Break chatbot speed limits with speculative tool calls


At incident.io, one of the AI products that we’re working is a chatbot which you can use during an incident.
Chatbots should feel like colleagues, not computers
The goal of our chatbot is simple: make interacting with incident.io as natural as chatting with a colleague. No need to remember specific commands or syntax – just type what you want, and get it done.
The problem
Natural conversation requires a quick response: you won’t choose to talk to a chatbot if it takes 30 seconds to give you a simple answer!
Incident responders are not the most patient of users. When you’re under pressure to resolve an issue, or fed up and tired in the middle of the night, waiting for a chatbot is the last thing that you need.
That’s why latency in our chat bot is extremely important to us, and why we’ve gone to such efforts to optimise it.
In traditional engineering, we design systems to enable us to spend money to make these kinds of problems go away: get a bigger database, or scale up your pods. It’s not always that simple, but there’s usually some kind of money ↔ speed trade-off.
In the current LLM landscape, money simply can't buy you speed. More expensive models often have better reasoning capabilities, but similar or even worse latency profiles.
While this might change in the future (which would be excellent news for chatbots everywhere), for now, we needed to get creative.
You should try optimising your prompts first, but that will only get you so far. To make meaningful progress towards our latency goals, we needed to make more structural changes.
Our solution: speculative tool calling
By doing basic analysis of a user's message, we can make educated guesses about their intent and start preparing tool calls in parallel with the LLM's thinking. This means that when the model decides to call a tool, we've often already done the work - eliminating the back-and-forth delay that typically plagues chatbot interactions.
The result is a much snappier experience that feels like talking to a helpful colleague rather than waiting for a computer to respond.
This post shares how we structure our prompts so we can make speculative tool calls, removing the latency penalties normally incurred by LLM tool call architectures.
An introduction to tool calling
Tool calling is what enables AI assistants to do more than just generate text. When an LLM "calls a tool," it's essentially requesting an external system to perform an action or retrieve information that the model can't handle on its own.
When we send a request to an LLM, we can also specify a list of tools that are available for it to call.
When analysing a user’s request, the model might determine that to fulfil the request, it needs to call a tool. When this happens, it responds by telling us which tools needs to be called. It’s then up to us to execute that — afterwards, we incorporate the result, and call the prompt again.
This capability gives AI assistants agency: transforming them from simple chat interfaces into systems that can interact with databases, trigger workflows, or manipulate data. Rather than just saying "I would search for that information," an AI with tool calling can actually perform the search and return the results.
