What is an AI SRE agent? Definition, use cases & examples
January 8, 2026 — 16 min read
Updated January 8, 2026
TL;DR: An AI SRE agent observes your infrastructure, reasons about root causes using historical patterns, and executes remediation workflows autonomously. Unlike traditional "if X, then Y" automation, AI agents analyze context from code changes, alerts, and past incidents to make decisions. We've seen teams reduce incident management MTTR by up to 80% by eliminating the coordination tax that consumes most of an incident's first 10 minutes. AI agents handle triage, root cause correlation, and post-mortem drafting while you focus on complex decision-making.
Your median incident costs 48 minutes of MTTR today. Here's the breakdown: 15 minutes assembling the team and gathering context, 20 minutes actual troubleshooting, 13 minutes updating tools and starting documentation. The technical fix is the minority of the work.
AI SRE agents attack that 15-minute coordination tax directly. When Datadog fires an alert, you wake up to a Slack channel where the agent has already identified the likely cause, pulled relevant metrics, and drafted a fix awaiting your approval. This article defines what AI SRE agents are, how they differ from traditional automation and AIOps, and what tasks they can autonomously handle — for a deeper dive, see our complete guide to AI SRE.
What is an AI SRE agent?
An AI SRE agent is a software system that combines observability data, reasoning capabilities, and action execution to autonomously manage reliability tasks. Unlike passive AI assistants that suggest actions upon request, AI SRE agents perceive their environment, reason, plan, and execute multi-step tasks independently to achieve specific goals.
The key word is autonomous. Traditional automation waits for you to trigger it. An AI SRE agent watches your infrastructure continuously, identifies issues, surfaces root causes, and takes action to help resolve them — working best alongside smart on-call scheduling to ensure the right engineer is always reachable. Think of it as a senior engineer who never sleeps, never gets overwhelmed, and always remembers the last 500 similar incidents.
What problem does this solve?
The enemy here is toil. The Google SRE book defines toil as "work that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows." Quarterly surveys at Google show SREs spend about 33% of their time toiling, with a target below 50%. AI SRE agents attack this directly, handling the first minutes of triage so you can focus on complex decision-making that requires human judgment — and on-call software is what connects those agents to your team.
"The tool significantly reduces the time it takes to kick off an incident. The workflows enable our teams to focus on resolving issues while getting gentle nudges from the tool to provide updates and assign actions, roles, and responsibilities." - Verified user review of incident.io
How is this different from AIOps?
AIOps and AI SRE agents overlap but differ in one critical way — see a comparison of the leading AI-powered SRE tools to understand how they stack up.
Traditional AIOps functions as an advanced tool that augments your capabilities, providing recommendations and insights that require your interpretation and action. It highlights anomalies and correlates logs, but stops at insights.
AI SRE agents go further. They adapt, learn, and act in real time. Agentic AIOps deploys AI agents to make real-time decisions and take corrective action automatically, building directly on operational insights rather than waiting for you to interpret them.
AI SRE agents vs. traditional runbook automation
Here's how static automation compares to dynamic AI agents:
| Feature | Traditional automation | AI SRE agent |
|---|---|---|
| Trigger | Predefined threshold crossed | Correlates multiple signals, suppresses duplicates, enriches alerts with context |
| Context awareness | Limited. Executes predefined steps | Connects telemetry, code changes, and past incidents to understand why |
| Adaptability | Brittle. Breaks when conditions change | Learns from feedback. Improves over time |
| Maintenance | High. You must constantly update scripts as infrastructure evolves | Lower. The agent adapts to new patterns without rewriting scripts |
| Example action | "Restart pod when memory exceeds threshold" | "Memory spike correlates with recent deploy. Similar pattern caused outage last month. Suggesting rollback." |
Traditional automation follows a script. If memory exceeds a threshold, restart the pod. The problem? This works until it doesn't. When the root cause is a memory leak in new code, restarting the pod just delays the inevitable and masks the real issue.
AI SRE agents analyze context. They see that the memory spike started shortly after a deploy, that similar patterns caused incidents previously, and that the code change affected the caching layer. Instead of blindly restarting, the agent surfaces this context and suggests a rollback.
"It's tempting to build a Slack-based incident system yourself, don't. Incident has a very responsive and competent team. They have built a system with sane defaults and building blocks to customize everything." - Verified user review of incident.io
For a deep dive into how this works in practice, watch How to automate incident resolution with AI SRE from our engineering team.
Core capabilities: What can an AI SRE agent actually do?
AI SRE agents deliver four capabilities that directly reduce toil and MTTR.
