99.9% vs 99.99% uptime for on-call tools: Why that extra nine matters at 3am
May 29, 2026 — 26 min read
TL;DR: 99.9% uptime sounds reliable until you do the math: it permits 43 minutes of potential pager downtime every month. During that window, a production outage can burn silently while your on-call engineer sleeps. PagerDuty publishes a 99.9% SLA for notification delivery. incident.io contractually commits to 99.99%, cutting allowable downtime to 4.4 minutes per month. For a CRM, that gap is a minor annoyance. For an on-call tool, it's the difference between a 2-minute response and a customer-reported outage discovered long before your team was ever paged.
Most engineering teams obsess over the uptime of their microservices while ignoring the uptime of the tool supposed to tell them when those services fail. This article breaks down the mathematical reality of 99.9% vs 99.99% uptime, compares PagerDuty's published SLA against incident.io's contractual commitment, and explains why that extra nine is the difference between a fast resolution and a 3am call from your VP of Engineering asking why customers discovered the outage first.
Why on-call tool uptime is categorically different from other SaaS
When your project management tool goes down, engineers find workarounds and catch up later. When your documentation wiki is unavailable, someone checks local notes. These failures are visible, immediately obvious, and bounded in their damage.
An on-call tool failure creates something different: a blind window. A period where production degrades or fails completely while your entire on-call rotation sleeps through it. You don't know what you don't know. The pager is silent not because everything is fine, but because the pager itself can't tell you otherwise. That asymmetry creates a categorically different problem for on-call tool reliability than any other SaaS uptime discussion you'll have.
Planning for missed outages and silent failures
Engineering teams plan extensively for infrastructure failure. You run chaos engineering experiments, configure redundant availability zones, test database failover paths, and document escalation runbooks for every major service. Few teams run game days simulating alerting tool unavailability, yet the operational consequence is comparable to your database going down: your engineers are flying blind during what may be your worst production event of the quarter.
On-call tool downtime belongs in the same risk register as database failures. The worst-case scenario isn't delayed alerts. It's an alert that never arrives at all. Consider a typical failure mode: a production service fails during off-hours, your monitoring system fires an alert to your on-call tool, but the tool is experiencing a partial outage. Your on-call engineer never gets paged. The outage continues undetected until a customer reports it. That customer-reported outage doesn't just inflate MTTR. It erodes customer trust, floods support queues, and forces you to explain in a post-mortem why your own tooling failed before your production systems did.
How pager downtime inflates MTTR
MTTR (Mean Time To Resolution) starts the moment an alert fires. When your pager tool is unavailable, the MTTR clock doesn't actually start until someone manually discovers the outage or a customer files a support ticket. Every minute of pager downtime adds directly to your MTTR baseline before any troubleshooting begins.
If your current P1 (Priority 1, or P0 at teams where that is the highest severity classification) MTTR is 45 minutes and your pager tool is unavailable for 15 minutes before alerts resume delivery, your effective MTTR for that incident becomes 60 minutes minimum, with zero engineering work done in the first 15. You didn't get slower at fixing problems. Your alerting tool failed to start the clock, and the math is unforgiving. The incident.io alert priorities and routing documentation details how priority-based routing and escalation paths protect against delayed response, but routing logic can't help if the underlying platform isn't delivering notifications.
Understanding downtime differences: 99.9% vs 99.99%
The "nines" conversation sounds academic until you translate percentages into actual minutes and hours. Each additional nine doesn't add a fixed increment of reliability. It cuts allowable downtime by a factor of ten, and that non-linear relationship is what makes the jump from three nines to four nines so significant for tools where every minute of unavailability has direct operational consequences.
99.9% availability: 8.76 hours of annual downtime
99.9% uptime means your service is unavailable 0.1% of the time. Run that math annually and 99.9% allows 8.76 hours of total downtime per year. That's more than a full workday of potential unavailability spread across 12 months.
For most SaaS tools, 8.76 hours of annual downtime is acceptable. For an on-call alerting platform, 8.76 hours of annual unavailability means 8.76 hours where your entire production monitoring chain can fail silently. Spread unevenly across the year, a single extended outage during a high-deployment window can be catastrophic. PagerDuty's published SLA for notification delivery sits at 99.9% per calendar month, covering the commitment that once an incident is triggered, the platform delivers the first responder notification within a five-minute window at that rate. That's the contractual baseline your team operates under today if you're on PagerDuty.
