Slack-native Opsgenie alternative: Migration plan for engineering teams
November 24, 2025 — 15 min read
Updated November 24, 2025
TL;DR: Atlassian's Opsgenie shutdown forces engineering teams to migrate by April 2027, but you can upgrade rather than just replace. incident.io offers a Slack-native platform that combines on-call alerting with full incident response for $45 per user per month (Pro plan with on-call, which includes AI automation and Microsoft Teams support). For smaller budgets, the Team plan starts at $31 per user per month. You can migrate core functionality quickly using automated import tools, skip PagerDuty's hidden add-ons, and reduce MTTR by managing incidents where your team already works. Setup is self-serve, operational in days, and requires zero training because it lives inside Slack.
Atlassian announced that Opsgenie will shut down by April 5, 2027, with no new customers accepted after June 4, 2025. You manage a growing engineering team and face three choices: migrate to an enterprise platform you don't need, settle for Jira Service Management's ticket-based workflow, or find a modern alternative built for your team size.
This guide shows you the third path. We'll compare setup times, total costs, and feature requirements for incident.io versus PagerDuty so you can make a confident decision before the deadline.
Why the Opsgenie sunset creates opportunity
Opsgenie excels at getting the right person paged, but coordination happens elsewhere. Your team likely follows this pattern:
- Alert fires: Opsgenie wakes the on-call engineer at 2:47 AM
- Manual coordination: Engineer creates
#incident-api-downin Slack and @ mentions teammates - Tool sprawl: Opens Datadog, GitHub, and Confluence in separate tabs
- Status updates: Coordinates fix in Slack while separately updating Jira and status page
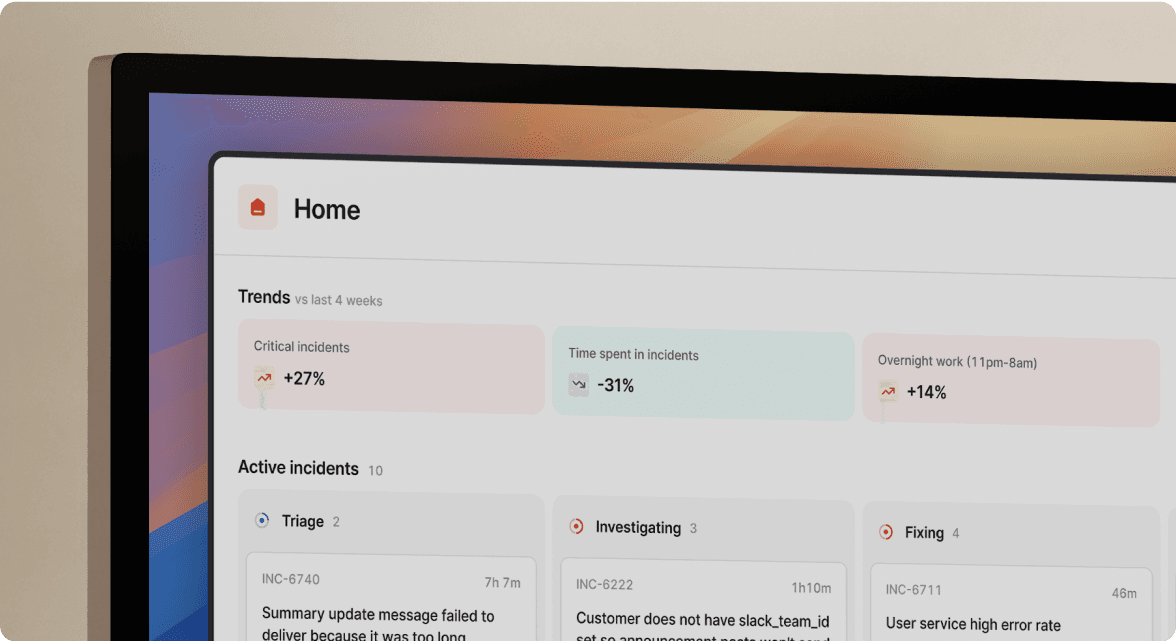
Coordination overhead eats 12-15 minutes per incident before troubleshooting starts. Modern incident management platforms eliminate this tax by managing the full lifecycle in one place.
Why the easy paths won't work
Atlassian pushes you toward Jira Service Management or Compass. JSM is built for IT service desk workflows: forms, ticket queues, and web-first interfaces. When production is down, your team doesn't want to fill out a form.
PagerDuty is designed for enterprises. The complexity shows in pricing that hides essential features behind expensive add-ons, and in the interface, which requires extensive training. For a small team, this overhead delays time-to-value by weeks.
The quick migration plan: from Opsgenie to incident.io
Migrating to incident.io takes hours or days, not weeks. Here's the process that gets you operational before your next incident.
