails:
Many MSP contracts bill by incident count, response time, or engineer hours. Without per-incident customer tagging, you're manually reconstructing billable hours from Slack messages and calendar events. Compliance audits require complete, timestamped incident records. Per-customer tracking ensures audit trails isolate Client A's incidents from Client B's during compliance reviews.
Trust through transparency:
The ability to provide a client-specific post-mortem without manually redacting references to other clients signals operational maturity. You define customers as first-class objects in your Service Catalog, not afterthoughts in a notes field.
"The tool aligns itself with your current incident management process instead of forcing you to align your process with a tool." - Craig C on G2
How we built multi-tenant coordination into incident.io
We studied how MSPs actually work (juggling 50 alert streams, maintaining SLA contracts with financial penalties, onboarding new clients in days) and built incident.io around five core requirements:
1. Unified alert ingestion with automatic tenant identification
Our platform centralizes alerts from Datadog, Prometheus, New Relic, and custom webhooks across all your client environments. Map alerts to services, services to customers, and we automatically page the right people based on ownership. No manual lookup of "which client owns this service?"
2. Strict data isolation via private channels
Private Incidents create invitation-only Slack channels invisible to engineers not assigned to that customer. You work in one Slack workspace, but Client A's #inc-2847-database channel never appears in Client B responders' channel lists.
We designed this specifically for the "wrong window" fear. You can convert public incidents to private retroactively: "You can very easily convert a public incident into a private one by simply making the incident's #inc-... channel private from Slack. We'll take care of locking it down for you from here."
3. Service Catalog as operational CMDB
Our Catalog tracks services, teams, and custom types: "Use the incident.io catalog to track services, teams, product features and anything else that helps build a map of your organisation." For MSPs, create a custom "Customer" catalog type, then link services to customers.
When an alert fires for client-a-production-api, our platform automatically knows: Customer (Client A), SLA tier (Premium, 15-minute response), On-call engineer (Team assigned to Client A), Escalation path (Client A's dedicated TAM), Communication channel (Private incident, invite only Client A responders).
4. Workflow automation tied to customer attributes
Our workflows enable you to build customer-specific response automation: "When selecting the Affected Service, using the Catalog you could derive the Affected Team without having an Incident Responder select anything."
Real-world MSP workflow: When Customer = "Client A Premium" and Severity = P1, automatically invite Client A's Technical Account Manager to the private incident channel, post a status page update to Client A's dedicated status page, create a Jira ticket in Client A's project, and escalate to Client A's on-call engineer.
"The ability to integrate across all of our core tools has been amazing for us. We've gone from a program that leveraged mostly Slack to a program that can report on how our individual teams are doing and create unique workflows to involve the right individuals at the right time on incidents." - Craig C on G2
5. AI-powered communication drafting
Our AI capabilities include "real-time summarization, drafting clear and concise incident communications." For MSPs, this means the platform drafts the client-facing status update in Client A's tone (technical details for engineering-focused clients, high-level summaries for business-focused clients), requiring only human approval before publishing.
Best incident management tools for MSPs
incident.io (Best for Slack-native, modern MSPs)
We built incident.io's Service Catalog specifically for the MSP use case. Create a custom "Customer" catalog type, link your services to customer entries, and our platform automatically routes alerts, applies SLA policies, and generates per-customer reports.
How multi-tenancy works: Use Private Incidents to isolate sensitive client data within your team's single Slack workspace. Alert routes automatically create private channels when alerts match specific customer tags: "Alert routes set to create private incidents will only create private incidents, no matter the type."
MSP-specific automation: Workflow templates let you clone a "Standard Premium Client" workflow when onboarding new customers: "We've added 25 new templates to our workflows library, to help show the flexibility of workflows and make it really quick to get set up." Update the customer field, and escalation paths, status page routing, and SLA timers automatically adapt.
CRM integration: Salesforce integration syncs customer accounts directly: "You'll be able to see the list of your customers' accounts as entries under the new 'Salesforce Account' Catalog type." Your customer billing data, SLA tiers, and support contacts flow automatically into incident workflows.
