How to communicate on your status page
October 26, 2021 — 6 min read

When you’re deep into an incident and there’s alerts firing, decisions to be made, and people to escalate to, it’s easy for outward communication with your customers to fall off the priority list.
In many regards this makes sense; it seems natural to put all of your focus and energy into minimising the impact and getting things back on track as soon as possible. But in reality, customers want to know what's going on, and underinvesting effort in communication with them can have damaging and lasting effects on your organization.
Take a look at social media though and the difference in sentiment towards companies that communicate well and those that don’t is stark. A well handled incident is an opportunity to build trust and strengthen the relationship between you and your customers.
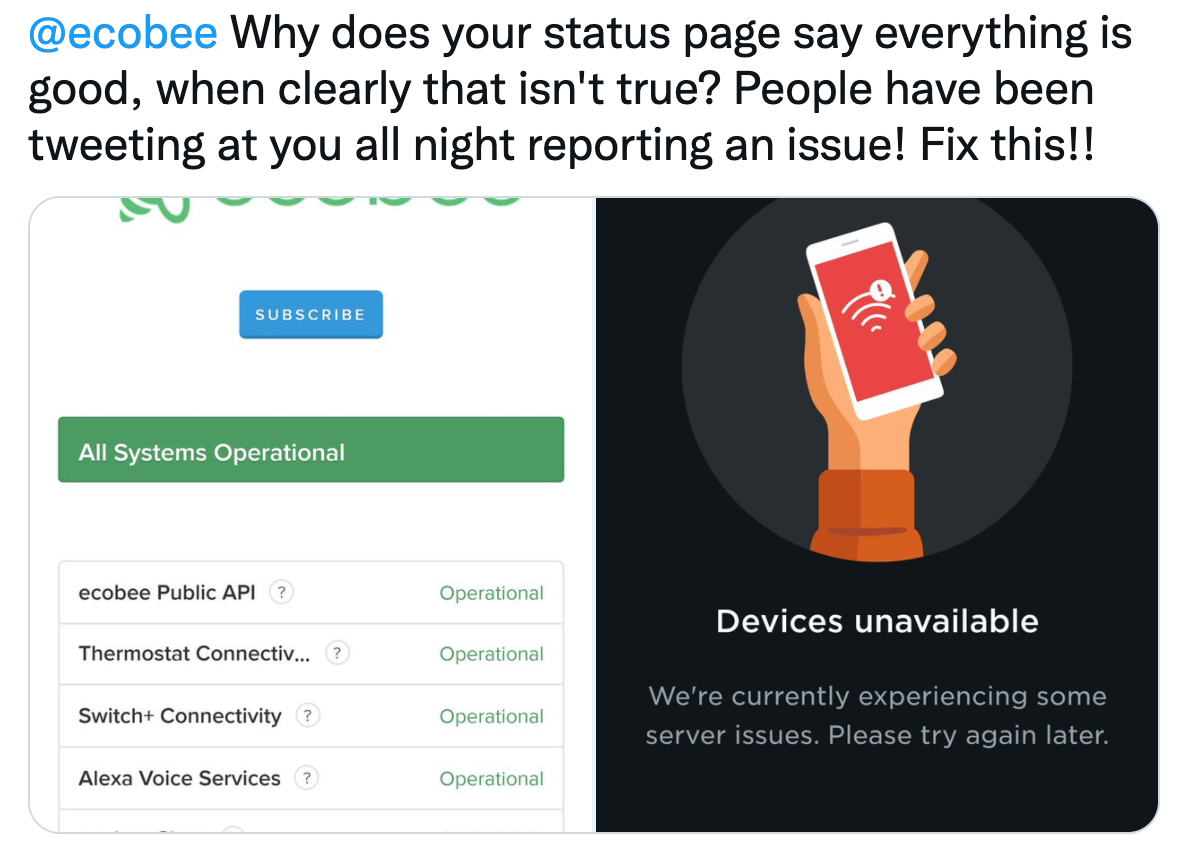
Good response makes a massive difference to how your organization is perceived.
We’ve spent time on both sides of this problem, both sharing updates as providers of a service (👋 status.incident.io), and being on the receiving end of both good and bad updates. We’ve got a pretty good idea of the atoms that contribute to the best communication, so here you go: our five steps to better communication with your customers.
Provide context to minimise speculation
If your service is down and you neglect to share any details, your customers will assume the worst. If your website serves an generic error page, they’ll assume human error and speculate on your competence. If there’s any rumour of a data breach, they’ll assume their details have been compromised and fear for the security of their data.
The longer they speculate the more frustrated they’ll get, and the worse they’ll assume the issue is. Put their minds at ease by providing some context.
It’s not always possible (or desirable) to provide the full details of what’s going on, but the smallest amount of information can go a long way to allaying your customers’ concerns. If your entire database is down, a simple “one of our systems has a problem and we’re working to bring it back online” will work wonders.
Heroku doing a fantastic job of providing all the context they have (source)
Explain what you’re doing to demonstrate you're 'on it'
There are few things more frustrating than a holding message stating you’re “doing everything possible to get things back to normal” that persists for hours on end without change.
At the most fundamental level, it’s helpful to explain where you’re at in your response process. If you’re on the case but not sure what’s going on, tell your customers you’re investigating the problem. Once you know what’s up and are working on the fix, tell them that too. Nobody likes waiting without knowing what’s going, so bring them into the loop.
If you’re spending a long time in any specific status, there’s no harm in repeating yourself. There’s a zillion different ways to say you’re investigating a problem, and even if you’re restating the same thing, maintaining a cadence in your incident communications demonstrates you’re still taking things seriously.