However, this power comes with a performance cost. Each tool call introduces a delay as the system waits for the external service to respond before continuing the conversation. This delay gets longer when a tool uses another LLM call to complete the action, we’re now waiting for 3 sequential LLM calls to respond to our user’s request.
A worked example: pausing an incident
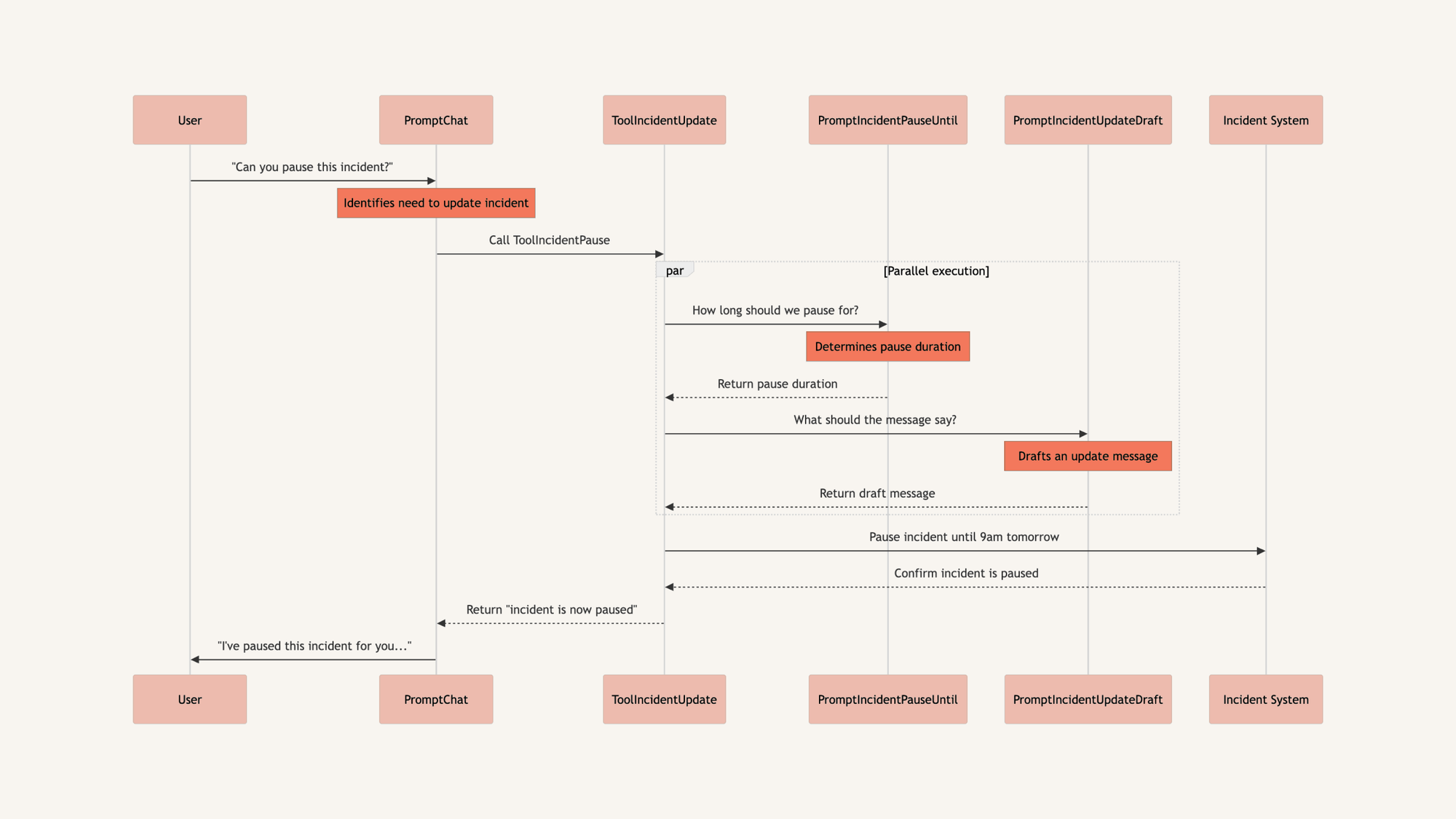
Under the hood, this is powered by a series of LLM prompts that work like a choose-your-own-adventure book. Each prompt represents a decision point where, based on the user's request, the system follows different paths to reach the right action.
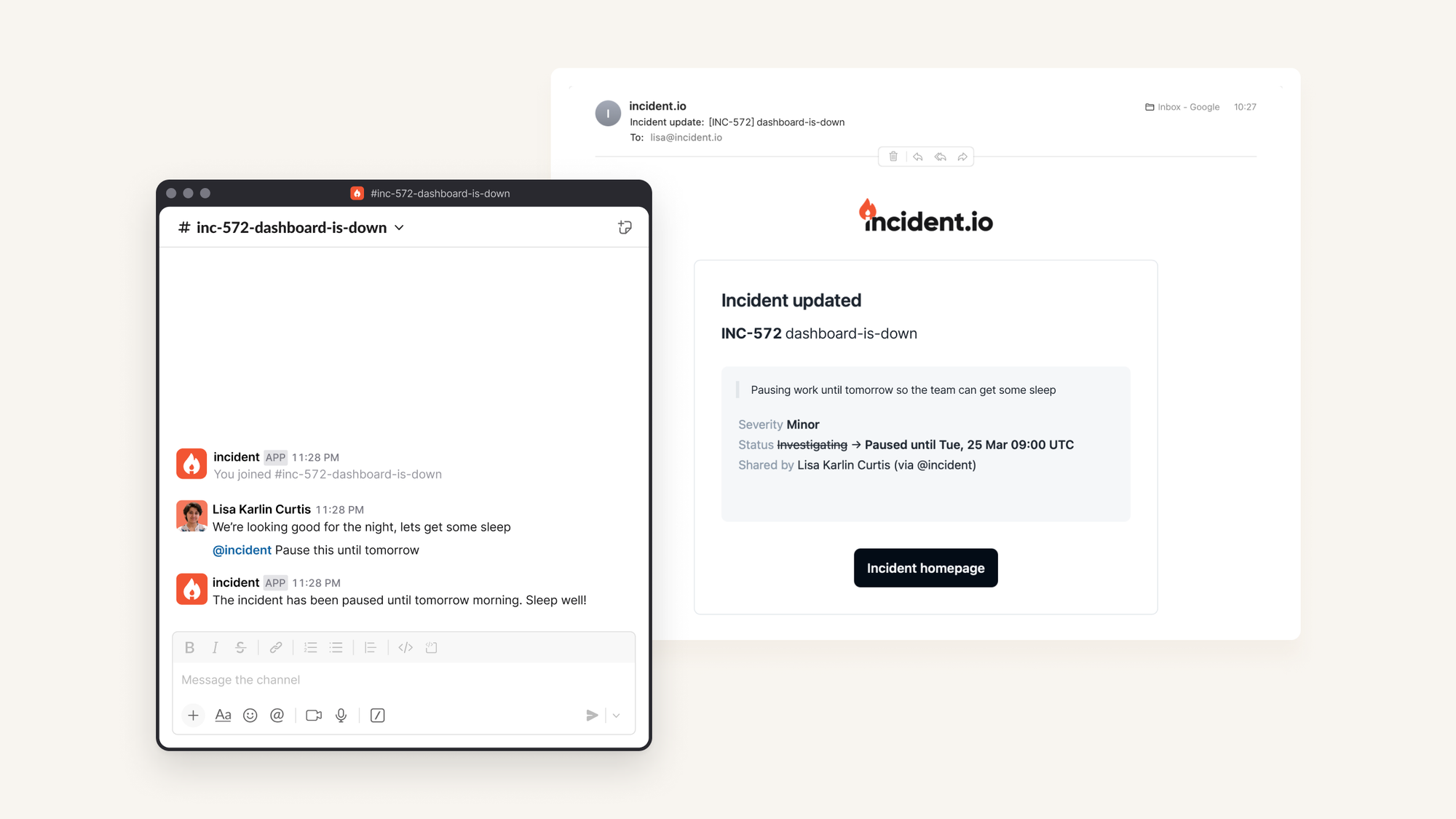
In our example, we’re asking our chatbot to pause an incident. In reality this looks like:
- Call
PromptChat, which identifies that it needs to make a change to the incident so it calls a toolToolIncidentUpdate. - That tool calls another prompt
PromptIncidentPauseUntil, which figures out how long we should pause the incident. In parallel, it also calls a promptPromptIncidentUpdateDraftwhich writes a message that should accompany the update, so that our key stakeholders understand why we’ve paused the incident (in this case, it’s so the team can get some sleep!) - Our tool now pauses the incident, using the information generated from our prompts
- We then return our response to
PromptChatto say that we’ve actioned the request: the incident is now paused PromptChatthen drafts our message back to the user (I’ve paused this incident for you…).
