You can’t vibe code a prompt


Software development has hit its vibe coding era. Many engineers (and plenty of non-engineers) have handed the reins over to Claude Code or Cursor Agent, letting AI handle the heavy lifting to ship faster.
Meanwhile, every product is scrambling to integrate LLMs, and half my LinkedIn feed has quietly rebranded as “Prompt Engineers.”
So, why not combine the two? Just vibe code your prompts, right?
Real-world example
At incident.io, we’re building an agent which helps you investigate and resolve your incidents.
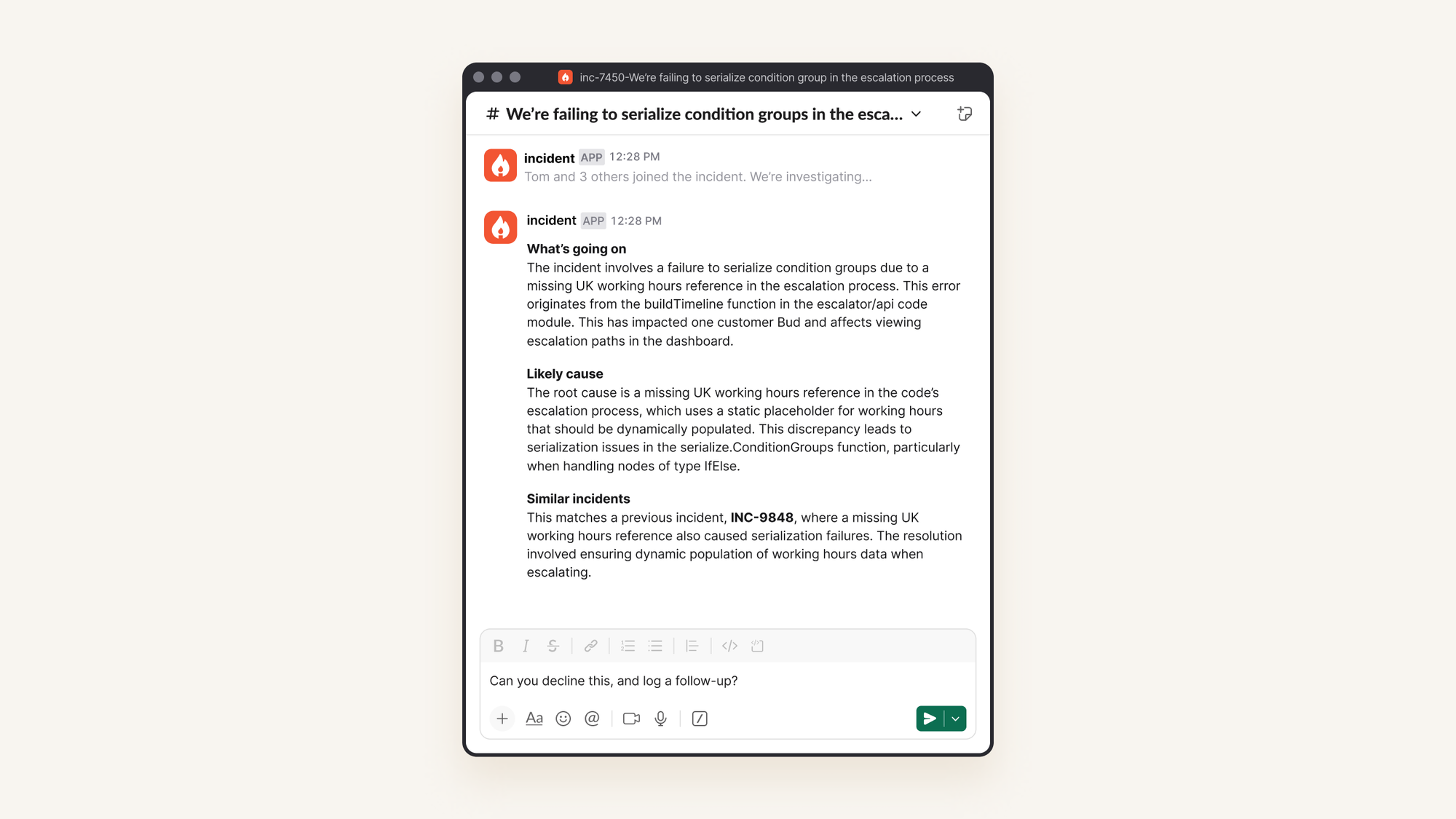
One of its jobs is to scan Slack for relevant discussions that might clue you in on what’s gone wrong. For example, if an alert comes in about database CPU being high, and someone recently posted a message in #engineering about how to handle situations like this, our agent would highlight this.
Here’s a (very simplified) example of the prompt we use for detecting relevant messages. If an LLM is certain that there’s a useful discussion, we surface it to responders.
You will be given a message that might be related to an incident.
Evaluate whether the message contains information that would be helpful for
responders to know about when investigating the incident.
Assign one of these confidence levels:
* certain: There is clear evidence that the message would help responders
resolve the incident
* potentially_related: The message might help responders resolve the incident,
but there is some ambiguity
* not_related: The message is not related to the incident at allSometimes, this works great. Take this example, where it was able to correctly map an error in production to a recent change someone in sales made to our CRM:
// Input
incident: |-
name: Unrecognised Salesforce user role 'Enterprise account manager'
message: |-
channel: sales
content:
Heads up, I just added that Enterprise account manager role to
Salesforce we've been talking about :)
time_since_sent: 5 minutes
// Output
confidence: certain
reasoning: |-
The message clearly indicates that the 'Enterprise account manager' role
has just been added to Salesforce, which directly relates to the incident
involving an unrecognized Salesforce role with the same name.