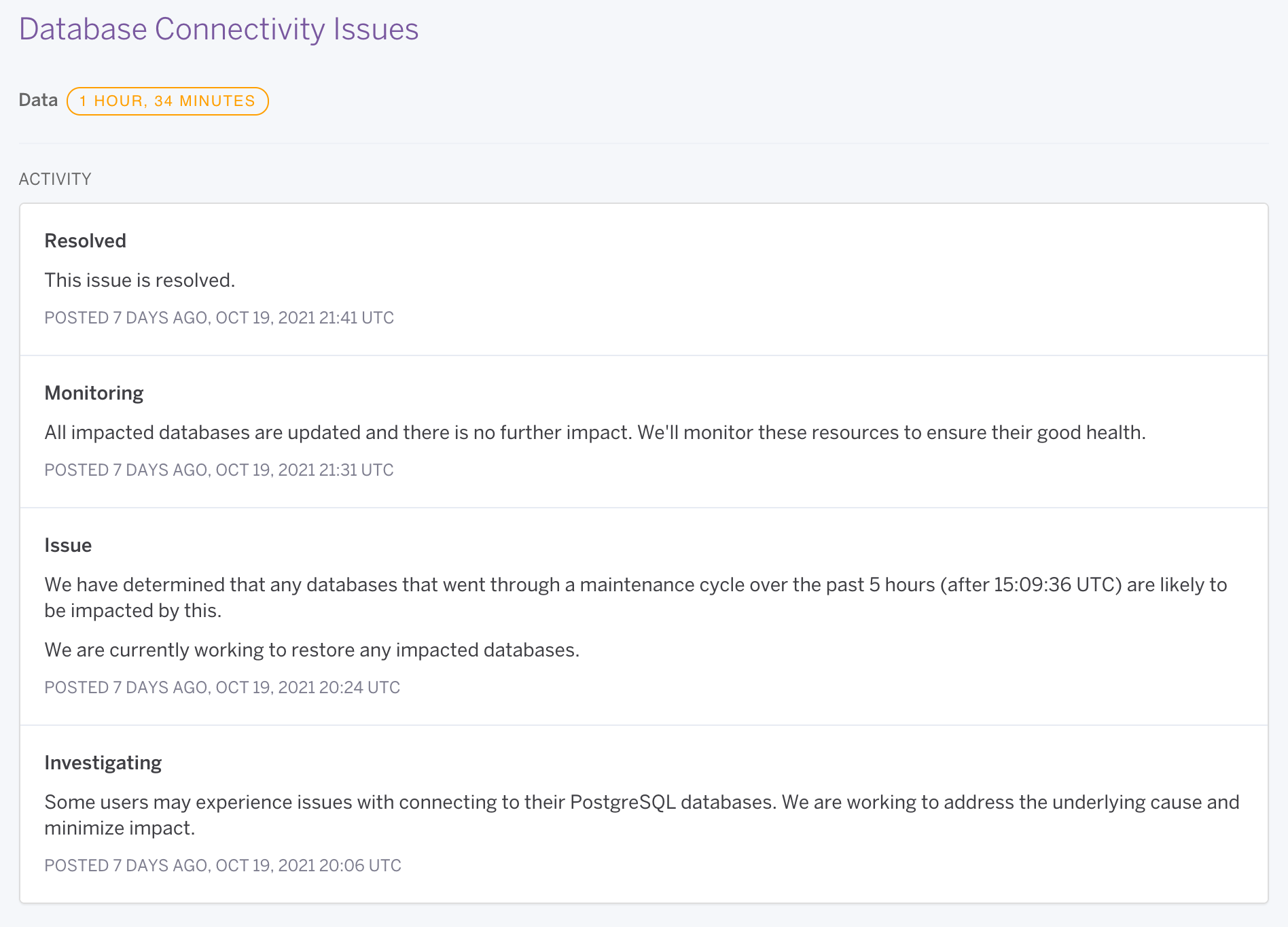
GitHub demonstrating the power of repeat 'investigation' updates (source)
Set some expectations for when things will return to normal
For any prolonged outage, it’s helpful to set expectations around when you expect normal service to resume. We’ve been on the fixing side of this, and understand the challenges this can present: if you’re dealing with something that’s never happened before it’s hard to know how long that’ll take, and time spent estimating is time not spent on resolving the issue. It’s absolutely fine to say “we don’t know how long it’ll take”, and far superior to setting no expectations at all.
In some cases you will know the timelines more concretely. If you’re performing a full database restore that you know will take six hours, why not pass that on?
In general, once you’re over a few hours of outage, it’s reasonable for customers to expect an estimate that tells them whether they’re looking at hours, days or weeks.
Tell people what they should do
When you’re in the midst of an incident, your customers are also in unfamiliar territory. It’s not always clear what they should do, and you’ll often see changes in behaviour as a result.
That might mean a few extra requests to your website as people furiously smash the refresh button, or it could lead to more serious consequences like overwhelming your customer support staff, or customers trying to cancel their orders. Ambiguity over the actions people should take isn’t good for them or you.
The good news is that it’s easily avoided by being directive about what your customers should do. If refreshing the page is making things worse for you trying to restore service, ask your customers not to. If you want to limit inbound demand on your support staff, provide the information they need and ask them to avoid getting in touch for anything non-urgent.

