Stuck in a PagerDuty contract? Here's how to switch now without paying twice
May 29, 2026 — 30 min read
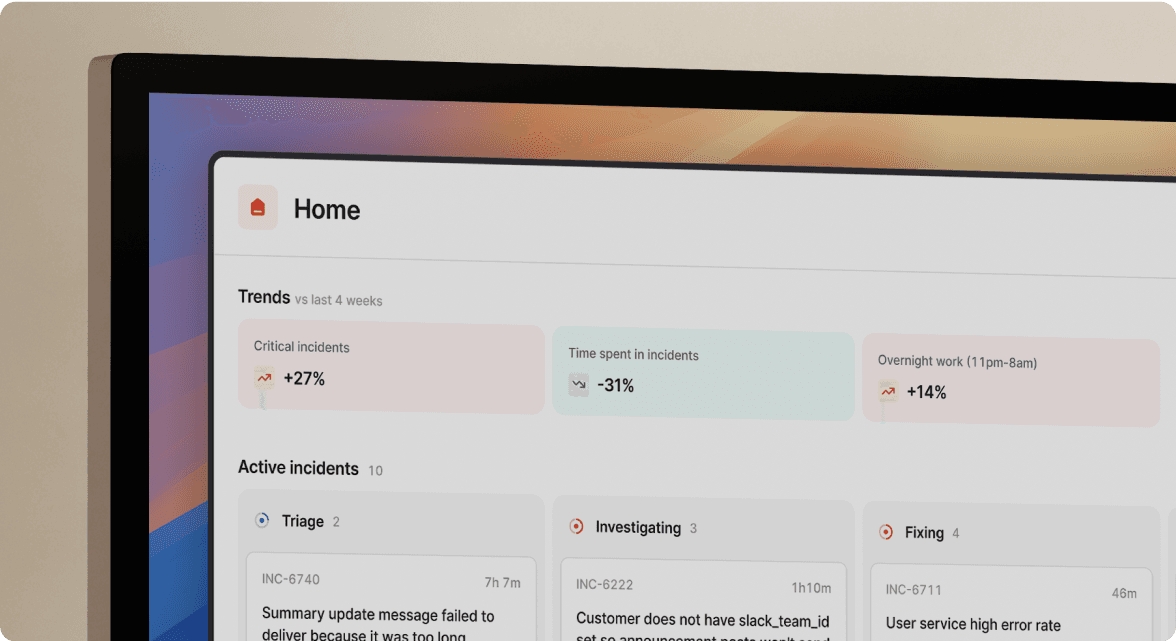
TL;DR: You can exit a PagerDuty contract mid-term without paying for two platforms. incident.io's Rescue Program covers up to 12 months of incident.io at no cost when you sign a multi-year agreement, zeroing out the dual-vendor penalty. Staying on PagerDuty costs more than switching when you factor in coordination overhead (15 minutes per incident), AIOps and Status Page add-ons, and the 99.9% vs. 99.99% uptime gap. Zendesk migrated 1,200 users and 150 teams with a core team of two engineers and projected $700,000 in first-year savings (as reported in the SEV0 SF 2025 session and Rescue Program launch announcement).
Most engineering teams stay on PagerDuty not because they want to, but because switching mid-contract means paying two vendors at once. That overlap cost, $44,280 in base platform spend alone for a typical 120-person team with nine months remaining (excluding variable add-ons such as AIOps, which is licensed per accepted event and will increase this figure depending on alert volume), keeps even frustrated CTOs locked into underperforming tools. The contract becomes a sunk-cost trap disguised as financial discipline.
The number one reason teams stay on legacy incident tools is contract math. The incident.io Rescue Program eliminates this financial objection by covering the overlap period with up to 12 months free on a multi-year deal. Here is the exact financial breakdown, the hidden costs of staying, and the step-by-step migration playbook to switch without paying twice.
Why PagerDuty contracts block your switch
You've run the incident post-mortem. The root cause isn't the database or the deploy, it's the 18 minutes your team spent assembling people, finding the right Slack channel, and toggling between PagerDuty, Datadog, Jira, and a stale Confluence doc before anyone touched the actual problem. You know the tool isn't working. But when you bring the switching conversation to Finance, the first question is always the same: "What do we do about the remaining contract?"