But other times, it can be painfully wrong, like here where it mis-attributed a source of 400 errors to an entirely unrelated issue from the day before:
// Input
incident: |-
name: Unable to sync users due to Slack 400s
message: |-
channel: engineering
content: |-
I've found the cause of the 400's from OpenAI! We misspelled a
parameter name in the client
time_since_sent: 24 hours
// Output
confidence: certain
reasoning: |-
The message directly addresses the cause of the 400 errors that are preventing
user synchronization in Slack, providing specific details about a misspelled
parameter name.If you were trying to debug Slack sync issues, you’d be seriously annoyed if we interrupted to say, “Hey, the issue is in the OpenAI client!”—when it definitely isn’t.
For the record, this isn’t just a 4o-mini thing. I tested 4o, and it fails in exactly the same way. So this isn’t a model problem, it’s a prompt problem.
LLM’s love to overfit
The sensible thing to do before we start tuning the prompt is to build up a set of evals which act as unit tests for the prompt—test cases along with their expected outcome. I took the examples from earlier, added a few more, and ran them three times each to get a feel for consistency. The first three pass, and the last three fail:
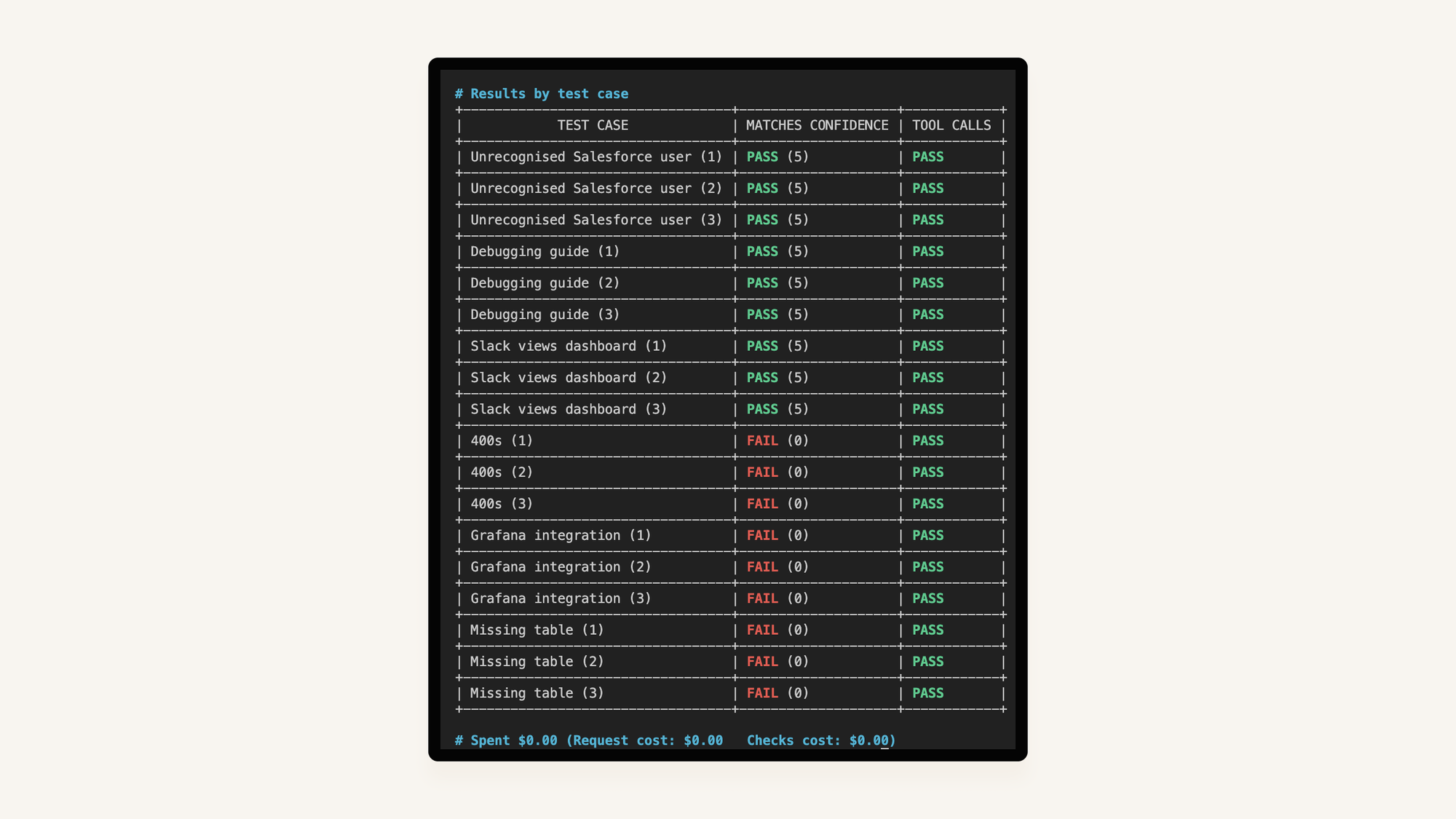
The goal is simple: get all six to pass. These aren’t edge cases—we’ve cherry-picked examples that should be trivially obvious.