99.99% uptime: the 52-minute impact
Move to 99.99% and the math changes dramatically. 99.99% uptime allows 52.6 minutes of total downtime per year. Not per month. Per year. That's a reduction from 8.76 hours to less than one hour of allowable annual unavailability.
For context, PagerDuty's August 2025 Kafka outage caused cascading notification failures lasting over six hours. Under a 99.99% SLA with its 52.6-minute annual error budget, a single incident of that duration represents a full-year SLA breach in one event. Under a 99.9% SLA, the same outage consumes the majority of the 8.76-hour annual allowance, meaning one or two comparable incidents exhaust the entire year's buffer before any contractual breach is triggered. incident.io contractually commits to 99.99% uptime as part of its SLA guarantee, framing the on-call tool as the last thing that should go down when production is under stress.
Monthly on-call burden: 43 vs 4 min
PagerDuty advertises a 99.9% uptime SLA, which translates to roughly 43 minutes of allowed downtime per month or about 8.76 hours per year. The SLA is published on their website and incorporated by reference into customer contracts, meaning the contractual guarantee is tied to external documentation rather than fully embedded terms.
incident.io, by contrast, offers a 99.99% contractual SLA, reducing allowable downtime to around 4.4 minutes per month or approximately 52.6 minutes per year. This SLA is directly embedded in the contract itself, making the guarantee explicit rather than indirectly referenced.
The practical difference is a full order of magnitude in tolerated downtime, from hours per year down to under one hour. This shifts the framing from “high availability with occasional disruption” to “near-continuous operational reliability,” which matters most for teams running always-on incident workflows.
Lost alert time: impact on MTTR
Connect the monthly math to your actual incident workload. If your team handles 18 incidents per month and your alerting tool is unavailable for 43 minutes distributed across that month, every incident that fires during a downtime window starts with an MTTR penalty that has nothing to do with your engineering response quality. Scale that across a year and you're absorbing hundreds of minutes of preventable delay, none of which reflects poorly on your engineers, all of which reflects on your tooling choice.
PagerDuty's published SLA vs incident.io's contractual commitment
Understanding the difference between a published SLA and a contractual SLA matters as much as understanding the uptime numbers themselves. The legal and operational implications diverge significantly.
PagerDuty: 99.9% uptime baseline
PagerDuty's standard service level agreement commits to delivering first responder notifications within the five-minute notification delivery period 99.9% of the time during any calendar month. PagerDuty's published SLA covers notification delivery and web application availability at 99.9%, with workflow automation not explicitly listed as a covered service in the publicly available SLA document.
A few details in that SLA deserve close reading. PagerDuty explicitly excludes from SLA calculations any failures caused by factors outside their control, including customer telecommunications providers, delivery service providers, email domain server availability, and mobile push notification providers. Given that most alert delivery goes through at least one of those categories, the practical coverage of the SLA is narrower than the headline 99.9% suggests. The remedy for breaches is service credits, capped at a maximum of 30% of total fees paid for the calendar month in which the breach occurred.
PagerDuty has also experienced documented outages affecting notification delivery. Their platform suffered a significant outage in August 2025 caused by a Kafka library issue that resulted in cascading cluster failures, with Kafka tracking nearly 4.2 million extra producers per hour at peak, exhausting the JVM heap. A subsequent incident in October 2025 tied to the AWS US-EAST-1 regional failure affected PagerDuty's Workflow Automation capabilities. Independent monitoring tools like IsDown.app track these events and their resolution times, providing a record of actual platform availability beyond published SLA claims.
Ensuring 99.99% uptime: our SLA
incident.io's 99.99% uptime commitment is part of the Rescue Program SLA guarantee, offered contractually to customers and available as the standard availability commitment across the platform. The commitment covers the on-call alerting infrastructure with the explicit framing that the on-call tool should be the last thing that goes down when production is under stress.
The difference between incident.io's approach and PagerDuty's isn't just the number. It's the contractual weight. incident.io's 99.99% commitment is incorporated directly into customer contracts as an enforceable obligation, meaning a binding term with defined remedies if breached, that your legal team can evaluate during procurement, your finance team can hold the vendor accountable to at renewal, and your CISO can cite as documented evidence during security reviews or supplier risk assessments. The incident.io vs PagerDuty comparison guide breaks down the full platform differences, but the SLA structure is where the reliability conversation starts for most enterprise evaluations.