Or if you’re a fan of sequence diagrams, we can express it like this:
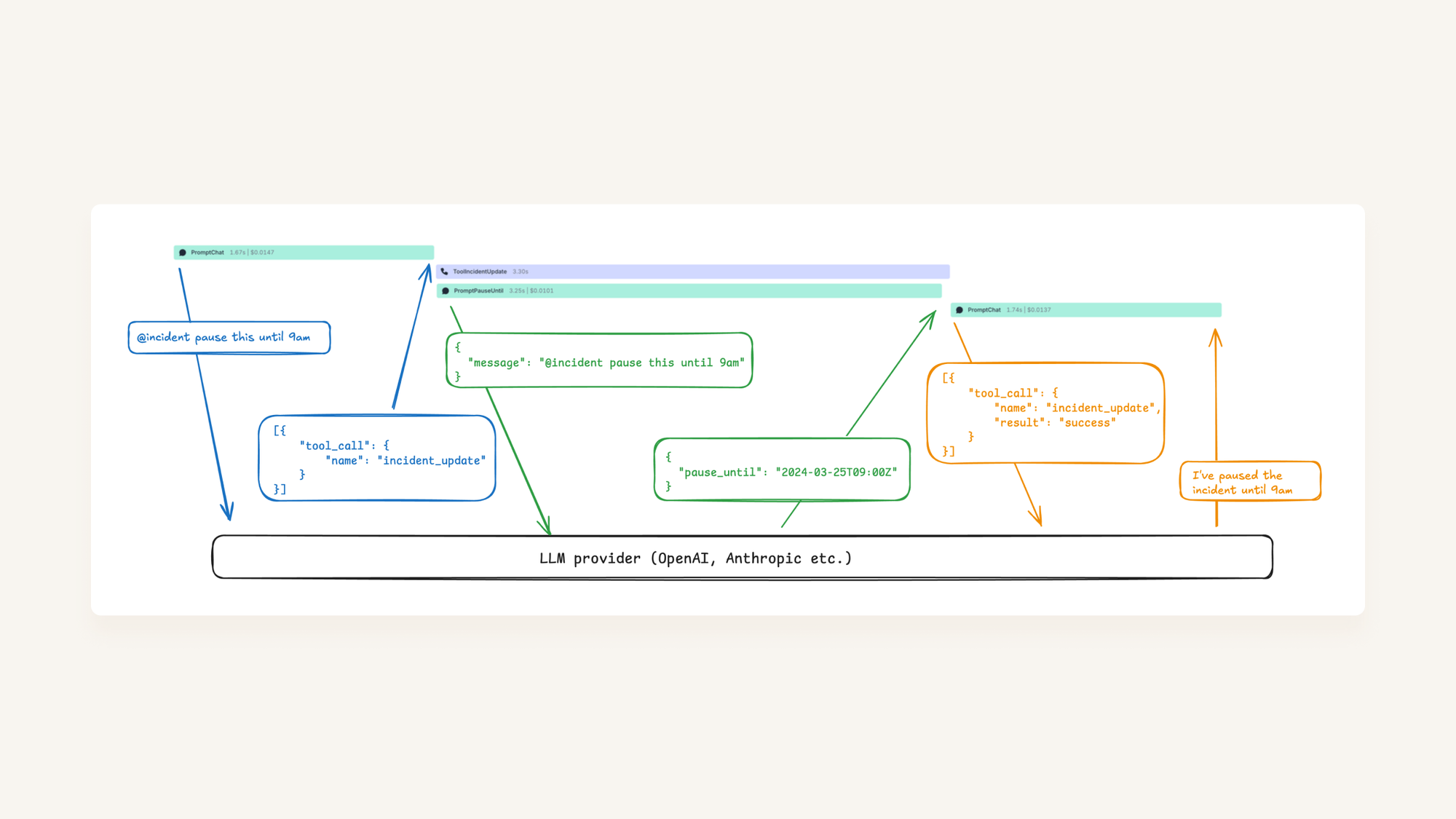
In terms of LLM calls, here’s what happens when you type @incident pause until tomorrow without any optimization:
First we call PromptChat, which responds with “please call ToolIncidentUpdate”, at which point we call it. The tool performs an update and returns us the result (e.g. “update completed”) which we then send back into PromptChat so it can decide how to respond to the user now the tool has run.
From a user’s perspective, it takes nearly 5 seconds for the incident to be paused, and a further 1.5s before the chatbot replies with the confirmation message. I can confirm from personal experience, that feels slow.
Almost all our latency is caused by the LLM calls themselves → the database work is irrelevant. At this point, we’ve already done everything we can to make those LLM calls as fast as possible. We concluded that the only way to reduce the latency was to start the LLM calls sooner.
Speculative execution in both directions
At this point you've optimised individual prompts to return as fast as possible, and tweaked database queries and everything else involved in a tool call to remove any slowness.
You can't reasonably make those pieces faster, but you can just run them earlier. In fact, you can speculatively call tools even before your initial LLM prompts tell you too, and you can assume your tools return a given response and start calling the subsequent prompts even before the tools actually finish.