Now, if you’re a vibe coder, you might be tempted to throw all the inputs and expected outputs into the context window, ask the LLM to tweak the system prompt, and let it loop until everything goes green. Maybe while you grab lunch.
To demonstrate what happens when you try and optimise prompts this way, I gave Claude the Slack 400s example and asked it to revise the prompt until it passed consistently. After a few rounds, Claude was successful by adding these instructions:
A message is not_related if:
- It discusses a different system, service, or root cause than the incident.
- Example: OpenAI errors are not related to Slack incidents unless explicitly connected.
- It refers to a broad issue (e.g., "400 errors") without explicitly linking to the incident.
- It identifies a problem in an external service without explaining how it directly causes the incident.This seems kind of reasonable at first glance but when we re-run the updated prompt across all the evals...
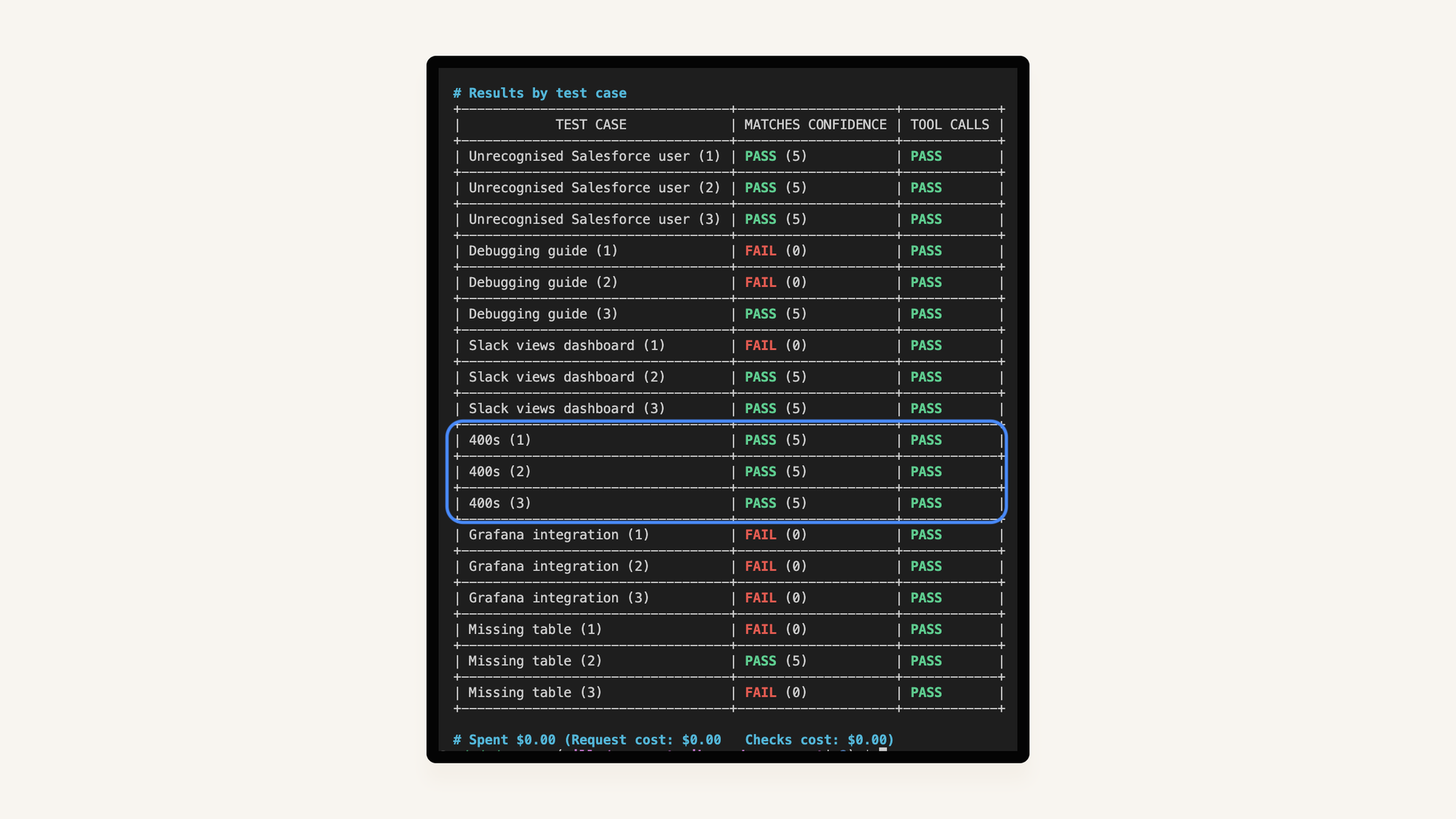
Sure, we’ve fixed the Slack 400s case. But we’ve now broken others that used to pass.
Take the Debugging guide case, where we're looking for a reference to a debugging guide. We expect this one to be labelled certain—it literally links to a guide for resolving the exact kind of issue we’re seeing:
// Input
incident: |-
name: We're seeing lock timeouts whilst delivering on-call cover requests
message: |-
channel: engineering
content: |-
I just spent an hour investigating lock timeouts in the post-mortem
generation service </3 so I've written a debugging guide for lock timeouts
in case anyone encounters a similar problem - <https://notion.so/12345>
time_since_sent: 6 months
// Output
confidence: potentially_related
reason: The message discusses lock timeouts which are relevant to the incident
being investigated. However, it refers to a different service
(post-mortem generation service) and does not explicitly connect to the
on-call cover requests issue, creating some ambiguity about its direct relevance.