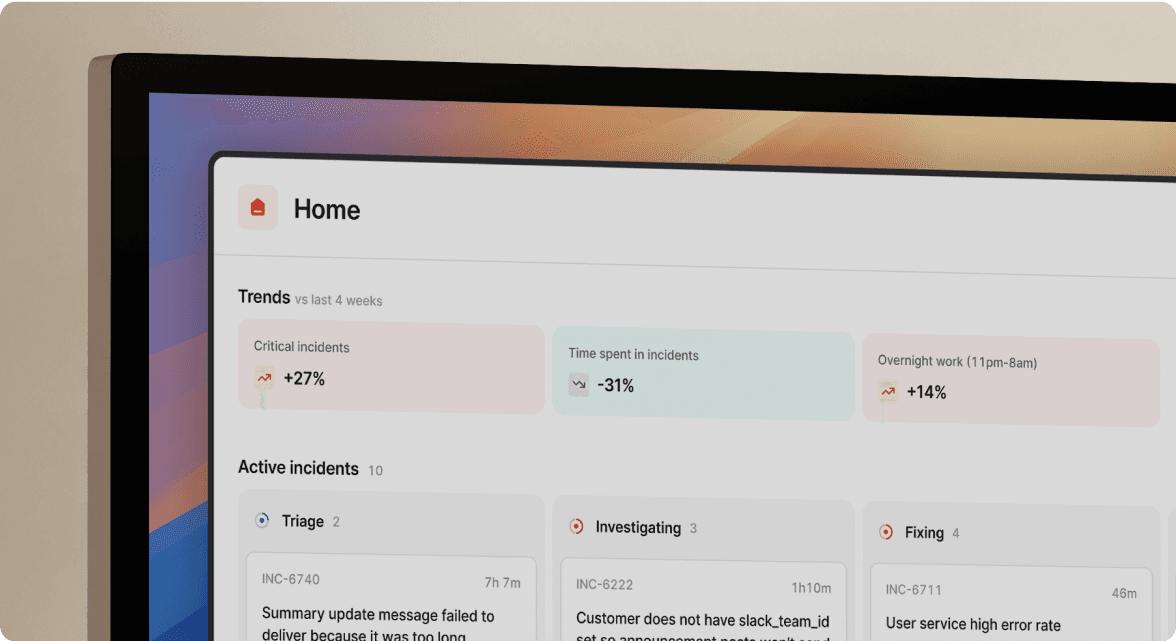
1. Autonomous alert triage: When Datadog or Prometheus fires an alert, the agent doesn't just pass it through. It correlates related signals, suppresses duplicates, and enriches the primary alert with relevant context: recent code changes, related infrastructure events, and service ownership from your catalog. Instead of wading through dozens of alerts during an incident, you see a single, enriched notification that tells you what's happening, what likely caused it, and who owns the affected service.
2. Automated root cause analysis (RCA): This is where AI agents differentiate from basic automation. AI SRE pulls data from alerts, telemetry, code changes, and past incidents to cut through the noise and pinpoint the problem. The agent connects telemetry data showing when the problem started, recent deploys and config updates, and similar patterns from your incident history. Rather than saying "latency is high," the agent says "latency spiked shortly after a deploy that modified database connection pool settings."
3. Remediation workflows: AI agents can execute steps like rolling back a deploy, scaling a fleet, or restarting a pod. The critical distinction is that well-designed agents use human-in-the-loop approval for high-risk actions. The agent identifies the issue, proposes a fix with supporting evidence, you approve via Slack command, the agent executes, and monitors for improvement.
4. Context gathering: During an incident, the agent automatically pulls relevant graphs, logs, runbooks, and service owner details into the Slack channel. No more hunting through multiple browser tabs while your site is down.
"AI features that provide actual value during and after the incident... Frictionless configuration and onboarding (so easy that our first incident was created/led by a colleague even before the 'official rollout' all by themselves!)" - Verified user review of incident.io
The role of AI in incident post-mortems
Manual post-mortem reconstruction wastes significant time per incident as you search through chat history, monitoring tools, and call recordings trying to piece together what happened. This is what we call the "post-mortem archaeology" problem: by the time you write the document, your memory has faded and details are fuzzy.
AI SRE agents solve this by observing the incident timeline in real time.
How timeline-based post-mortems work:
When you run an incident using /inc commands, every action auto-populates the timeline: role assignments, severity changes, Slack threads, shared links. Our Scribe feature (AI-powered transcription) records and transcribes incident calls, capturing decisions made verbally without requiring a dedicated note-taker.
Scribe generates structured call notes in real time, featuring key moments, important decisions, and next steps along with the participant list. When you type /inc resolve, the post-mortem is drafted automatically using captured data, including incident summary, timeline of events, contributing factors, and suggested action items.
The difference is "reconstructing memory" vs. "summarizing facts." You spend 15 minutes editing an 80% complete document instead of 90 minutes writing from scratch.
"Using incident.io has significantly streamlined our incident management process. The tool's ability to auto-populate incident documentation has saved us a good amount of time, allowing our team to focus on resolving issues rather than on administrative tasks." - Verified user review of incident.io
For a walkthrough of how this works, see Building an AI incident responder on our YouTube channel.
Real-world examples: Reducing toil with AI agents
Let me walk through two scenarios showing AI SRE agents in action.