Step 1: automated import
incident.io's automated importer pulls your Opsgenie configuration in minutes:
- User accounts with contact information
- On-call schedules and rotation patterns (including overrides)
The importer maps Opsgenie fields automatically. You review, confirm, and your schedules are live. No CSV exports, no manual data entry, no typos in phone numbers.
Note: Escalation policies need to be manually recreated in incident.io, but the intuitive interface makes this a quick process during setup.
Step 2: connect your monitoring stack
Your existing monitoring tools already know when something breaks. incident.io integrates natively with Datadog, Prometheus, New Relic, and other observability platforms through webhooks.
The setup takes 30 minutes:
- Generate webhook URL in incident.io for each monitoring tool
- Configure alert routing based on severity, service, or team
- Map alert fields to incident.io's incident declaration
- Test with a sample alert to verify the flow
When Datadog fires an alert, incident.io automatically creates a dedicated Slack channel, pulls in the on-call engineer, and starts capturing a timeline.
Step 3: the parallel run strategy
Run both systems for one day to build confidence:
- Safety net: Keep Opsgenie alerts active as backup
- Primary workflow: Let incident.io handle coordination in Slack
- Validation: Compare response times between old and new workflows
During this parallel period, alerts fire to both platforms. Your team responds using incident.io's Slack-native workflow while Opsgenie sits in the background. After 24 hours and 3-5 incidents, you'll see the difference.
"The onboarding experience was outstanding — we have a small engineering team (~15 people) and the integration with our existing tools (Linear, Google, New Relic, Notion) was seamless and fast less than 20 days to rollout." - Bruno D. on G2
Step 4: deprecate Opsgenie
Once you're confident, turn off Opsgenie alert forwarding. Update your runbooks, notify stakeholders, and cancel the subscription. Total migration time: under one week of calendar time, under 8 hours of actual work.
Comparison: incident.io vs. PagerDuty for engineering teams
Both platforms compete for growing engineering teams. Here's how they stack up on what matters: speed of setup, total cost, and essential features.
Total cost of ownership for 20 and 100-engineer teams
Cost isn't just the advertised price. It's the all-in expense including essential features like on-call management, alert routing, and post-incident analysis.
| Platform | Base Price | Essential Add-ons | 20 Users Monthly | 20 Users Annual | 100 Users Monthly | 100 Users Annual |
|---|---|---|---|---|---|---|
| incident.io Pro | $25/user | On-call: $20/user | $900 | $10,800 | $4,500 | $54,000 |
| PagerDuty Business | $41/user | Multiple add-ons required | $1,400+ | $16,800+ | $7,000+ | $84,000+ |
Note: incident.io Team plan available at $25/user/month all-in on annual billing for teams not requiring AI automation or Microsoft Teams support.
PagerDuty's pricing model fragments essential capabilities across add-ons. Alert grouping, runbook automation, and AI features all require separate purchases beyond the base Business plan. The advertised $41 per user per month becomes $60-80+ per user once you add features you actually need.
incident.io's Pro plan with on-call costs $45 per user per month, all-in. No surprise add-ons, no implementation fees, no professional services requirement.
Setup time and onboarding requirements
| Platform | Setup Time | Onboarding Model | Training Required |
|---|---|---|---|
| incident.io | 1-2 days | Self-serve | None (Slack-native) |
| PagerDuty | 1-2 weeks | Self-serve with optional sales assistance | Moderate (complex UI) |
incident.io's self-serve model means you can start a trial, connect Slack, import your Opsgenie data, and run your first incident without talking to sales. However for growing teams we strongly recommend scheduling a demo.
PagerDuty's interface requires time to learn, especially for features like alert routing rules and escalation policies. For a small team, this overhead delays time-to-value.
Feature necessity matrix: must-have vs. nice-to-have
Not all features matter equally for engineering teams. Here's what's essential versus what's bloat.
Must-have features:
- On-call scheduling with flexible rotations and overrides
- Alert routing based on service, severity, and team
- Slack-native coordination without context switching
- Status pages for public and private incident communication
- Post-incident analysis with timeline capture
- Integrations: Datadog, Prometheus, Jira, GitHub, Confluence
Nice-to-have features:
- SAML/SCIM for SSO (most small teams use Google/Okta basic)
- Advanced analytics dashboards with custom visualizations
- Multi-region failover for status pages
- Granular role-based access control beyond team/admin
incident.io delivers all must-haves in both Team and Pro plans.
Why Slack-native architecture reduces MTTR
Every incident management platform has a Slack integration. The question is: where does the actual work happen?