But because we just told the LLM that messages affecting different systems are unrelated, it’s not sure how to handle this case because the message references a different service.
In machine learning we call this overfitting; when a model cannot generalise because it fits too closely to specific patterns in the data.
And in this case, that’s more than just annoying—it’s a real failure. Labelling this message as potentially_related instead of certain means responders don’t get shown a guide that could have saved them hours. That’s pretty embarrassing!
More examples will not save you
You might be thinking: Well, of course, tuning on just one example at a time won’t work—it’s not seeing the full picture!
So I embraced the vibes and asked Claude Code to solve this problem using the whole eval suite. It managed to get all test cases passing 100% of the time with only four iterations, but just look at the monstrosity it’s created. The prompt has ballooned to 7× its original size and you’ll notice that the Specific Examples section just regurgitates all the evals, hardcoding what to do in each case.


And here’s the kicker: if I delete the Specific Examples section and re-run the evals, we’re right back where we started—the first three cases pass, the last three fail.
If you shipped this to production, you’d be in for a bad time. The LLM wouldn’t actually understand the problem any better—it’d just be memorizing specific answers, completely lost when faced with with new and unpredictable cases— which is the entire purpose of what we’re building.
Beyond that, it can be expensive. My costs were:
- <$0.01 to run all test cases
- $0.65 on Claude Code
However, I was using mini for this prompt. If your prompt requires a more expensive model (e.g., o4 is ~16x more expensive than mini), and if you had a bunch more examples, and Claude had to do many more iterations to get all the tests to pass… then you could make a good dent on your vibe coding budget. All for terrible results!
There is no replacement for human intuition
At the end of the day, you still have to write your prompts. The best way to improve a prompt like this one? Go through historical cases and describe—like you’re explaining to a five-year-old—why certain messages are useful.
And crucially, don’t just dump your eval suite into the prompt. Instead, craft new examples that share the same shape as tricky test cases but don’t overlap directly.
For instance, to help with the 400s test case, I might add an example like this:
### Input
incident:
name: On-call rotation sync failing due to calendar API quota exhaustion
message:
channel: team-billing
content: |-
Heads up, we're hitting Stripe API quotas when syncing subscription updates.
I'm adding exponential backoff to the payment processor.
time_since_sent: 12 hours
### Expected Response
{
"importance": "not_related",
"reasoning": "Although we recently encountered API quota exhaustion, this was in a different API in an unrelated part of the system."
}
No mention of 400s, Slack, or OpenAI here—but the structure is the same. The issue is API quota exhaustion, just in a completely different system.
This way, we’re checking that the model can think, rather than spoon-feeding it answers.
How you should use an LLM to help you
It’s not that LLMs can never be useful helping you write prompts, not at all. It’s just that you need to know when and how to use them, and ceding control over the prompt to an unsupervised LLM is probably one you should avoid. Things I've found LLMs to be genuinely good at include:
(1) Creating evals
If you don’t have any historical data to lean on you, you can just ask an LLM to generate some evals for you based on the prompt. This can actually be quite a good indicator by itself; if you disagree with most of the expected outcomes in the generated test cases, your prompt is probably misleading.
If you do know what you want the LLM to catch, give it your input structure and key details—it’ll fill in realistic placeholders for the rest, saving you time.
(2) Creating examples
Got a test case that’s tricky? Ask an LLM to generate a structurally similar example without mentioning X, Y, or Z. It won’t nail it on the first try, so be ready to refine.
(3) Using LLM’s as judges
Grading outputs like confidence is easy with boolean logic. But if you need to assess text quality (e.g., in an incident summary), eyeballing every response is a pain. A cheap LLM can do that for you:
func (p PromptIncidentUpdateSummary) Evals() (
*EvalSuite[PromptIncidentUpdateSummaryInput, PromptIncidentUpdateSummaryResult], error,
) {
type (
Input = PromptIncidentUpdateSummaryInput
Result = PromptIncidentUpdateSummaryResult
)
// EvalLoad loads the eval suite for a prompt from a YAML file,
// and applies a list of checks that should be ran on each test case.
return EvalLoad(p,
EvalCheck("Grade", EvalCheckPrompt[Input, Result](`
The grade should be:
- 1 if the new summary is completely different from the expected summary
- 2 if the new summary is somewhat similar to the expected summary
- 3 if the new summary contains all the same information as the expected summary, despite any differences in wording
The test should pass if the grade is >= 3.
`)),
EvalCheck("Similar length", EvalCheckPrompt[Input, Result](`
The grade should be:
- 1 if the actual summary is longer than our expected summary
- 2 if the actual summary contains information that has been omitted from the expected summary (for example, information about the status or affected customers)
- 3 if the actual summary contains a similar level-of-detail as the expected summary
- 4 if the actual summary contains the same level-of-detail as the expected summary and doesn't include any additional information
The test should pass if our grade is >= 3.
`),
),
)
}(4) Recognising bad prompts
Prompts are just big ol’ strings, which means that we can’t rely on linters to tell us where we’ve scuffed up. This means that without manually reading a prompt top to bottom whenever you make a change, you can end up with contradictory instructions, or examples which no longer make sense.