Scenario A: Automated triage
Before AI SRE:
- Alert fires at 2:47 AM
- On-call engineer opens monitoring tool, then Slack
- Manually creates incident channel
- Searches documentation for service owner
- Pings team members individually
- Opens runbook in another tab
- Significant time elapses before troubleshooting starts
After AI SRE:
- Alert fires at 2:47 AM
- AI agent auto-creates dedicated Slack channel
- Agent checks service catalog, identifies owner, pages correct team
- Agent summarizes issue with correlation to recent changes
- Agent pulls relevant dashboards into channel
- Team assembled and oriented within minutes
Scenario B: Remediation with human approval
Before AI SRE:
- High error rate detected
- Engineer manually reviews logs, metrics, recent deploys
- Identifies config change as likely cause
- Drafts rollback plan
- Gets verbal approval
- Executes rollback manually
- Updates status page and creates tickets manually
After AI SRE:
- High error rate detected
- AI agent identifies recent change as likely cause based on timing correlation
- Agent proposes rollback with evidence
- Engineer reviews evidence, approves via
/inc approve-rollback - Agent executes rollback
- Agent updates status page and creates follow-up ticket automatically
What the data shows:
Organizations implementing AIOps report MTTR reductions of around 40%. Our AI-powered incident management can reduce MTTR by up to 80% by eliminating coordination overhead. The cost of not acting is significant: ITIC's 2024 survey found over 90% of mid-size and large enterprises report downtime costs upward of $300,000 per hour.
"The velocity of development and integrations is second to none. Having the ability to manage an incident through raising, triage, resolution, post-mortem all from Slack is wonderful." - Verified user review of incident.io
How to implement AI SRE agents in your workflow
Based on case studies from enterprises adopting AIOps, here's a practical implementation path.
- Centralize your data (service catalog): Before an AI agent can help, it needs to know your infrastructure. Build or populate a service catalog that includes service ownership, dependencies, runbook locations, and recent deployments. Our Catalog feature handles this integration, connecting to GitHub, Jira, and your monitoring tools.
- Integrate your existing tools: Connect observability tools (Datadog, Prometheus, New Relic), your CI/CD pipeline (GitHub, Jenkins), and communication platforms (Slack or Microsoft Teams). See our guide on migrating Datadog monitors to incident.io for a practical integration example.
- Start with human-in-the-loop: To minimize risk, set up human-in-the-loop approval for any self-healing actions and limit automation to low-risk playbooks initially. This means AI suggests, human approves, with all automated actions logged and reversible. The AI only escalates when it has a high-confidence assessment, complete with a preliminary investigation summary.
- Gradual automation for low-risk tasks: As trust grows, expand automation to safe runbooks: auto-restart containers on resource issues, scale clusters on saturation, roll back deployments when errors spike. The key is feedback loops. Every suggestion or automated action should be reviewed, and this feedback improves the system over time.
"A true leader in the incident management space. Their data model is incredibly flexible and they continue to improve their core product at a steady pace." - Verified user review of incident.io
For teams evaluating platforms, watch When AI Becomes Your SRE: How Incident.io Is Automating Incident Response for a detailed product walkthrough.
Security and trust considerations
AI SRE agents touch production systems, which raises legitimate security concerns. Here's how we address them.
Compliance and certifications: We're SOC 2 Type II certified, meaning an external auditor has verified that we meet high security standards for the security, availability, and privacy of data. Our platform is also GDPR compliant.
Controlling sensitive information: During incident calls, you may need to discuss sensitive information you don't want transcribed. Our Scribe feature lets you add or remove transcription from calls on the fly, giving you control over what gets captured. For sensitive incidents, you can mark them as sensitive and restrict access to specific team members.
Enterprise controls: For organizations requiring advanced security, SAML/SCIM support on Enterprise plans enables centralized identity management.
Try AI SRE in your workflow
If you spend more time coordinating than troubleshooting, AI SRE agents can help. Run your first incident in Slack and see how the AI handles triage, context gathering, and post-mortem drafting. For a live demonstration of AI SRE capabilities, book a demo with our team.
Key terminology
AI SRE agent: An autonomous system that observes infrastructure health, reasons about root causes using historical patterns, and executes remediation workflows to manage reliability tasks.
Toil: Work that is manual, repetitive, automatable, tactical, devoid of enduring value, and scales linearly as a service grows. The enemy that AI SRE agents are designed to eliminate.
MTTR (Mean Time To Resolution): The average time from when an incident is detected to when it is fully resolved. AI SRE agents target MTTR reduction by eliminating coordination overhead.
RCA (Root Cause Analysis): The process of identifying the underlying cause of an incident. AI agents perform automated RCA by correlating alerts, code changes, and historical incidents.
Human-in-the-loop: An implementation pattern where AI systems suggest actions but require human approval before executing. Recommended for initial AI SRE deployments to build trust.
Observability: The ability to understand a system's internal state based on its external outputs (metrics, logs, traces). AI SRE agents depend on observability data to identify and correlate incidents.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