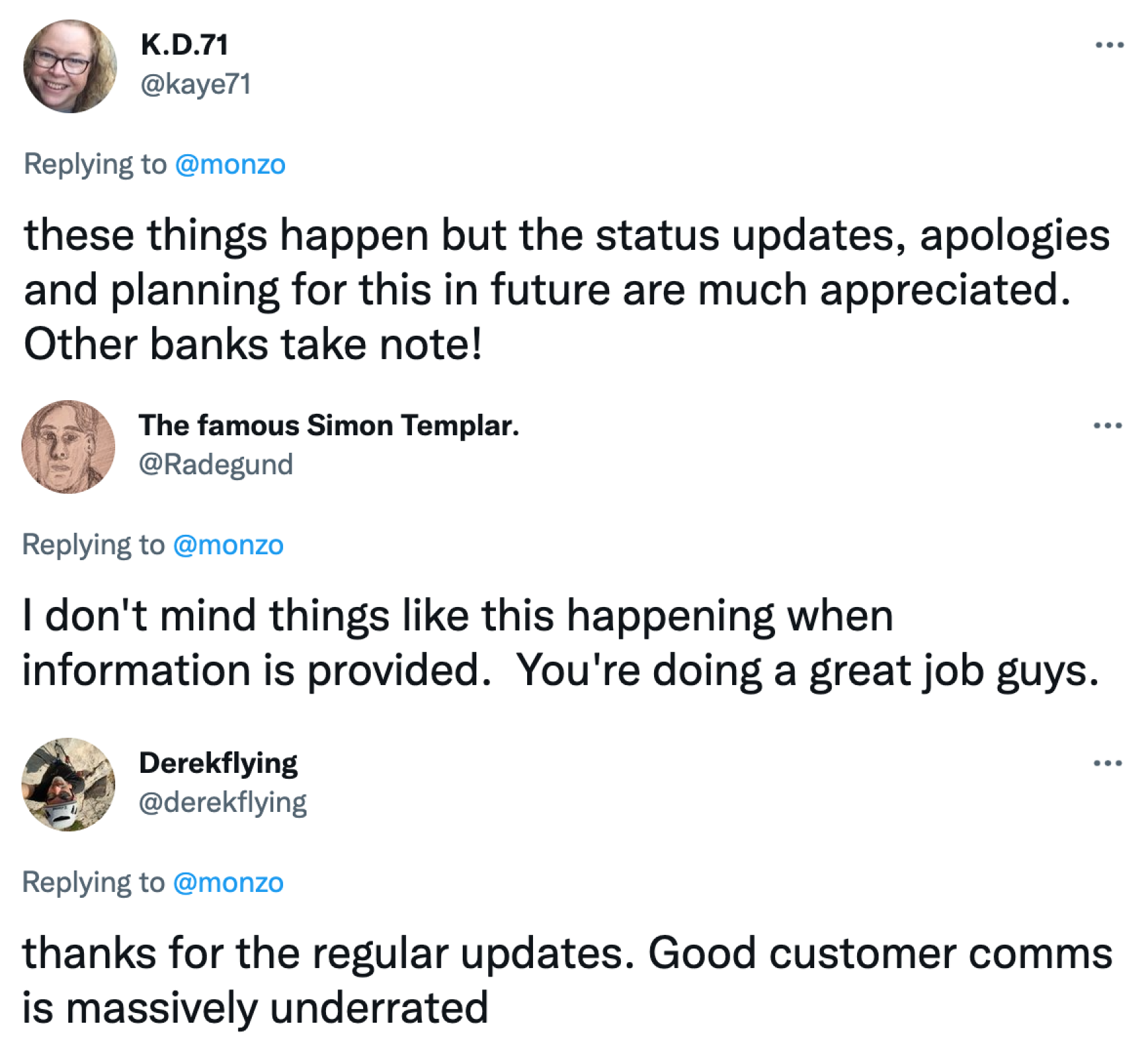
Monzo telling customers what's going on and exaxtly what they should do (source)
Let folks know when you’ll be updating them next
The final piece of the update puzzle is letting folks know when you’ll be back in touch (and sticking to it!). You might only have the same story to tell, but even a simple "we're still on it, but no change" is better than hours of silence.
Who does it best?
Many companies that do an incredible job of keeping customers well informed during incidents. Too many to list them all here, but if you’re looking for inspiration, these are the folks we think exemplify good practice:
- Heroku: https://status.heroku.com
- GitHub: https://githubstatus.com
- Cloudflare: https://cloudflarestatus.com
- Monzo: https://status.monzo.com
- GitLab: https://status.gitlab.com/
Someone else we should feature here? Get in touch in our community Slack.

Chris Evans
Co-Founder & Field CTO
I'm one of the co-founders, and Field CTO here at incident.io.
See related articles

5 strategies to improve your incident communication
Effective incident communication is key to ensuring that the collaboration needed to resolve an incident is happening and that no one is left in the dark.
 Luis Gonzalez
Luis GonzalezApril 2, 2023

Why you need an internal status page
Status pages are commonplace for companies to communicate externally to customers. But how do internal stakeholders get internal-only information: internal status pages!
 Isaac Seymour
Isaac SeymourAugust 1, 2023

How we built it: incident.io Status Pages
How we a built fast, reliable status page solution in three months.
Isaac SeymourApril 19, 2023
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