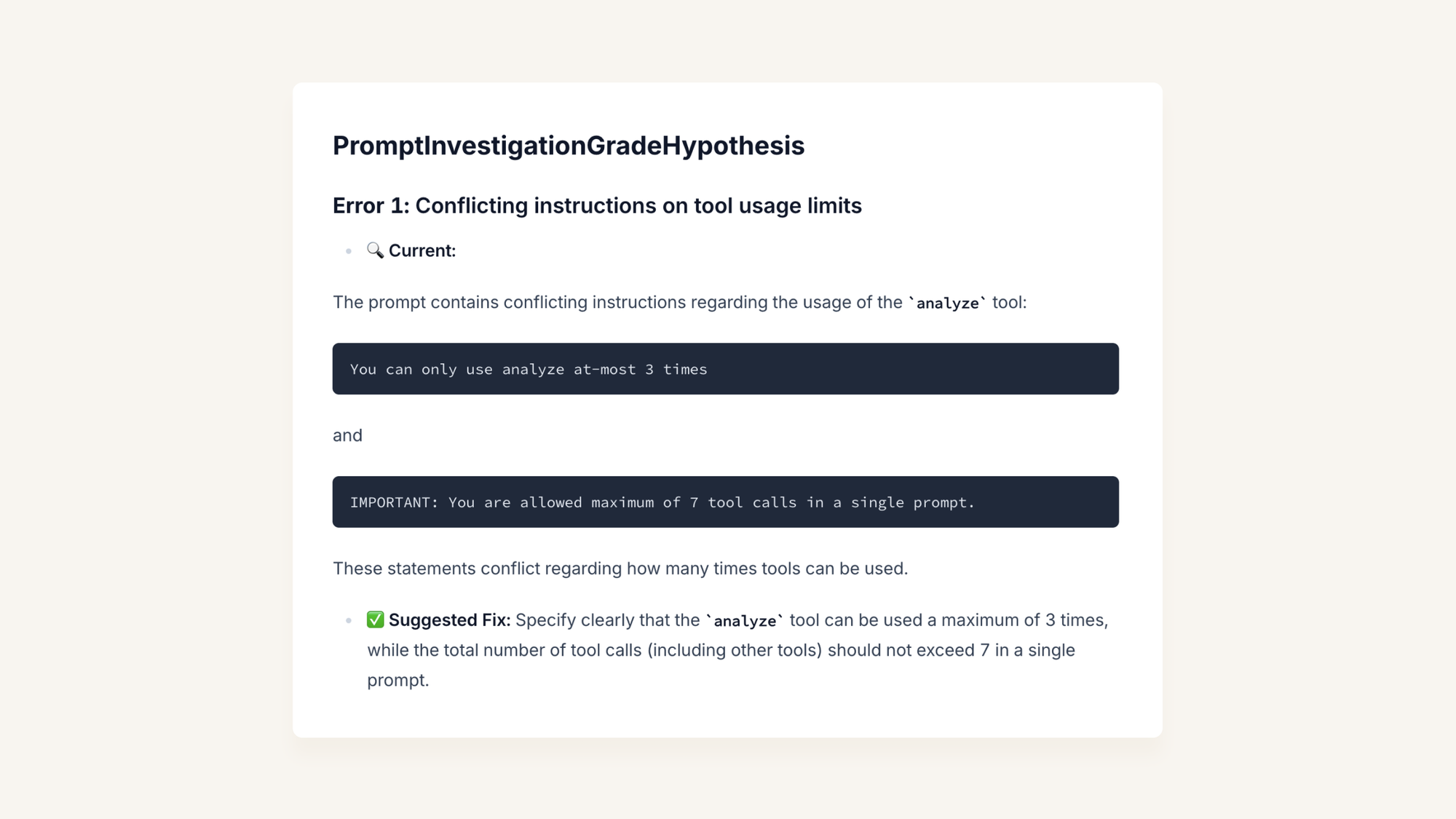
We run a health check which reports on these sort of errors.
