Post-mortem software features: Separating must-haves from nice-to-haves
February 16, 2026 — 14 min read
Updated February 16, 2026
TL;DR: The most critical post-mortem software feature isn't a fancy document editor. It's automated timeline capture during the incident itself. Manual post-mortem reconstruction wastes 60-90 minutes per incident as teams scroll through Slack history and memory. Modern platforms like incident.io eliminate this archaeology by capturing every Slack message, slash command, and integration event in real-time, reducing post-mortem writing from 90 minutes to 15 minutes. Must-have features focus on data capture and integration (Datadog, Jira, Slack). Nice-to-haves focus on formatting, custom branding, and complex approval workflows that slow learning.
When evaluating post-mortem software, most teams face the same challenge: vendor demos all look impressive, but feature lists don't reveal which capabilities actually reduce incident response toil. This guide breaks down post-mortem features into two categories, the automation that saves hours per incident, and the polish that looks good in screenshots but doesn't change outcome
The "post-mortem archaeology" problem: Why features matter
The average post-mortem takes 60-90 minutes to write (based on engineering teams incident.io works with). Not because analyzing root causes is hard, but because reconstructing what happened is archaeology. Engineers scroll through Slack history, toggle between PagerDuty alerts and Datadog graphs, and try to remember who said what across three different threads. Without proper post-mortem software, teams spend hours after incidents manually hunting down and copy-pasting chat logs, metrics from monitoring tools, and screenshots to piece together timelines. Engineers could spend this time on high-value engineering work instead of copy-pasting chat logs.
This manual timeline reconstruction is the core problem post-mortem software should solve. The goal of effective post-mortem software isn't to give you a prettier place to type. It's to eliminate the reconstruction phase entirely by capturing context automatically as the incident unfolds. Every feature should be evaluated against this standard: Does it reduce time from resolution to published learning?
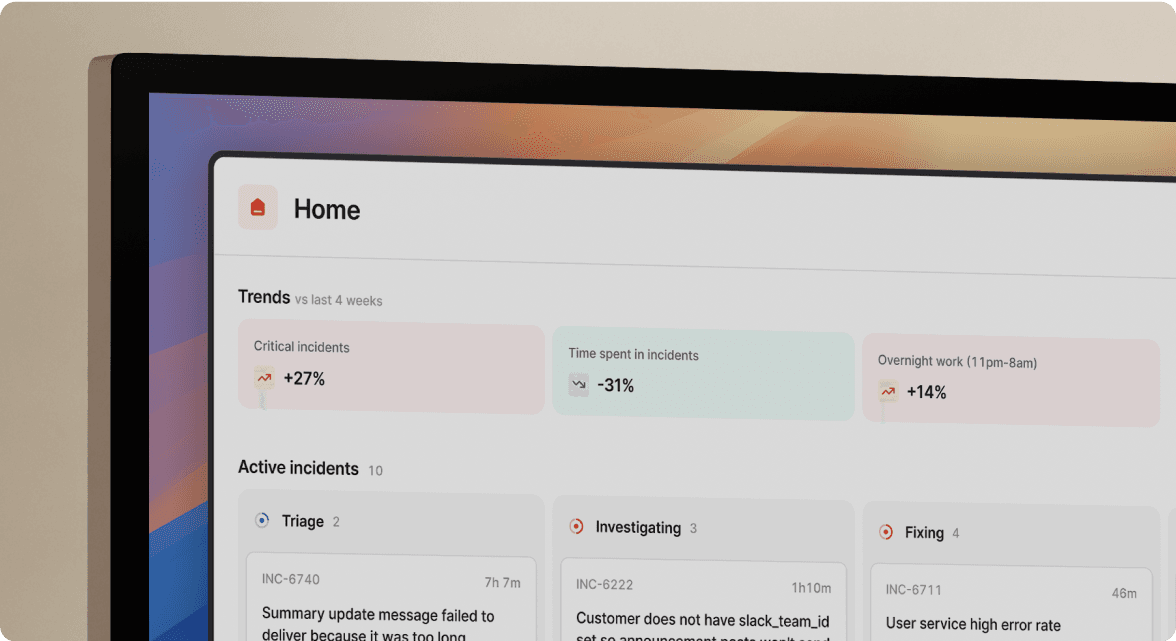
5 must-have post-mortem software features for modern SRE teams
1. Automated timeline capture (no more scroll-back)
The foundation of any post-mortem is an accurate timeline. Who did what, when, and why. Manual reconstruction from Slack history introduces errors, omits critical details, and wastes precious engineering hours.