Uptime types: what's guaranteed?
Not all uptime guarantees cover the same components. When evaluating an on-call tool SLA, you need to understand which specific services are covered and which are excluded.
incident.io's uptime commitment covers:
- API availability: The foundation that all integrations and external triggers depend on.
- Alert delivery: The core on-call function, ensuring triggered alerts reach on-call engineers.
- On-call scheduling: The rotation and escalation logic that determines who gets paged.
- Status pages: Customer-facing communication that auto-updates during incidents.
For CISO (Chief Information Security Officer) and security teams evaluating vendor reliability, incident.io's SOC 2 (System and Organization Controls 2) Type II certification, an independent audit confirming that security and availability controls have operated effectively over a sustained period, and continuous security monitoring provides an additional layer of documented assurance beyond SLA commitments. The platform uses AES-256 encryption at rest, and the SOC 2 framework covers security, availability, and privacy controls.
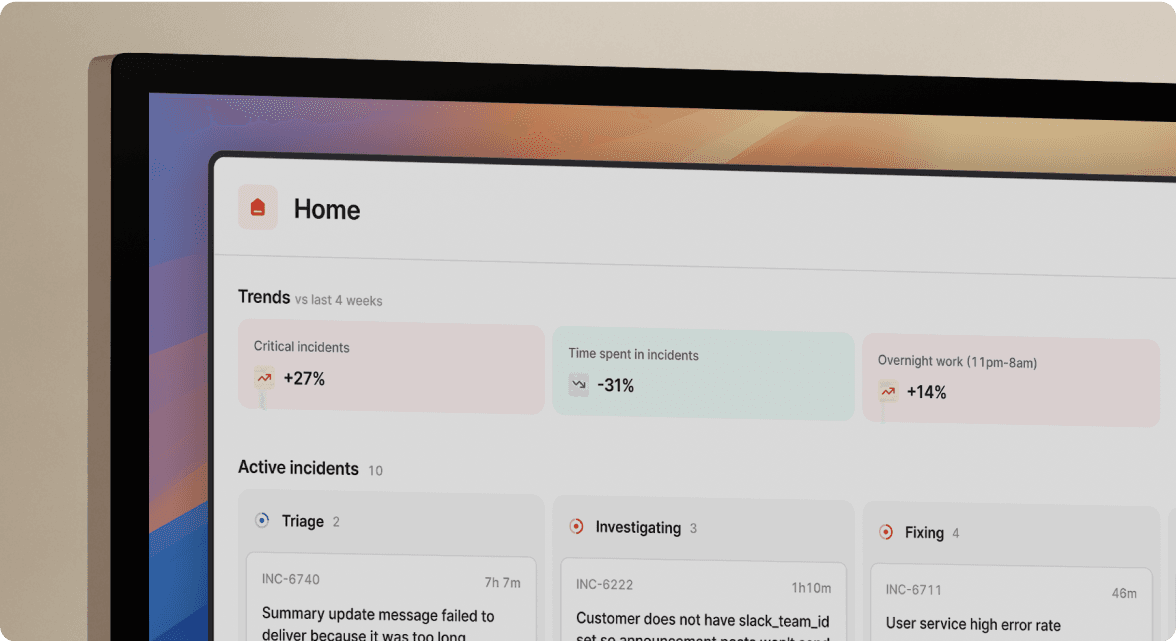
Your 99.99% incident dashboard guarantee
incident.io's dashboard maintains 99.99% uptime, and the Insights dashboard gives your engineering team access to incident metrics like MTTR and resolution times when reporting reliability performance to leadership.
Zero tolerance: why small errors have big impact
43 minutes of monthly downtime sounds manageable in isolation. In context, it isn't. On-call tools operate at the intersection of every other reliability decision your team makes, and a small window of alerting tool unavailability doesn't create a small incident. It creates a cascading failure of your entire incident response process.