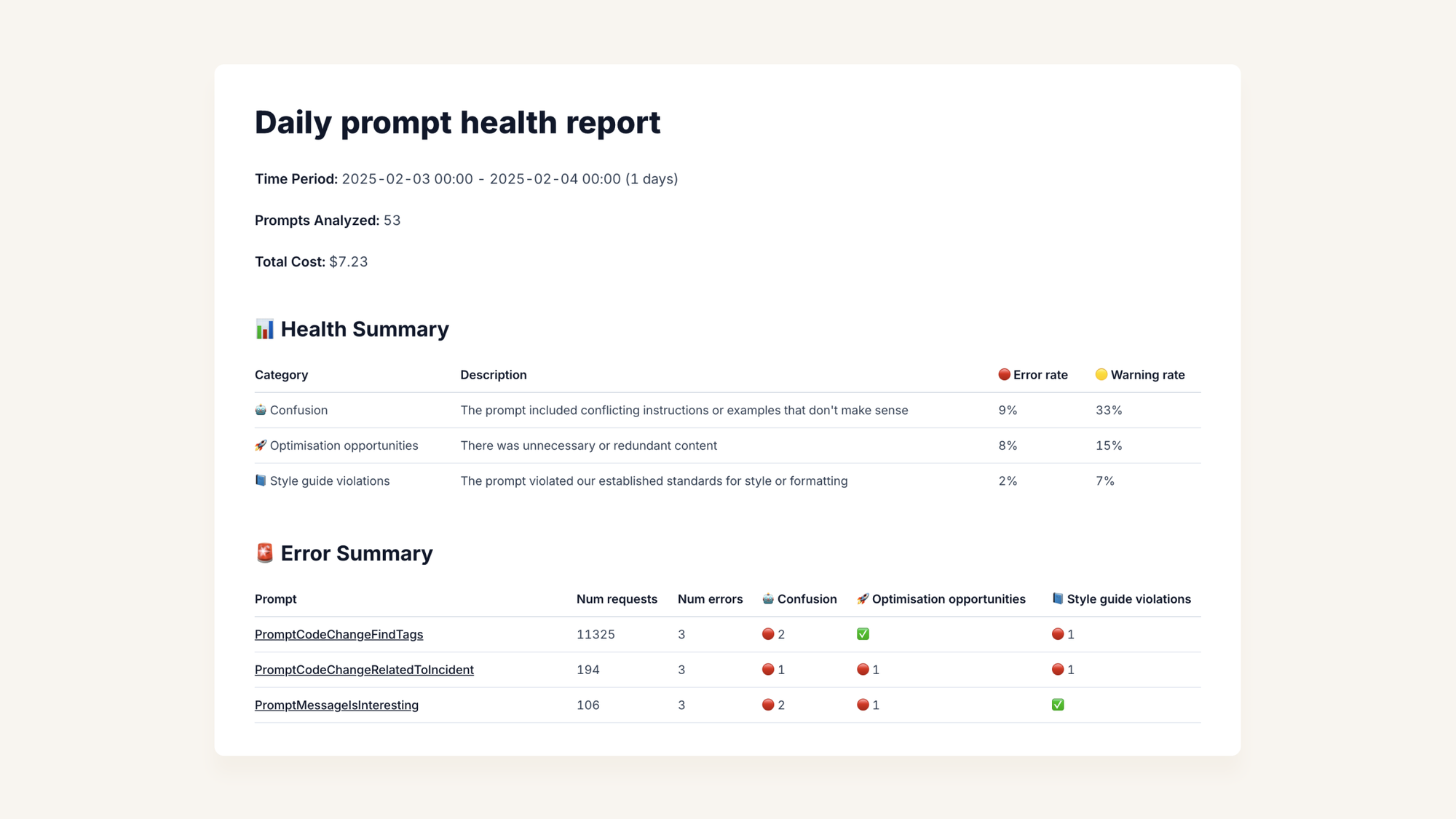
This means LLMs nit-pick our prompts so we don’t have to.
(5) Grading interactions in production
If you’re using LLMs in production, having a pulse channel to follow how things are going is a great idea.
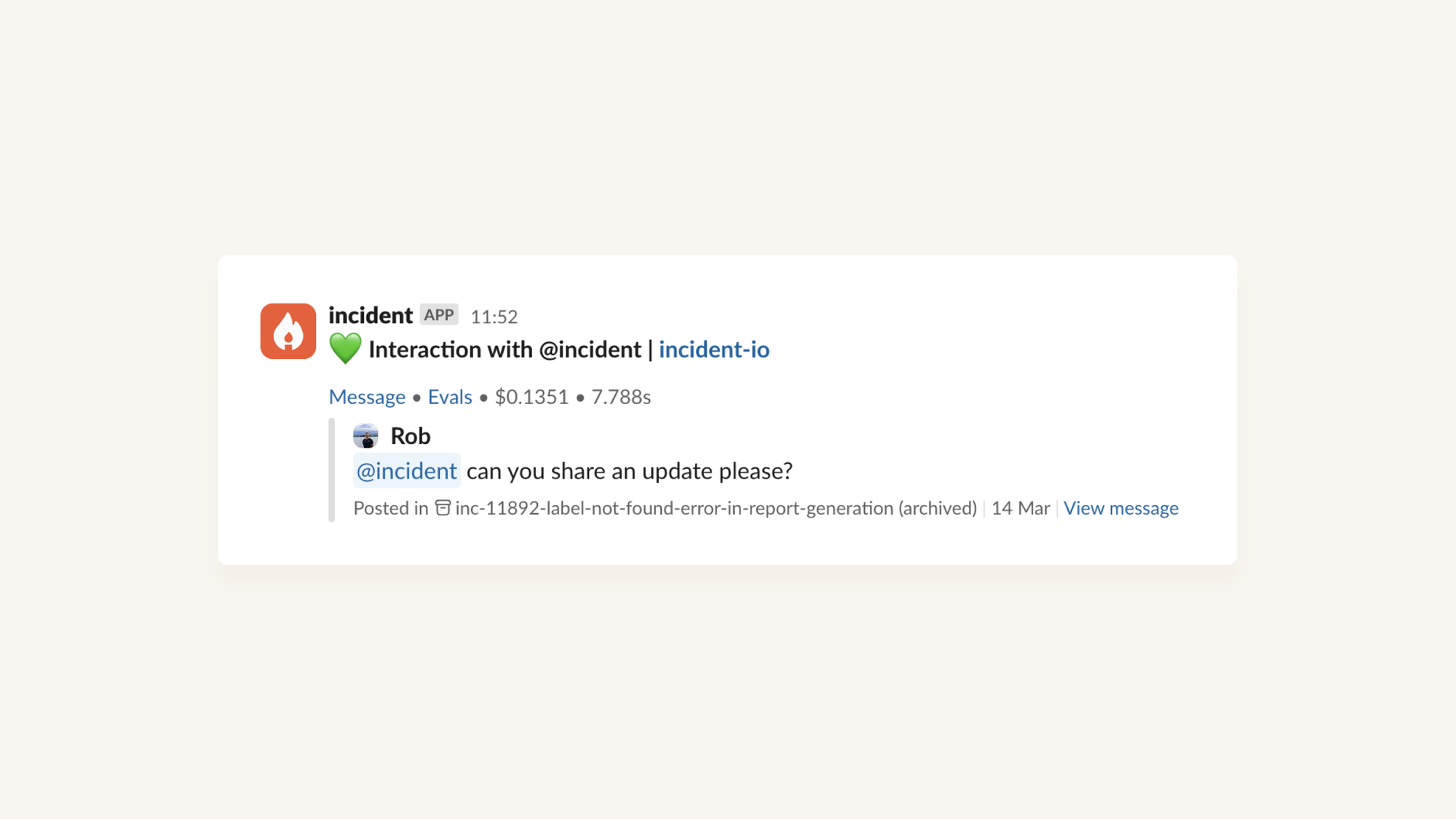