Speculating both your tool calls and what they return allows you to flatten the call tree and get much faster results, provided you're careful with when and how you speculate.
Speculative calling
Imagine that as soon as the request comes in, we call ToolIncidentUpdate, just in case it’s needed. And if we decide not to use it, we can just cancel the request.
Continuing with our simple example, we can shave 1.6s off our response time:
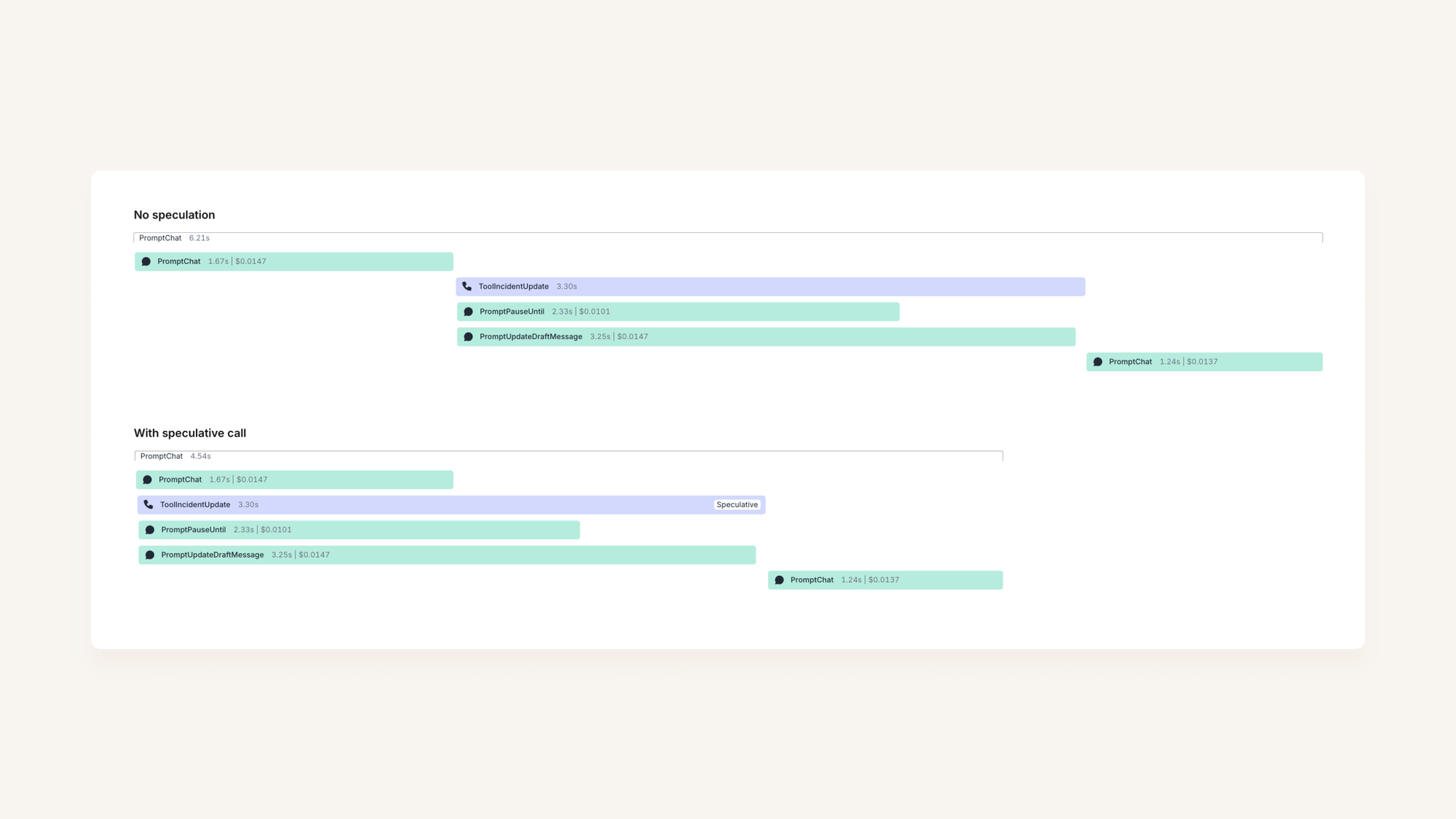
In reality, we actually have a number of different tools available to our chat bot. So if we did this for all our possible actions, we’d be spending a lot of money on prompts where we’d be throwing away the result.
When should we speculate?
For now, we’ve gone with a very simple approach: we use a list of keywords to decide when we should speculatively call a tool. That’s working really well for us: we catch almost all the cases where we do want to call the tool, and the false-positive rate is low enough that our costs aren’t a concern.
func (f ToolIncidentUpdate) Keywords() []string {
return []string{"update", "decline", "accept", "status", "pause", "unpause", "resume"}
}What happens if we get it wrong?
Imagine you have a tool that goes and fetches some more details from your database: e.g. a ‘show me the details of this code change’. If we call that speculatively, but end up not needing the result, it’s not an issue: we’ve done a bit of database work, but no problem!
However, imagine if you said @incident are you able to pause this and we actually paused the incident for you, and notified your whole team. That would be … not good.