Ensuring your critical alerts fire
The incident.io advanced on-call scheduling system ensures alert routing logic doesn't rely on a single path to your on-call engineer. Escalation paths move through configured fallbacks automatically, and the alert deduplication system ensures that alert storms during complex incidents don't create noise that causes engineers to miss critical notifications. The on-call scheduling strategies guide explains how rotation models and escalation design reduce the risk of missed alerts regardless of incident complexity.
"Their product is responsive and reliable, and the new features are all well thought out." - Bertrand J. on G2
Customer discovers the incident before your team does
The ultimate failure mode of any on-call system is the customer-reported outage. It means your entire alerting and escalation chain failed silently while a real customer experienced a real degradation. That failure doesn't just affect MTTR. It affects customer trust, support ticket volume, and the credibility of your SRE team's reliability claims to leadership.
The August 2025 PagerDuty Kafka outage illustrated this directly: teams lost alert delivery while production systems continued to degrade, with no automated notification reaching on-call engineers until the platform recovered.
Teams that have experienced customer-reported outages after tool failures consistently cite pager reliability as the non-negotiable evaluation criterion above features, pricing, or ease of use. The on-demand session on migrating from PagerDuty covers exactly this scenario as a primary driver for migration decisions. When production burns silently because the pager didn't fire, everything else becomes secondary.
How delayed response inflates MTTR
A database connection pool exhaustion degrades API response times at 2:31am. The monitoring alert fires and hits the on-call tool, but the tool is experiencing a partial outage affecting notification delivery. No one gets paged. The outage continues undetected. Eventually, a customer reports the outage through a support channel. A support engineer escalates to engineering. The on-call SRE is manually contacted and joins the response well after the alert originally fired. Every one of those minutes before the engineer engages represents pager failure, not engineering response time. The actual fix, once the SRE has context, takes significantly less time than the delay that preceded it.
This is the MTTR tax that pager downtime imposes: a fixed penalty added to every incident that coincides with a tool outage, before engineering work has even started. Scale that across 18 incidents per month and the cumulative impact on your quarterly MTTR numbers is substantial, and entirely preventable.
Accelerated deployments drive more incidents
The reliability requirement for on-call tools has become more demanding as deployment velocity increases. The argument for 99.99% uptime isn't just about historical outage patterns. It's about the direction engineering environments are moving.
AI-speed deployments strain on-call
Coding agents and AI-assisted development have fundamentally changed how frequently code reaches production. Deployment frequency is rising at companies using AI-assisted development, creating more opportunities for deployment-triggered incidents. A pager built for human-speed development doesn't scale to agent-speed deployment.
More frequent deployments mean more frequent incidents, and more opportunities for your on-call tool to be unavailable during a critical alert. High-deployment periods, which are also high-incident periods, are the most likely times for both failures to coincide. The incident.io AI-powered incident response overview demonstrates how AI SRE capabilities handle the volume of modern deployment-triggered incidents, but only if the underlying alert delivery is reliable enough to start the process. The on-call tool selection framework for 2026 covers how deployment velocity should factor into SLA evaluation criteria.
What to look for in an on-call tool SLA
Evaluating an on-call tool SLA requires asking different questions than you'd ask about a CRM or project management tool. The stakes of an alerting failure are higher, so the scrutiny should be proportionally more rigorous.
Contractual vs. published uptime commitments
The first question when evaluating any vendor SLA isn't "what percentage do they commit to?" It's "is this percentage incorporated into my contract?" If a vendor publishes 99.9% on their website but your signed agreement makes no explicit reference to that document, you have no enforceable SLA at all. Published SLAs are statements of intent. Contractual SLAs are obligations. Ask for the specific contract language and verify whether the uptime commitment sits in the MSA, the Order Form, or a separate SLA exhibit with defined remedies.
SLA focus: alert delivery reliability
The dashboard UI can be unavailable for 10 minutes without affecting your incident response. Alert delivery cannot. When evaluating any on-call tool SLA, verify that the uptime commitment specifies what availability level applies to alert notification delivery specifically, a vendor may commit to 99.99% for the dashboard while committing to a higher or lower standard for alert delivery itself.
Within incident.io's 99.99% SLA, the most operationally critical components, alert delivery, API, on-call scheduling, and status pages each carry a 100% uptime commitment, with the 99.99% figure applying to the dashboard. An SLA that does not explicitly cover alert delivery leaves your on-call team without a contractual reliability guarantee for the most critical function. The incident.io alert delivery documentation details which delivery paths fall under these uptime commitments.