Why dual payments block your switch
PagerDuty sells annual and multi-year contracts, which means your team carries a fixed financial obligation regardless of whether the product is serving your needs. If you have nine months remaining on a $60,000 annual contract, switching today means writing a $45,000 check to PagerDuty while also paying your new vendor. Most CFOs will not approve that math, and most CTOs do not want to fight that battle. This financial lock-in is not about product quality, it's about contract timing, and it paralyzes switching decisions even when the engineering case for moving is clear.
Why contract overlap kills switching decisions
Vendor overlap cost is straightforward to calculate: take your remaining contract months and multiply by your monthly PagerDuty spend. For a 120-person engineering team on PagerDuty's Business plan at $41/user/month, nine months of remaining contract equals approximately $44,280 in platform spend alone. That number lands on a Finance spreadsheet as a direct hit to the quarter, and the conversation dies before migration planning starts.
Competitors are addressing the migration friction side of this problem. FireHydrant offers an open-source migration tool that generates Terraform configuration files to move resources from PagerDuty, Opsgenie, and Splunk On-Call. Rootly provides hands-on migration guidance with a team that includes former PagerDuty and Opsgenie engineers. Both approaches reduce operational migration friction. Neither eliminates the financial penalty of the remaining contract term, which is the distinction that matters when you're trying to get Finance to approve a mid-cycle platform change.
What PagerDuty's contract really costs
PagerDuty's pricing is not transparent, and the published tiers do not reflect what most teams actually pay. According to Vendr's marketplace data, PagerDuty contracts typically range from $5,000 to $70,000 annually depending on features, user count, and negotiation leverage. Renewals historically carry a 10-15% increase, meaning a $60,000 contract becomes $66,000-$69,000 at renewal without any scope change.
The bigger cost driver is add-ons. Per OnPage's PagerDuty pricing analysis, the add-ons stack up quickly:
- AIOps: $699/month ($8,388/year) perOnPage's PagerDuty pricing analysis, treat this as a floor, not a fixed cost. PagerDuty AIOps is licensed per accepted event, meaning a team processing 500,000 events/month pays more than one processing 50,000. High-alert-volume teams in particular should request a line-item AIOps quote from their PagerDuty account rep before using any third-party estimate in internal budget comparisons.
- PagerDuty Advance: $415/month ($4,980/year)
- Status Page: $89/month per 1,000 subscribers (publicly listed on PagerDuty's pricing page)
A 120-person team on PagerDuty's Business plan ($41/user/month) adding AIOps spends approximately $67,428 per year at list price before accounting for coordination overhead (base platform $59,040 + AIOps $8,388).
Status Page cost is additional and varies based on subscriber volume at $89/month per 1,000 subscribers; a team with 5,000 subscribers pays $445/month, while a team with 1,000 pays $89/month.
Yahoo Finance reporting on the Rescue Program launch noted that PagerDuty's dollar-based net retention rate has fallen below 100%, meaning existing customers spend less year over year. If you're negotiating a renewal or evaluating exit options, PagerDuty has more incentive to negotiate than their standard contract terms suggest.
PagerDuty buyout: key program elements
Contract buyout programs exist in SaaS because financial inertia, not product satisfaction, keeps most teams on legacy tools. The incident.io Rescue Program is the most direct response to this dynamic in the incident management category, and it targets the exact objection that kills switching conversations before they start.
Financial terms of your buyout
The incident.io Rescue Program offers current PagerDuty customers up to 12 months of incident.io at no cost. Here's how it works: you sign a multi-year agreement with incident.io (typically a minimum of two years, though the exact term length is confirmed during the sales conversation), and we cover the overlap period (however many months remain on your PagerDuty contract, up to 12). You pay nothing for incident.io during that period. You continue using PagerDuty for your active contract term while running incident.io in parallel, then cut over fully when the old contract expires.
This changes the switching math entirely. Instead of absorbing dual vendor costs, you absorb zero additional cost during migration. The only financial commitment is the multi-year incident.io contract that starts after your free period ends. For teams with less than 12 months remaining, the buyout covers the full remaining term.