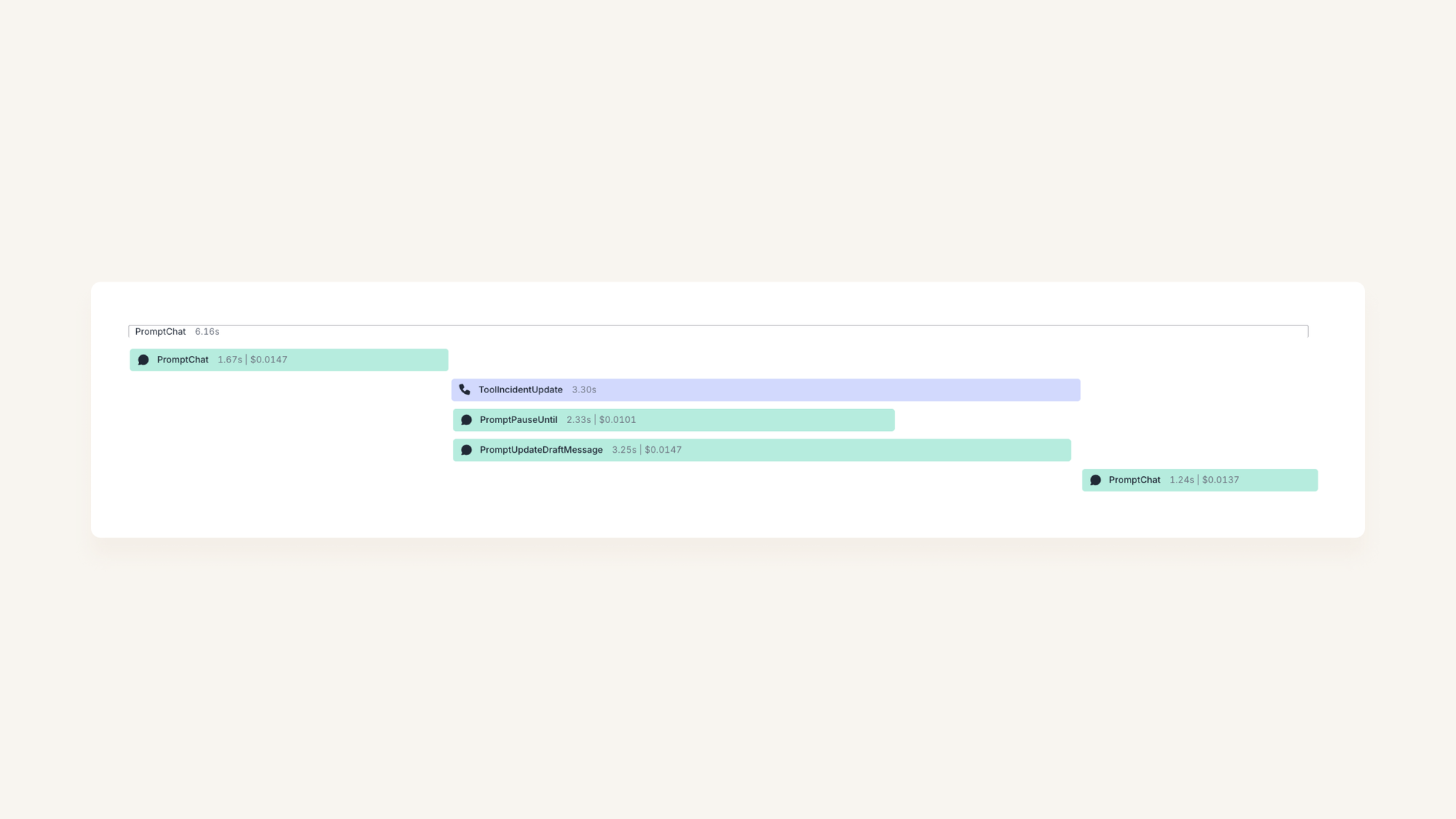
To avoid this, when we call a tool speculatively, we want to make sure we do the ‘thinking’ but not the ‘doing’. In our example above, we spend 3.25s waiting for the LLM, and 0.05s actually pausing the incident (computers are real fast).
Let’s imagine that our PromptChat call took a bit longer, so we can visualise the ‘wait’ time:
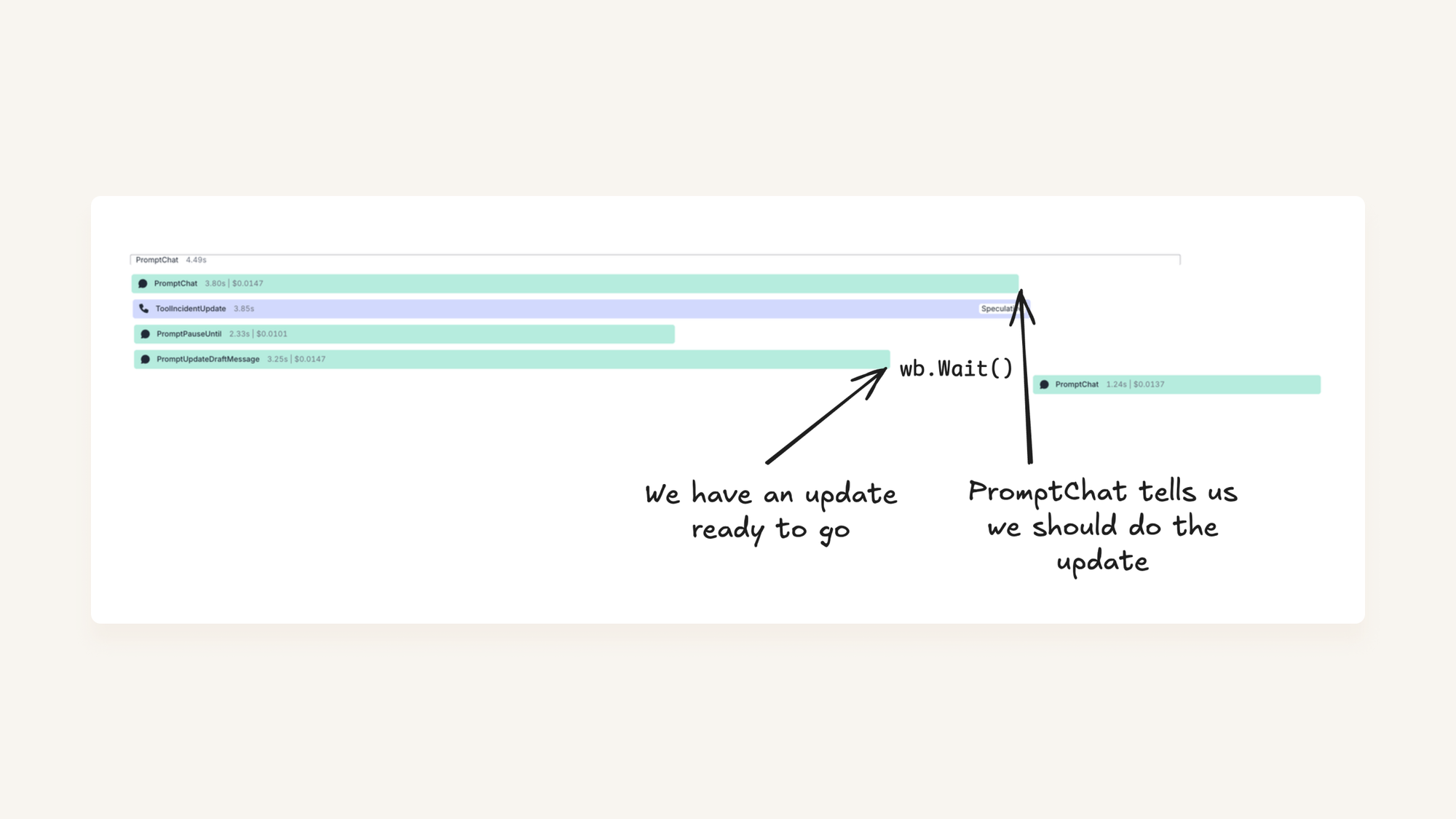
In code, we implement this as a WriteBarrier. When we call a tool call ‘speculatively’, we pass down a write barrier that blocks writes (in our case, actually updating the incident) while we figure out whether the call is genuine.
Then, if PromptChat concludes that it does want to call ToolIncidentUpdate, we unblock the barrier, and let our tool continue to run. Alternatively, if we decide not to call the tool, we can cancel our context and drop our draft update on the floor.
Our code ends up looking something like:
// Draft an update using our LLM calls
draft, err := t.draftUpdate(ctx, db, req)
if err != nil { ... }
// Wait for the write barrier to be unblocked before we actually do anything
if err := wb.Wait(ctx); err != nil { ... }
// Send the update to our system
return t.doUpdate(ctx, db, req)If you’re curious, you can see our full implementation of the write barrier here. We’re lucky to already be working in Go, which has really good primitives to help build these kinds of features (although you could definitely build something similar in other languages!)
Speculative tool responses