"By automating the coordination, communication, and documentation tasks that are traditionally manual and time-consuming, incident.io frees up the incident response team to focus on solving the critical issues at hand." - Cameron R on G2
Pricing: Pro plan at $25/user/month for incident response, adding Microsoft Teams, unlimited workflows, and AI post-mortems. Add $20/user/month for on-call capabilities. Team plan available at $19/user/month for smaller MSP operations, with on-call at $12/month (monthly) or $10/month (annual). Book a free demo to see multi-tenant MSP workflows.
ServiceNow (Best for enterprise ITSM with ITIL requirements)
ServiceNow's "Domain Separation" feature isolates client data within a single instance. You get enterprise-grade compliance and ITIL process support. The trade-off: implementation measured in months, not days. Setup requires specialized ServiceNow administrators. Best for large MSPs with existing ServiceNow investments and clients demanding ITIL alignment.
Jira Service Management (Best for ticketing in Atlassian ecosystems)
Atlassian's approach uses separate service projects per client. Good for asynchronous ticket tracking. Community feedback reveals limitations for real-time coordination: "When Org 1 receives alerts, can they be isolated from Org 2 alerts? There are multiple teams in each Organization and we have difficulty in alert management." Best for MSPs prioritizing task management over real-time incident swarming.
How to structure a scalable MSP incident workflow
Here's the architecture we recommend, with specific incident.io features that automate each step:
Step 1: Centralize alert ingestion from all client monitoring
Configure webhook endpoints so every client's Datadog, Prometheus, and New Relic alerts flow into one feed. Use alert metadata (tags, labels) to identify the source client. Our alert routing with priorities lets you map Client A's P1 alerts to 'Critical' priority while Client B's map to 'High.'
- Impact: Reduce alert identification time by 85% (from 15 minutes to 2 minutes per incident)
- Owner: SRE Lead or DevOps Manager
- Time-to-value: 2-3 days to connect all monitoring integrations
- Resources: Webhook configuration guide
Step 2: Automate triage using Catalog-derived customer context
Build workflows that trigger on customer attributes: "If we know which services are affected by an incident, we can use Catalog to find not only the Teams that own that service, but also the right Slack channel so we can post a message to update them."
- Impact: Eliminate manual customer lookup, saving 5-10 minutes per incident
- Owner: Incident Response Team Lead
- Time-to-value: 1 week to configure initial workflows, then clone for new clients in minutes
- Resources: Getting started with workflows
Step 3: Isolate communication channels with private incidents
Configure alert routes to create private incidents for sensitive clients. This ensures Client A's #inc-2847-database-latency channel remains invisible to engineers not assigned to Client A's response team.
- Impact: Zero data leakage incidents, 100% client data isolation
- Owner: Security Lead or Compliance Manager
- Time-to-value: Immediate (configure once per customer tier)
- Resources: Creating private incidents from alerts
Step 4: Auto-draft client communications with AI
Leverage our AI to draft status updates. The AI understands Client A prefers technical detail ("database connection pool exhausted, scaling RDS instance") while Client B prefers business impact summaries ("checkout temporarily degraded, fix in progress").
- Impact: Reduce communication drafting time by 70% (from 10 minutes to 3 minutes)
- Owner: Customer Success Manager or Incident Commander
- Time-to-value: 2-3 weeks for AI to learn client preferences from edited drafts
- Resources: AI capabilities overview
Step 5: Generate unified per-customer reporting automatically
Filter the dashboard to Customer = "Client A", select Q1 2026 date range, and export MTTR trends, incident volume by service, and top root causes for QBRs.
- Impact: Reduce QBR report preparation time by 90% (from 3 hours to 15 minutes)
- Owner: Account Manager or Technical Account Manager
- Time-to-value: Immediate once Catalog is configured
- Resources: Using the Catalog
What you need in multi-tenant MSP environments
You manage incident response for an MSP serving 30 clients. Each has distinct SLA tiers, tech stacks, and escalation requirements. Your team handles 40-60 incidents monthly across this client base. The challenges compound:
Onboarding velocity matters: When your MSP wins a new client, you have 3 days to set up monitoring integrations, on-call schedules, escalation paths, and runbooks before service goes live. Legacy tools requiring per-client instance configuration turn this into a 2-week project. Our workflow templates solve this. Clone a "Standard Premium Client" workflow and update one customer field.