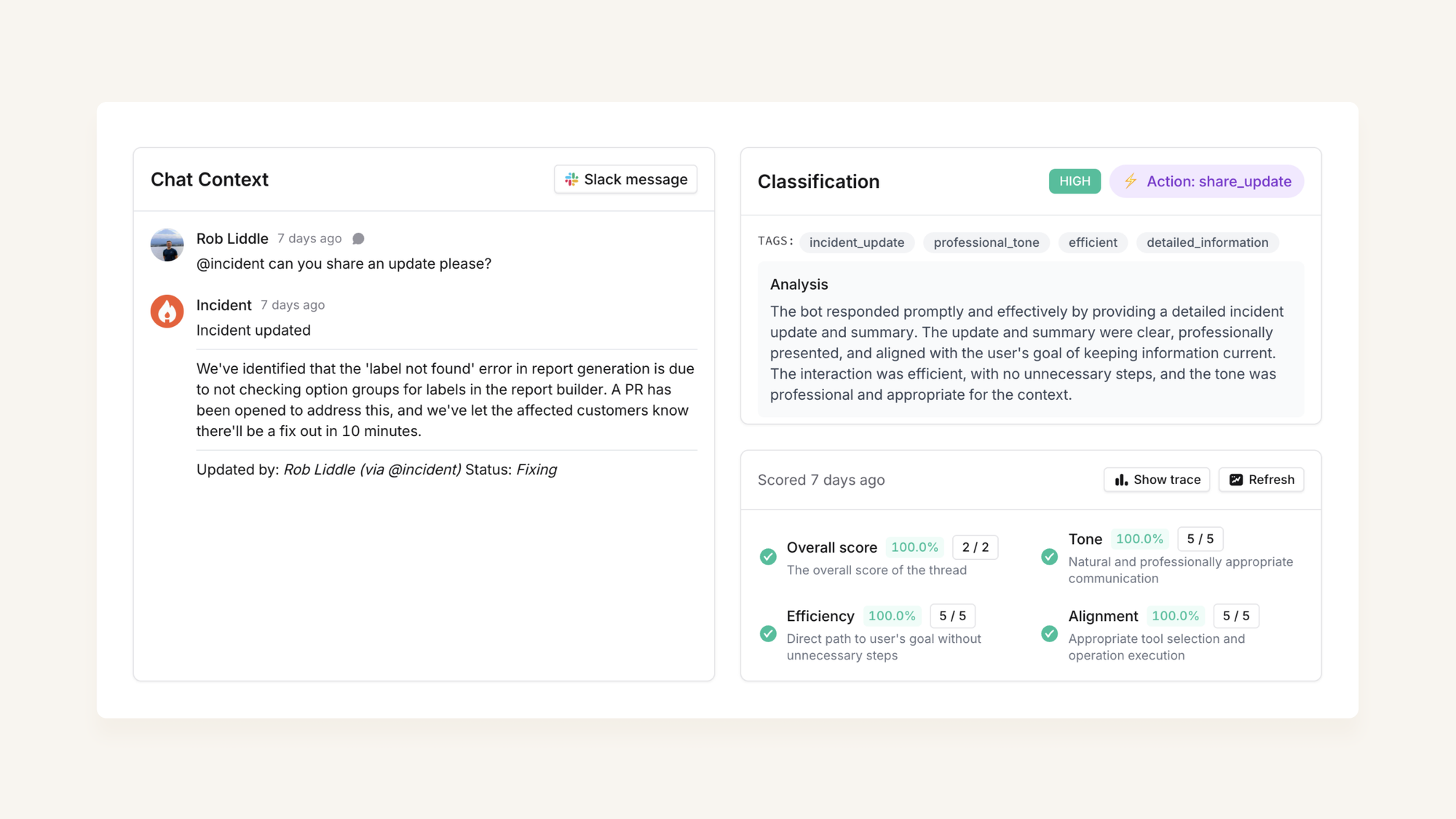
But you don’t want to be manually sifting through all the interactions and checking that each one “looked good”. Instead, we let a cheap LLM classify interactions, score them across key metrics, and assign an overall rating.