Multi-year commitment for savings
The buyout requires signing a multi-year agreement with incident.io. This is not a penalty clause, it's how the economics work for both sides. You get the overlap period at no cost, and incident.io gets a committed customer relationship with predictable revenue.
Multi-year agreements also lock in your per-seat pricing, protecting you from annual increases. Given that PagerDuty renewals typically carry 10-15% price hikes, locking in transparent pricing on a 2-3 year agreement provides meaningful budget predictability. incident.io's Pro plan pricing of $45/user/month all-in (the $25 base plus the $20 on-call add-on) bundles all core capabilities into a single per-seat rate, unlike PagerDuty's model where AIOps, Status Page, and other features are purchased separately as add-ons on top of the base plan.
How to end your PagerDuty agreement
Understanding your actual contract options before approaching PagerDuty matters. Here is what you need to know:
Termination for cause is available if PagerDuty fails to meet its published Service Level Agreement (SLA) obligations. PagerDuty's Standard SLA targets 99.9% uptime. PagerDuty's published SLA also defines a Notification Delivery Period, measuring the time taken to deliver first responder notifications, though the specific delivery time threshold and percentage target for this metric are not publicly disclosed in their standard documentation. If they miss this threshold, customers may receive a service credit equal to 10% of fees paid for that month. Credits, not contract cancellation, are the standard remedy.
Termination without cause typically requires payment of the remaining contract balance. PagerDuty's Master Subscription Agreement follows standard SaaS terms where convenience termination triggers the full remaining obligation.
Before contacting PagerDuty, ask your account rep:
- What is our exact contract end date, remaining balance, and are there any termination for convenience provisions in our specific addendum?
- What constitutes a documented SLA breach under our agreement and what remedies apply?
These answers shape which exit path applies to your situation.
Rescue program eligibility
To qualify for the incident.io Rescue Program, you need to meet these criteria:
- Active PagerDuty contract: You must be a current PagerDuty customer with a documented remaining contract term
- Proof of contract: Provide documentation of your active agreement (contact incident.io sales to confirm acceptable documentation types)
- Multi-year commitment to incident.io: The buyout requires signing a multi-year agreement, not a monthly or annual plan
- Migration intent: The program is for teams actively transitioning, not hedging between platforms
Schedule a demo via the Rescue Program page to confirm your specific eligibility before running internal budget calculations.
Quantifying your PagerDuty switch ROI
The financial case for switching is not just about the buyout period. Even after the free window ends, staying on PagerDuty costs more than most teams realize when you account for coordination overhead, add-on fees, and the downtime differential between 99.9% and 99.99% uptime guarantees.
Scenario 1: paying for PagerDuty's remaining term
This is the default path, stay on PagerDuty and wait for the contract to expire before evaluating alternatives.
For a 120-person engineering team on PagerDuty Business ($41/user/month) with nine months remaining:
- Remaining platform spend: $41 × 120 × 9 = $44,280 (at list price)‡
- AIOps add-on (estimated):$699/month × 9 = approximately $6,291 at OnPage's cited tier starting point; actual cost varies by event volume as PagerDuty AIOps is licensed per accepted event, not at a flat monthly rate
- Coordination overhead (15 min x 20 incidents/month): accumulates across the entire period
Estimated platform spend for nine months: $44,280 (base platform only), plus Status Page costs at $89/month per 1,000 subscribers (publicly listed on PagerDuty's pricing page; multiply your subscriber tier by $89 and by 9 months for an accurate figure), plus AIOps costs which vary based on event volume, before factoring in engineer time lost to coordination overhead.
‡ Figures based on PagerDuty Business plan list price of $41/user/month. Negotiated or discounted contract rates will produce a different remaining balance. Use your actual monthly invoice amount for an accurate calculation.
Scenario 2: avoid double PagerDuty payments
With the Rescue Program, the same nine-month overlap period costs you zero dollars in incident.io fees. You sign a multi-year agreement, the nine months are covered, and you begin paying for incident.io Pro only after your PagerDuty contract expires.