Cognitive load kills on-call morale: Your junior engineers refuse on-call shifts because they can't remember which Slack workspace corresponds to which client, which VPN to connect to first, or who owns the payments-api service for Client A vs. Client B.
Our Catalog-driven automation addresses this directly: "Map alerts to services, services to teams, and we'll automatically page the right people based on ownership, every time. Auto-invite the right people to the right channels, triggering workflows or updates based on team or product ownership."
"We've been using Incident.io for some time now, and it's been a game-changer for our incident management processes. With seamless integrations into Slack, Jira, and Confluence, it has become our go-to for bringing teams together to tackle incidents faster and more efficiently." - Pratik A on G2
Multi-tenant vs. multi-instance architectures
You face a fundamental architecture decision: deploy one platform instance serving all clients (multi-tenant) or deploy separate instances per client (multi-instance)?
Multi-tenant architecture: Software multitenancy means "a single instance of software runs on a server and serves multiple tenants." One incident.io workspace manages all 50 clients with Catalog-based customer separation and Private Incident data isolation.
Multi-instance architecture: "Each customer runs on a separate software instance, requiring individual updates, configurations, and monitoring". Fifty clients mean fifty Slack workspaces, fifty incident.io dashboards, and fifty on-call schedule configurations to maintain.
Cost implications: Multi-instance architectures carry hidden costs: "Each of your customers has their own dedicated infrastructure, you will need to provision each infrastructure, maintain it and update it separately. Higher total cost: This choice of architecture is less cost-effective."
Why multi-tenant wins: The unified view benefit explains the MSP advantage: "Multi-tenant MSP tools provide centralized management via unified dashboards, offering full oversight across all client environments. This single-pane-of-glass approach removes the complexity of managing diverse networks."
Ensuring client data isolation in Slack
The nightmare scenario: an engineer pastes Client A's database credentials into Client B's incident channel. Slack's security best practices provide the foundation: "Private channels in Slack provide a secure space to hold sensitive discussions by limiting access to authorized team members only."
Our private incident integration: Converting incidents to private happens instantly: "You can very easily convert a public incident into a private one by simply making the incident's #inc-... channel private from Slack."
Additional Slack controls include: "Two-factor authentication (2FA), limiting members to verified domains, requiring admin approval for each new user, and deactivating inactive users can all help to restrict data access to employees only."
Slack Connect for external client collaboration: When clients need incident visibility, Slack Connect enables secure external collaboration: "Slack Connect is a secure way to collaborate across organizations, right in Slack." Client A's product manager can join their incident channel without accessing your MSP's main workspace.
Scale MSP operations without scaling headcount
Multi-tenant incident coordination is how you grow from 10 clients to 100 without linear cost increases. The architecture you choose determines whether you provide transparency and confidence to clients, or drown in tool sprawl and missed SLAs.
We built incident.io for MSPs who need strict data isolation without sacrificing operational speed. Our Service Catalog maps your clients to workflows automatically. Our Private Incidents maintain boundaries. Our AI drafts customer-specific communications. Your team works in one platform while managing 50 distinct customer environments.
Learn more about our approach to service management in this interview with CTO Chris Evans discussing what reliability really means for growing organizations.
Ready to see how Catalog-driven automation eliminates the multi-tenant coordination tax? Try incident.io in a free demo and run your first multi-customer incident workflow to see how managing 50 clients can feel like managing one.
Key terms glossary
Multi-tenancy: Software architecture where one platform instance serves multiple clients (tenants) with shared infrastructure but isolated data, access controls, and configurations per tenant.
Service Catalog: Central repository tracking services, teams, dependencies, and metadata. For MSPs, maps services to customers, enabling automated routing and reporting per client.
Private Incident: Incident with restricted visibility, typically using private Slack channels where only invited members see timeline, messages, and post-mortem. Essential for sensitive client data isolation.
SLA (Service Level Agreement): Contractual commitment defining response times, uptime guarantees, and penalties for breaches. MSPs manage different SLAs per client tier.
MTTR (Mean Time To Resolution): Average time from incident detection to resolution. Critical MSP metric tracked per customer to demonstrate service quality improvements.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