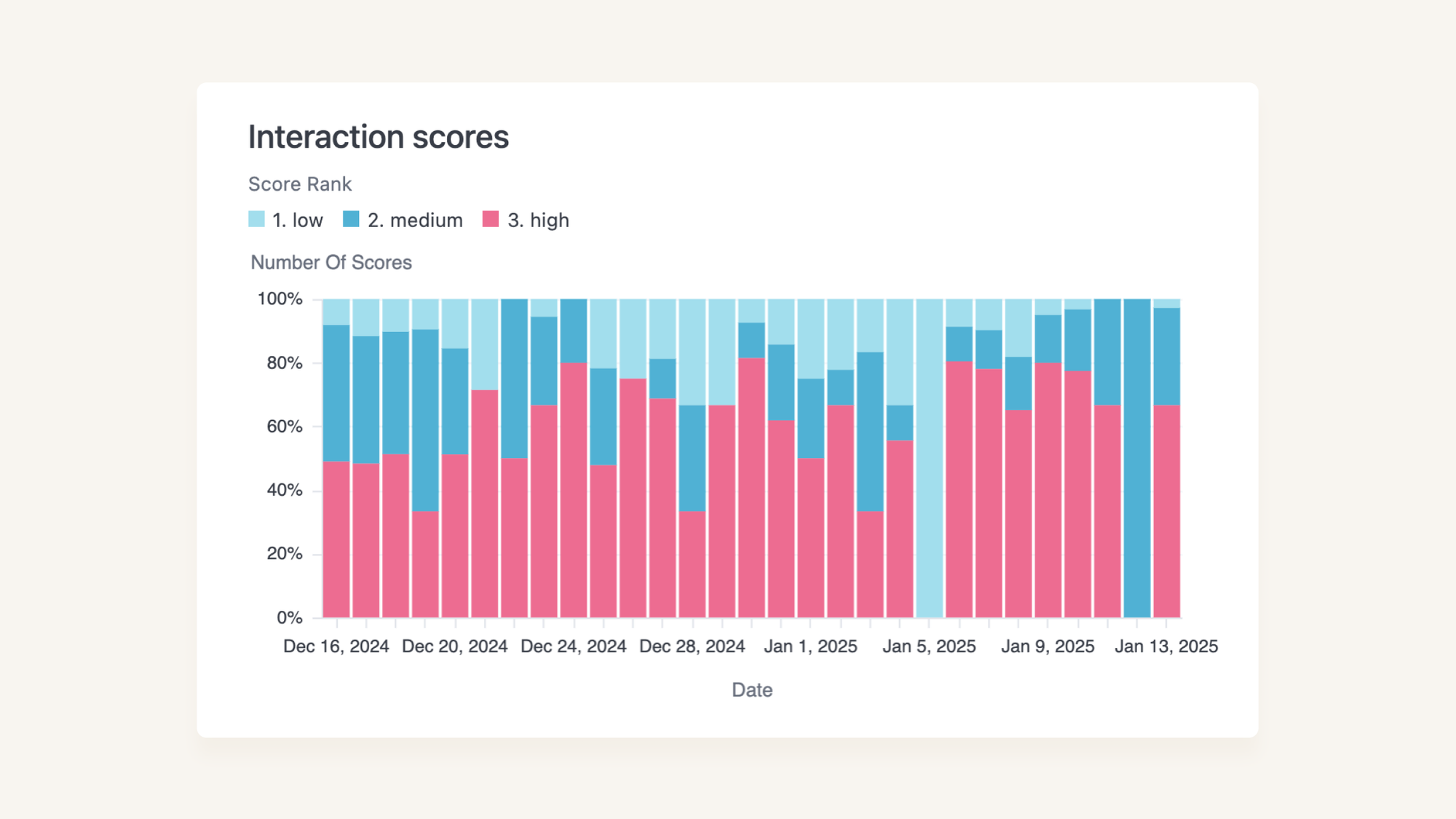
Calculating scores and interaction types also means that you can track how your performance changes over time. Not only is this helpful for our managers, it is crucial to get the “feel good” factor, especially on the dark days where no amount of prompt engineering seems to be making a difference!
Conclusion
LLMs can be powerful, but they don’t replace human intuition. The temptation to throw evals at a model and let it brute-force a solution is strong, but as we’ve seen, that approach leads to bloated prompts, brittle logic, and poor generalization.
Instead, effective prompt engineering requires thoughtful iteration: defining clear evaluation criteria, crafting representative examples, and making intentional refinements. LLMs can absolutely help with that process—but only if you stay in control.
If you’re serious about building reliable AI-powered products, vibe coding your prompts isn’t an option. Engineering them with care, however, is.
More articles

Weaving AI into the fabric of incident.io
How incident.io became an AI-native company — building reliable AI for reliability itself, and transforming how teams manage and resolve incidents.
 Pete Hamilton
Pete Hamilton
The timeline to fully automated incident response
AI is rapidly transforming incident response, automating manual tasks, and helping engineers tackle incidents faster and more effectively. We're building the future of incident management, starting with tools like Scribe for real-time summaries and Investigations to pinpoint root causes instantly. Here's a deep dive into our vision.
 Ed Dean
Ed Dean
Avoiding the ironies of automation
Incidents happen when the normal playbook fails—so why would we let AI run them solo? Inspired by Bainbridge’s Ironies of automation, this post unpacks how AI can go wrong in high-stakes situations, and shares the principles guiding our approach to building tools that make humans sharper, not sidelined.
 Chris Evans
Chris Evans
Join our team – we’re hiring!
Join the ambitious team helping companies move fast when they break things.
See open roles