- incident.io Pro during buyout period: $0
- AIOps / AI SRE equivalent: $0 (included in Pro plan)
- Status Page: $0 (included in Pro plan)
The dual-vendor penalty that Finance feared does not materialize. The question shifts from "can we afford to switch?" to "can we afford to stay?"
Hidden costs of staying: engineer time and MTTR
The uptime difference between PagerDuty's 99.9% SLA and incident.io's 99.99% guarantee is not abstract. PagerDuty's SLA allows for approximately 8.77 hours of downtime per year. incident.io's 99.99% guarantee reduces that to under 53 minutes per year. For engineering teams running revenue-critical services, that gap translates directly to customer impact and SLA breach exposure.
The more concrete cost driver is coordination overhead. incident.io customer data shows coordination tax averages 15 minutes per incident: time spent assembling the right people, finding context across tools, and getting to the actual problem. At 15 minutes per incident across 20 incidents per month, used here as an illustrative baseline; your actual figure depends on team size, service complexity, and alert volume, which is five hours of pure coordination overhead per month (15 × 20 = 300 minutes), before anyone has typed a single debugging command. If your team runs fewer or more incidents, multiply your actual monthly incident count by 15 to get your team's real coordination tax.
The incident.io AI SRE (Site Reliability Engineer assistant) addresses this directly. It runs multi-agent investigations that search GitHub pull requests, Slack messages, historical incidents, logs, metrics, and traces in parallel, and can automate up to 80% of incident response. According to incident.io's AI SRE documentation, the assistant generates findings, formulates hypotheses, and delivers actionable reports directly in the incident's Slack channel. Engineers get to the fix faster because the AI has already done the correlation work.
120 users: mid-contract cost breakdown
For a 120-person engineering team, the all-in annual Total Cost of Ownership is broadly comparable between PagerDuty and incident.io when you include the same capabilities. Based on published pricing and third-party estimates, a PagerDuty setup with on-call and AIOps comes in at roughly $67,400 per year before Status Page, which is priced at $89/month per 1,000 subscribers and varies by subscriber volume. Switching to incident.io Pro, where on-call, incident response, status pages, postmortems, and AI SRE capabilities are bundled into a single platform, brings the estimated annual cost to about $64,800. This results in a modest annual saving of around $2,600 while also consolidating multiple tools into one system.
These figures are directional because PagerDuty costs vary based on usage, alert volume, and how add-ons like AIOps are licensed. In practice, the more important difference is packaging rather than pure price, since incident.io consolidates several separate line items into a single per-user Pro plan. In some migration scenarios, programs like incident.io’s Rescue Program can also defer initial costs until existing contracts expire, increasing first-year savings potential.
In larger real-world cases such as Zendesk’s migration, projected first-year savings reached around $700,000 based on internal estimates. Schedule a demo.
Early exit: your buyout migration guide
The fear that keeps most teams from initiating a migration is not financial math but operational risk. Production incidents do not pause for platform migrations. You cannot afford a 3 AM scenario where your new tool is misconfigured and alerts fail to fire. incident.io uses a parallel-run migration approach, not a hard cutover, which means you validate the new system under real load before decommissioning the old one.
Week 1-2: setup and pilot team deployment
incident.io's opinionated defaults get a pilot team operational without a 47-step runbook. The platform imports PagerDuty schedules in bulk, at a team level, or individually, and allows you to migrate notification rules directly from PagerDuty, which is critical for teams with complex escalation paths and short migration windows.
Start with a pilot team or two teams that handle well-defined, high-frequency alert types are good candidates, as they provide enough incident volume to validate routing without exposing mission-critical systems during the parallel-run window. Configure your monitoring tools to route alerts to incident.io alongside PagerDuty. This dual-routing setup means every real alert fires in both systems, validating incident.io's routing without removing the PagerDuty safety net.
"Slack Commands - The Slack commands feel natural and approachable for team members in our workspace." - Carmen G. on G2
Month 1-3: phased rollout while PagerDuty runs
Once your pilot team has run real incidents through incident.io in parallel with PagerDuty and confirmed that alert routing, on-call paging, and Slack channel creation all behaved correctly, expand the rollout to the next tier of teams, prioritize those with documented escalation paths and predictable alert patterns before onboarding teams with irregular or high-severity incident cadences. Keep PagerDuty active but passive during this phase, alerts should be routing through incident.io as the primary path, with PagerDuty retained as a fallback rather than the system of record. Configure these integrations:
- Datadog: Connect alert policies to auto-create incident.io channels for triggered monitors. See the Datadog monitor migration guide for configuration steps.