Looking back at our original diagram, we have shaved 1.6s off our latency to actually doing the update. But then the user has to wait for another 1.24s before we confirm that ‘we’ve paused the incident for you’.
We can take the same approach here too, by once again calling PromptChat optimistically: assuming that we have successfully updated the incident. If we aren’t successful, we can call PromptChat again later with whatever error our tool encountered.
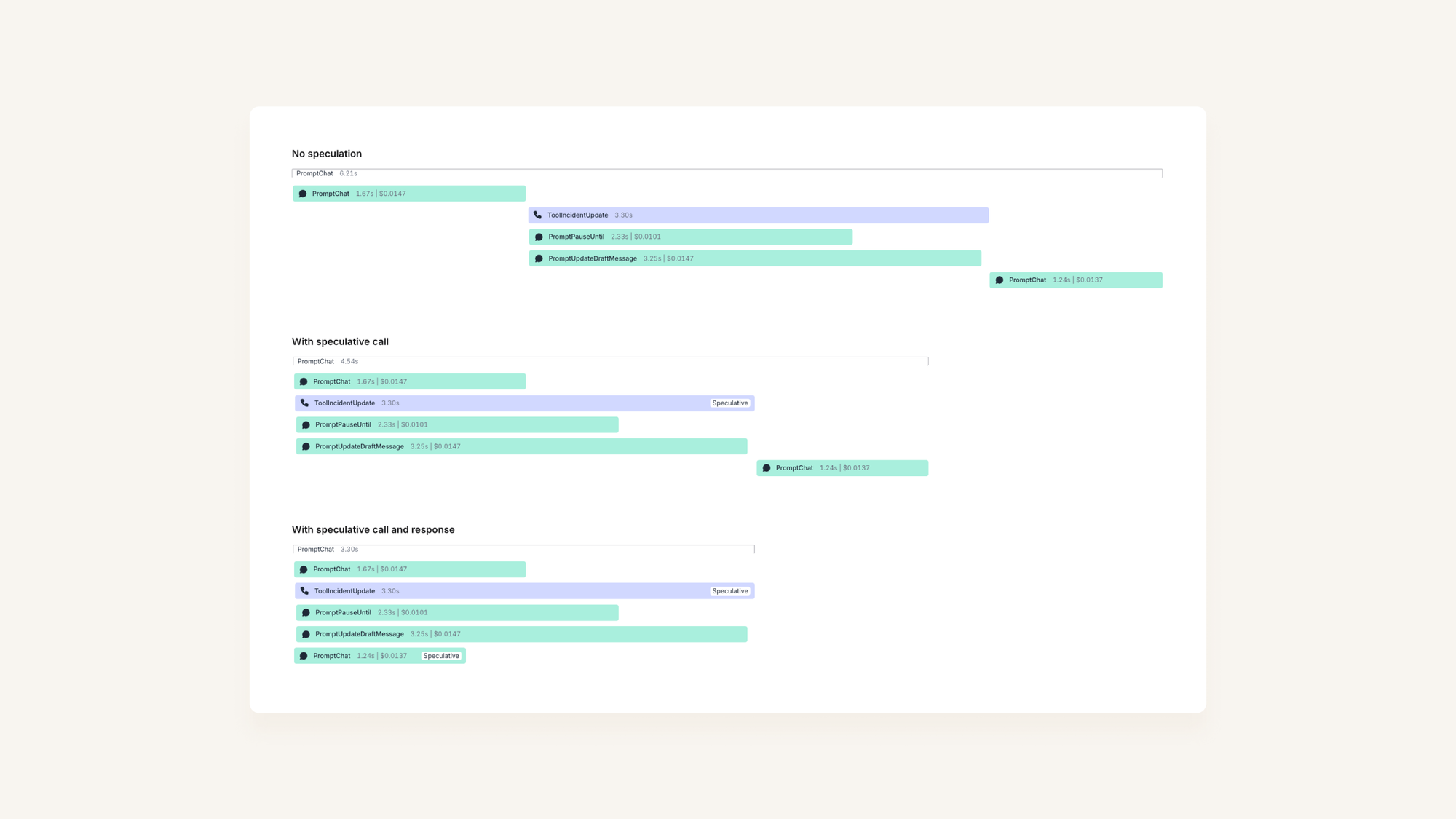
Of course, if something does go wrong, we’ll have to re-run PromptChat with whatever error was returned from our update tool. But most of the time, this will work just fine!
Interactions are now 2x as fast
In reality, our prompt-tree is a bit more complex than the one outlined above. That means we get even greater benefits from this approach, as we can make our tree deeper without paying a significant latency cost (assuming we can speculate correctly most of the time).
We’re regularly saving 2-3s on each interaction, reducing the latency for most users down by about 50%.
The trade-off is occasional wasted computation – sometimes we speculate incorrectly and have to throw away that work. But this is exactly the kind of trade-off we wanted: we can now effectively spend money for speed, which aligns with our business needs.
While the mechanism was tricky to implement, the complexity is contained in the heart of our prompt-calling code as part of a very tight abstracation. That means engineers can benefit from it with very little overhead, and we can easily apply the pattern in a wide variety of contexts.
As the model landscape evolves and user expectations continue to rise, we'll keep refining our approach. If models become significantly faster, we might even use a lightweight LLM to decide whether to speculate in the first place. Or even abandon the approach all together.
For now, we're pleased with where we've landed: this is a huge differentiator that makes our chat experience feel way better than the average AI interaction.
More articles

Weaving AI into the fabric of incident.io
How incident.io became an AI-native company — building reliable AI for reliability itself, and transforming how teams manage and resolve incidents.
 Pete Hamilton
Pete Hamilton
The timeline to fully automated incident response
AI is rapidly transforming incident response, automating manual tasks, and helping engineers tackle incidents faster and more effectively. We're building the future of incident management, starting with tools like Scribe for real-time summaries and Investigations to pinpoint root causes instantly. Here's a deep dive into our vision.
 Ed Dean
Ed Dean
Avoiding the ironies of automation
Incidents happen when the normal playbook fails—so why would we let AI run them solo? Inspired by Bainbridge’s Ironies of automation, this post unpacks how AI can go wrong in high-stakes situations, and shares the principles guiding our approach to building tools that make humans sharper, not sidelined.
 Chris Evans
Chris Evans
Join our team – we’re hiring!
Join the ambitious team helping companies move fast when they break things.
See open roles