Modern platforms capture every action automatically. When you run an incident using /inc commands, every action auto-populates the timeline: role assignments, severity changes, Slack threads, shared links. When someone posts "Restarted pods at 3:14 AM," the platform logs it with timestamp and attribution.
"My favourite thing about the product is how it lets you start somewhere simple, with a focus on helping you run incident response through Slack... I'm excited about all the new insights features they're building." - Chris S. on G2
incident.io's automated timeline generation means the platform acts as a scribe during incidents, creating events automatically from incident updates like severity changes and status changes, plus pinned Slack messages. The platform has already written 80% of your post-mortem when you type /inc resolve.
Without this automation, you're asking one engineer to be the designated note-taker instead of troubleshooting, or you're accepting that critical context will be lost. Neither option is acceptable.
2. Slack-native workflow integration
Context switching kills data quality. Each tool switch between PagerDuty, Slack, Jira, and Confluence risks losing thread, forgetting to document a decision, or duplicating work.
Slack-native incident management makes chat the primary interface so responders can declare incidents, coordinate, execute runbooks, and capture timelines inside the channel. The entire post-mortem workflow is built inside Slack.
When your Datadog alert fires, incident.io automatically creates a dedicated incident channel, pages the on-call engineer, and pulls in service owners based on your service catalog. The channel contains the triggering alert, recent deployments, runbook links, and a live timeline that's already recording. Everything happens where your team already works.
"Without incident.io our incident response culture would be caustic, and our process would be chaos... Unlike other similar incident management tools it's super easy and means we spend less time figuring out how to use incident.io, and more time focused on responding to the incident." - Matt B. on G2
3. Bi-directional tool integrations (Datadog, Jira, GitHub)
Post-mortems don't exist in isolation. They need to reference the monitoring graphs that showed the problem, create follow-up tickets for fixes, and link to the code changes that caused the issue.
True bi-directional integration means changes in either system propagate automatically. When Datadog fires an alert, incident.io auto-creates the incident channel, pages the on-call engineer, pulls in service owners, and starts timeline capture. When you resolve the incident, follow-up Jira tickets get created with full context from the timeline.
incident.io integrates directly with Jira, allowing teams to export follow-ups, create issues, and keep incident work up to date automatically. Linked issues stay in sync between systems. You can also export post-mortems for archival or collaboration using Confluence, Google Docs, or Notion.
The platform connects with over 50 integrations spanning monitoring tools, alerting platforms, ticketing systems, and documentation platforms. This isn't about checking integration boxes on a procurement form. It's about ensuring the data flows where your team needs it without manual copy-paste.
4. AI-assisted drafting (that actually works)
AI in incident management should be judged by practical utility, not hype. The question isn't "do you have AI?" but "what does your AI actually do to reduce toil?"
AI-powered Scribe joins your Zoom or Google Meet calls as a participant to provide real-time transcription and summaries. Scribe transcribes incident calls, highlights key decisions, and flags root causes mentioned during live discussions. When someone says "I think this correlates with the 2:30 AM deployment," Scribe flags it as a key moment. When you decide "let's rollback first," that decision is captured.
"The slack integration makes it so easy to manage the incident, it's a breeze to have it and not having to worry about forgetting some step... managing incidents should be about the issue in hand and not about remembering the steps in between." - Gregorio B. on G2
Scribe generates detailed notes with "Overview," "Key moments," and "Next steps" sections, 80% complete automatically. Engineers spend 10-15 minutes reviewing and refining instead of 90 minutes writing from scratch. This isn't magic. It's automation applied to the tedious parts so humans can focus on analysis and learning.
5. Actionable insights and meta-analysis
Individual post-mortems document what happened. Aggregated post-mortem data reveals patterns: Which services generate the most incidents? Are database connection pool issues recurring? Has MTTR improved this quarter?
Modern platforms provide queryable data sources for aggregated incident statistics. You can analyze incident response history over time using various graph widgets in dashboards to track Customer Impact Duration, Status Active Duration, Time to Detect, and other key incident metrics.
Organizations can identify if certain incident types happen frequently, if specific services or teams have more incidents, or if incidents spike at certain times. Post-mortem software helps identify common themes and areas for improvement across product boundaries, generating knowledge graphs and insights from incident data. This meta-analysis transforms post-mortems from compliance documents into actionable reliability data.
If your VP Engineering asks "why are we having so many database incidents?" you shouldn't need to spend four hours building a spreadsheet. Your post-mortem platform should answer that question in 30 seconds with a filtered dashboard view.