- Jira or Linear: Connect follow-up task auto-creation so post-incident actions flow without manual entry.
- GitHub: Link pull requests to incidents so the AI SRE can correlate deploy events with alert patterns.
Run real incidents through the platform during this phase until you have confirmed consistent behavior across automated channel creation, on-call paging, and timeline capture, the goal is repeated, reliable outcomes across different incident types, not hitting a specific incident count. Validate that automated channel creation, on-call paging, and timeline capture all work reliably before you remove PagerDuty from the alert path. The on-demand migration webinar documents how teams that run this parallel approach before cutover report zero major issues during the final switch.
Migration scale: the Zendesk example (1,200 users, 150 teams)
Zendesk migrated 1,200 users, 150 teams, and 5,000 monitors to incident.io with a core team of two engineers, as documented in the SEV0 SF 2025 session (a major incident response and reliability engineering conference) and confirmed in the Rescue Program launch announcement. They reported zero major issues, and their engineers described it as one of the smoothest migrations at Zendesk.
The financial outcome: Zendesk projected $700,000 in first-year savings and over 800 hours of operational overhead cut per year, as reported at the time of migration in the SEV0 SF 2025 session. Tom Monaghan, VP Engineering at Zendesk, called it "one of the best tooling decisions we've made."
Zendesk's scale (1,200 users and 150 teams) proves that even complex migrations require minimal staffing when the tooling supports bulk imports. If a two-person team can execute that migration with zero major incidents, a 120-person team can execute it with one person and a solid four-week plan.
Intercom also migrated from both PagerDuty and Atlassian Status Page to incident.io. Their engineering team cited simplified incident coordination and faster response as the primary outcomes of centralizing onto a single Slack-native platform. Full details, including engineering team feedback and process changes, are documented in the Intercom migration case study.
Avoid on-call burnout during migration
Platform migrations can burn out on-call engineers, but incident.io reduces this risk because engineers do not have to learn a new interface. The entire incident workflow lives in Slack, where they already spend their workday.
New on-call engineers participate in their first incident using /inc commands. /inc escalate, /inc assign @sarah-sre, /inc severity high, these commands feel like sending a Slack message because that's exactly what they are. The muscle memory transfers from existing Slack usage, not from tool-specific training.
The AI SRE feature also reduces cognitive load on on-call engineers during the migration window, when processes are in flux and team confidence in the new tool is still building. When the AI surfaces a likely root cause, engineers spend less time guessing and more time fixing.
Ensuring a smooth PagerDuty cutover
After two to four weeks of parallel running with validated alert routing, execute the final cutover in this sequence:
- Switch monitoring integrations to send alerts exclusively to incident.io. Remove PagerDuty from the alert path in Datadog, Prometheus, or your primary monitoring tool.
- Keep PagerDuty accessible for a safety period as your team builds confidence. The length depends on your risk tolerance and incident volume.
- Validate and deprecate. Run the first post-cutover incidents with the migration team on standby. Once you have confirmed that incident creation, on-call paging, and timeline capture are all operating correctly without PagerDuty in the alert path, export any historical incident data you need for compliance and regulatory retention purposes before closing the PagerDuty account at contract expiry, do not close the account until data export is complete.
incident.io's detailed migration documentation covers the complete technical sequence, including API-based user list exports, schedule import tooling, and integration configuration steps.
How to begin your PagerDuty transition
Starting the Rescue Program requires documentation of your active PagerDuty contract, clarity on your total user count, and a conversation with incident.io's sales team to map the buyout window to your specific contract terms.
Required: proof of active PagerDuty contract
To trigger the buyout program, provide documentation of your active PagerDuty agreement and its remaining term.