Web-first with Slack notifications vs. Slack-native workflows
Traditional platforms like PagerDuty are web-first. You receive a Slack notification that says "P1 incident detected, click here to view." You click, open the web UI, review the incident, assign an owner, update severity, then return to Slack to coordinate. Each context switch costs 2-3 minutes of cognitive overhead.
incident.io is Slack-native by design. The entire incident lifecycle happens in Slack using slash commands:
/inc declareto start an incident/inc severity highto escalate/inc assign @sarahto assign incident lead/inc escalate platform-teamto pull in additional responders/inc resolveto close the incident
"We've been using Incident.io for some time now, and it's been a game-changer for our incident management processes. The tool is intuitive, well-designed, and has made our Major Incident workflow much smoother. With seamless integrations into Slack, Jira, and Confluence, it has become our go-to for bringing teams together to tackle incidents faster and more efficiently." - Pratik A. on G2
Real workflow example: alert to resolution
Here's what happens when a Datadog alert fires for API latency spikes:
2:47 AM - Alert fires: Datadog detects API response time over 5 seconds.
2:48 AM - Auto-response: incident.io creates #inc-2847-api-latency-spike, pages Sarah via SMS, pulls in API service owner based on Service Catalog ownership.
2:49 AM - Investigation starts: Sarah joins, types /inc status investigating, sees alert context, recent deployments, and runbook links already posted.
2:52 AM - Escalation: Sarah types /inc escalate platform-team and Jake joins immediately.
3:05 AM - Fix deployed: Root cause identified (database connection pool exhaustion). Jake deploys fix.
3:18 AM - Resolution: Sarah types /inc resolve with summary. incident.io auto-generates post-mortem draft and creates follow-up tasks in Linear.
Total MTTR: 31 minutes with under 3 minutes coordination overhead. This represents a 26% reduction from a typical baseline of 42 minutes.
"We like how we can manage our incidents in one place. The way it organises all the information being fed into an incident makes it easy to follow for everyone in and out of engineering." - Harvey J. on G2
Minimizing risk during migration
Migrating mission-critical infrastructure requires careful planning. Here's how to de-risk the transition.
Pre-migration checklist
Before you start, document your current state:
- Export all Opsgenie data (users, schedules, escalation policies, alert integrations)
- Map critical workflows: which alerts must never be missed?
- Identify dependencies: do other teams rely on Opsgenie webhooks?
- Set success criteria: 100% alert delivery, <5 minute response times
Post-migration validation
After cutover, validate:
- All alert sources forward to incident.io
- On-call schedules match Opsgenie configuration
- Escalation paths work as expected
- Status page updates automatically
- Post-incident workflows trigger correctly
Schedule a test incident during business hours. Trigger a non-critical alert, walk through the full response workflow, and confirm everything works end-to-end.
How incident.io helps engineering teams move fast
For engineering teams, speed matters most. incident.io is purpose-built for this reality.
Support velocity that matches small team needs
incident.io provides shared Slack channels with engineering teams for support. When you hit an issue, you're talking directly to engineers who built the product.
"Incidentio has always been very responsive to our requests, open to feedback and quick reaction. It didn't happen only once when we reported some type of issue in the process to Incident.io support and in matter of hours the fix was released." - Gustavo A. on G2
AI that automates response
incident.io's AI SRE assistant automates up to 80% of incident response. It investigates issues, suggests fixes based on past incidents, and can identify the likely change behind incidents. For small teams without dedicated on-call engineers, this reduces the burden of routine issues.
Watch the AI SRE in action to see how it identifies root causes and generates remediation steps during off-hours.
Your next steps
The Opsgenie sunset is a forcing function, but for growing and modern engineering teams, it's permission to choose better tools. You don't need enterprise complexity. You need speed, clarity, and a platform that disappears into your existing workflow. incident.io delivers that in days, not quarters.
Book a demo to see the migration process walkthrough for your specific monitoring stack and understand how incident.io can reduce your MTTR.
Key terms glossary
Opsgenie sunset: Atlassian announced that Opsgenie will stop accepting new customers June 4, 2025 and shut down entirely by April 5, 2027, forcing all users to migrate to alternative platforms.
Slack-native: Architecture where the entire product workflow happens inside Slack using slash commands and channels, not just notifications linking to external web interfaces.
MTTR (Mean Time To Resolution): The average time from incident detection to resolution. Modern incident management platforms reduce MTTR by eliminating coordination overhead and context-switching.
On-call rotation: A schedule defining which engineer is responsible for responding to production alerts during specific time periods. Effective on-call management requires automated scheduling, escalations, and fair distribution of burden.
Alert routing: The process of directing alerts from monitoring tools to the appropriate on-call engineer or team based on service ownership, severity, and context. Poor routing leads to alert fatigue and missed incidents.
Status page: A public or private webpage showing real-time system status and incident updates. Modern platforms update status pages automatically based on incident state changes.
Post-mortem: A document analyzing what went wrong during an incident, why it happened, and what actions will prevent recurrence. AI-powered platforms auto-generate post-mortems from captured timeline data.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