Nice-to-have features you can probably skip
Not all features add value. Some just add administrative overhead that slows the path from resolution to learning. Multi-level approval workflows that require sign-off from three managers before publishing contradict blameless post-mortem principles. When post-mortems should be published within 24-72 hours of resolution, approval bottlenecks delay learning and discourage timely completion. The goal is rapid knowledge sharing, not bureaucratic gatekeeping.
Engineers care about content, not fonts. The ability to customize header colors, adjust line spacing, or apply corporate branding to post-mortem templates adds configuration complexity without improving learning outcomes. Pre-built templates that follow SRE best practices are more valuable than infinite customization options that nobody will configure anyway. Unless you're reselling incident management as part of a managed service, white-labeling is solving a problem you don't have. Internal tools don't need to look like your brand. They need to work.
"Less time spent putting together an accurate timeline of an incident. It's so easy to pin important messages and updates and automatically it creates the timeline for you... Spend more time in post mortems looking at problem solving and long term improvements instead of worrying about paperwork." - Verified user on G2
Feature comparison: Essential vs. bloatware
This table reflects common evaluation criteria when assessing post-mortem platforms. Features are categorized based on their impact on reducing time from resolution to published learning.
| Feature category | Must-have | Nice-to-have | Why it matters |
|---|---|---|---|
| Timeline capture | Automatic Slack/Teams message capture with timestamps | Manual timestamp entry forms | Eliminates 60-90 min of manual reconstruction |
| Integration | Bi-directional sync with Datadog, Jira, PagerDuty | Read-only API connections | Prevents data loss from copy-paste between tools |
| AI Assistance | Call transcription, suggested summaries, root cause flagging | Generic text summarization | Reduces post-mortem writing time by ~80% |
| Workflow | Slash commands in Slack for incident management | Web-first UI with Slack notifications | Saves 10-15 min per incident from context switching |
| Analytics | Filterable dashboards showing MTTR, incident patterns | Static monthly PDF reports | Answers "are we improving?" in 30 seconds vs 4 hours |
| Export | One-click export to Confluence, Notion, Google Docs | Copy-paste to external docs | Enables one-click archival without reformatting |
| Approval process | Simple publish/share controls | Multi-level approval workflows | Removes bottlenecks that delay learning |
| Customization | Pre-built templates following SRE best practices | Custom CSS, fonts, branding | Engineers focus on content, not styling |
How incident.io automates the post-mortem process
From alert to analysis in one platform
When your Datadog alert fires for API latency, incident.io automatically creates a dedicated Slack channel like #inc-2847-api-latency-spike, pages the on-call engineer, and pulls in the service owner. During active incident response, every Slack message, role assignment, and command gets captured in a structured timeline. When you jump on a Google Meet or Zoom call, Scribe joins automatically and transcribes the entire conversation, extracting key decisions without requiring a dedicated note-taker. After resolution, you configure post-incident flows in Settings, selecting Confluence as the default destination. When you hit Export at the top of the completed post-mortem, all sections move to Confluence while follow-ups and timeline remain in incident.io's post-incident tab.
"incident.io is extremely easy to use. The platform is easy to set up and integrates well with several tools. Making it a critical part of our incident handling and communication process. It helps both during an incident and the post-incident/post-mortem process by allowing users with little training to manage incidents like pros." - Roro O. on G2
Focus on learning, not typing
The best post-mortem software is invisible. You shouldn't think about the tool during an incident. You should think about resolving the incident while the tool captures everything in the background.
If your team handles 20 incidents monthly at 90 minutes per post-mortem, you're spending 30 hours monthly on reconstruction. At $150 loaded engineer cost, that's $4,500 monthly spent on documentation overhead, not reliability improvements. Automation shifts engineer time from tedious data gathering to high-value root cause analysis and learning.
Evaluate post-mortem software against one metric: Time to Learning. How quickly can your team go from resolving an incident to publishing a complete, accurate post-mortem that prevents the next incident? Features that reduce that timeline are must-haves. Everything else is nice-to-have.
Book a demo to see how Scribe transcribes calls and AI suggests summaries in real-time.
Key terminology
MTTR (Mean Time To Resolution): Average time from incident detection to full resolution. Modern incident management platforms help teams reduce MTTR by eliminating coordination overhead and automating context capture.
Root Cause Analysis (RCA): Investigation process to identify underlying system factors that led to an incident. Modern SRE thinking recognizes there's rarely a single root cause in complex systems.
Blameless Post-mortem: Structured incident review focusing on identifying contributing causes without indicting individuals. Assumes everyone involved had good intentions and did the right thing with available information.
Timeline Capture: Automated recording of incident events including Slack messages, commands, and integration events with timestamps. Eliminates manual reconstruction that typically takes 60-90 minutes per incident.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