Acceptable documentation: Start by pulling your most recent PagerDuty invoice, your renewal confirmation email, or a contract summary showing your plan, user count, and renewal date, these are the formats most commonly used to verify active SaaS contracts. Bring whichever you have to your first call with incident.io sales, who will confirm whether it satisfies the Rescue Program's requirements. The remaining term determines how many months of incident.io you receive at no cost, up to the 12-month maximum.
Pull this documentation before your first conversation with incident.io's sales team so you can confirm eligibility in the initial call rather than a follow-up.
Cost of multi-year commitments
incident.io Pro costs $45/user/month all-in for the full platform. Here's the breakdown:
- Incident response: $25/user/month
- On-call add-on: $20/user/month
- Total Pro with on-call: $45/user/month
For a 120-person team, that is $5,400/month or $64,800/year. This includes on-call scheduling, incident response coordination, status page updates, AI-powered post-mortem generation, and unlimited workflows. There are no AIOps add-ons to purchase separately, no Status Page fees on top, and no per-incident charges.
PagerDuty contract buyout steps
Here is the exact sequence to initiate your switch:
- Gather your contract documentation. Pull your most recent PagerDuty invoice or contract summary showing your current plan, user count, and renewal date. Calculate your remaining months.
- Schedule a demo with incident.io. Go to the Rescue Program page and book a demo with the sales team. Come prepared with your PagerDuty contract details, current user count, and your target go-live timeline.
- Review and sign the multi-year agreement. incident.io's team maps your remaining PagerDuty term to the free period in your incident.io agreement. You will see the buyout structure reflected directly in the contract: X months at no cost, paid term starting at your PagerDuty expiry.
- Begin the parallel-run migration. Once the agreement is signed, your Customer Success Manager runs a kickoff session and gets your pilot team operational. PagerDuty continues running while incident.io is validated under real load.
- Cut over and decommission. After parallel validation, switch your monitoring integrations to incident.io exclusively and deprecate PagerDuty at contract expiry.
Migration checklist: rescue program readiness
Before contacting incident.io sales, confirm you have the following:
- PagerDuty contract end date confirmed
- Remaining monthly balance calculated (months remaining x monthly spend)
- Current user count and team structure documented
- Monitoring tool admin access confirmed (Datadog, Prometheus, New Relic)
- PagerDuty schedule export initiated via API or admin portal
- Two-person migration team identified (one technical lead, one coordination lead)
- Pilot teams selected (choose teams with consistent alert volume and well-documented escalation paths)
- Slack admin permissions confirmed for incident.io workspace installation
- Finance briefed on Rescue Program mechanics (zero cost during buyout window)
Schedule a demo with incident.io and see the Rescue Program mechanics for yourself. Bring your PagerDuty contract details to confirm your buyout window in the first conversation.
Key terms glossary
Contract buyout: A financial arrangement where a new vendor covers the remaining cost or duration of your existing vendor contract, eliminating the dual-payment penalty for mid-term switching.
Vendor overlap cost: The amount you pay for two competing tools simultaneously during a migration period. Calculated as remaining contract months multiplied by monthly spend on the departing platform.
MTTR (Mean Time To Resolution): The average time from when an incident is declared to when it is resolved and services are restored. Reducing MTTR is the primary operational metric for incident management platforms.
SLA (Service Level Agreement): A contractual commitment from a vendor specifying the minimum performance standard they guarantee, most commonly expressed as an uptime percentage. PagerDuty's Standard SLA targets 99.9% uptime (approximately 8.77 hours of permitted downtime per year); incident.io's guarantee targets 99.99% uptime (approximately 53 minutes of permitted downtime per year). Failure to meet SLA thresholds typically entitles customers to service credits rather than contract termination rights.
AI SRE (Site Reliability Engineer assistant): An AI-powered assistant built into incident.io that runs automated, multi-agent investigations at the moment of incident creation. It searches GitHub pull requests, Slack messages, historical incidents, logs, metrics, and traces in parallel to surface a likely root cause, reducing the cognitive load on on-call engineers and able to automate up to 80% of incident response.
Slack-native: An architecture where the entire incident workflow (declaration, escalation, coordination, and resolution) happens inside Slack via slash commands rather than through a web interface that sends notifications to Slack. incident.io is built Slack-native from the ground up, not Slack-integrated as an afterthought.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