SLA credits and what they actually cover
Service credits are accounting adjustments applied to future invoices when a vendor breaches their SLA. If your on-call tool costs $5,000 per month and experiences an outage that causes a customer-facing incident worth $200,000 in direct and indirect losses, the service credit you'd receive is a small fraction of that impact.
Service credits provide financial remedy for SLA breaches but rarely approach the actual cost of a significant outage. A vendor that contractually commits to 99.99% uptime establishes a higher standard than one offering 99.9%, creating clearer expectations for both parties regardless of the specific credit structure.
Switch to incident.io with the Rescue Program SLA guarantee
The mathematical and contractual case for 99.99% uptime is clear. The question for your team is whether your current tool meets that standard, and what the path to higher reliability looks like if it doesn't.
Guaranteed 99.99% uptime SLA
incident.io's Rescue Program offers PagerDuty customers a direct migration path with a contractual 99.99% uptime SLA guarantee built in from day one. The program targets teams that have experienced the blind window problem, whether through a documented pager outage or through the cumulative risk awareness that comes from doing the math on 43 minutes of monthly allowable downtime.
The 99.99% commitment isn't a marketing claim. It's the same standard we hold our own on-call infrastructure to, grounded in the recognition that an on-call tool vendor that can't maintain 99.99% uptime for alert delivery has a fundamental reliability problem that no feature set compensates for.
"Clearly built by a team of people who have been through the panic and despair of a poorly run incident. They have taken all those learnings to heart and made something that automates, clarifies and enables your teams to concentrate on fixing, communicating and, most importantly, learning from the incidents that happen." - Rob L. on G2
Rescue Program: achieving 99.99% uptime
The Rescue Program removes the three main friction points that keep teams on tools with inferior SLA commitments:
- Contract buyout: If you're mid-contract with PagerDuty, incident.io offers up to one year of the platform at no cost when you sign a multi-year deal, so you don't pay two vendors simultaneously while migrating.
- AI-powered migration: An AI migration assistant scans your entire PagerDuty account in minutes, categorizing every service and mapping dependencies, then produces a full migration report. The migration tooling documentation details the built-in tools that let engineering teams complete migrations in days. The migration changelog shows how this tooling has been continuously improved based on real customer feedback.
- Unified platform under a single SLA: Post-migration, your team moves from five tools to one Slack-native platform covering on-call scheduling, alert routing, incident response coordination, status pages, and post-mortem generation, all under a single contractual 99.99% uptime commitment.
The on-call onboarding playbook and 30-day onboarding checklist ensure that once migrated, new on-call engineers are productive within days using Slack-native /inc commands.
If your team is ready to move from 43 minutes of monthly allowable pager downtime to 4 minutes, schedule a demo of incident.io to see the platform in a live incident scenario.
Key terms glossary
MTTR (Mean Time To Resolution): The average time from when an incident alert fires to when the incident is fully resolved. Pager tool downtime inflates MTTR by adding pre-response delay that has nothing to do with engineering fix time.
Published SLA: A vendor's stated service uptime standard, typically on their website or support documentation. Enforceable only if explicitly referenced in a signed contract.
Contractual SLA: An uptime commitment incorporated into a signed Master Service Agreement or Order Form, making it a legally enforceable obligation with defined remedies for breaches.
Blind window: The period during which an on-call alerting tool is unavailable, causing production failures to go undetected until manual discovery or customer reports. This is the core operational risk that differentiates on-call tool uptime from other SaaS uptime.
Notification delivery period: The time window within which an on-call tool commits to delivering an alert after receiving the trigger event. PagerDuty's standard is five minutes at 99.9% delivery reliability.
Silent failure: A production incident that generates no alert to the on-call team due to alerting tool unavailability, misconfiguration, or delivery problems. Silent failures are discovered by customers or through manual monitoring rather than automated paging.
Service credit: The standard SLA breach remedy, expressed as a percentage of monthly fees applied to future invoices. Credits are capped and rarely approach the actual cost of a significant outage.
On-call rotation: The structured schedule determining which engineer carries responsibility for responding to production alerts during any given period, with rotation frequency and team size varying based on organizational structure and incident volume.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


