Customer Success at an early-stage B2B SaaS company
February 15, 2022 — 8 min read

Based on our newfound data feet, we’ve started consistently tracking the adoption rate of our latest features. As it happens, we’ve been impressed with the results!
For example, we were delighted to see that our new tutorial flow was completed end-to-end by 35% of our users (against an industry average of less than a quarter for 6-step product tours like ours).
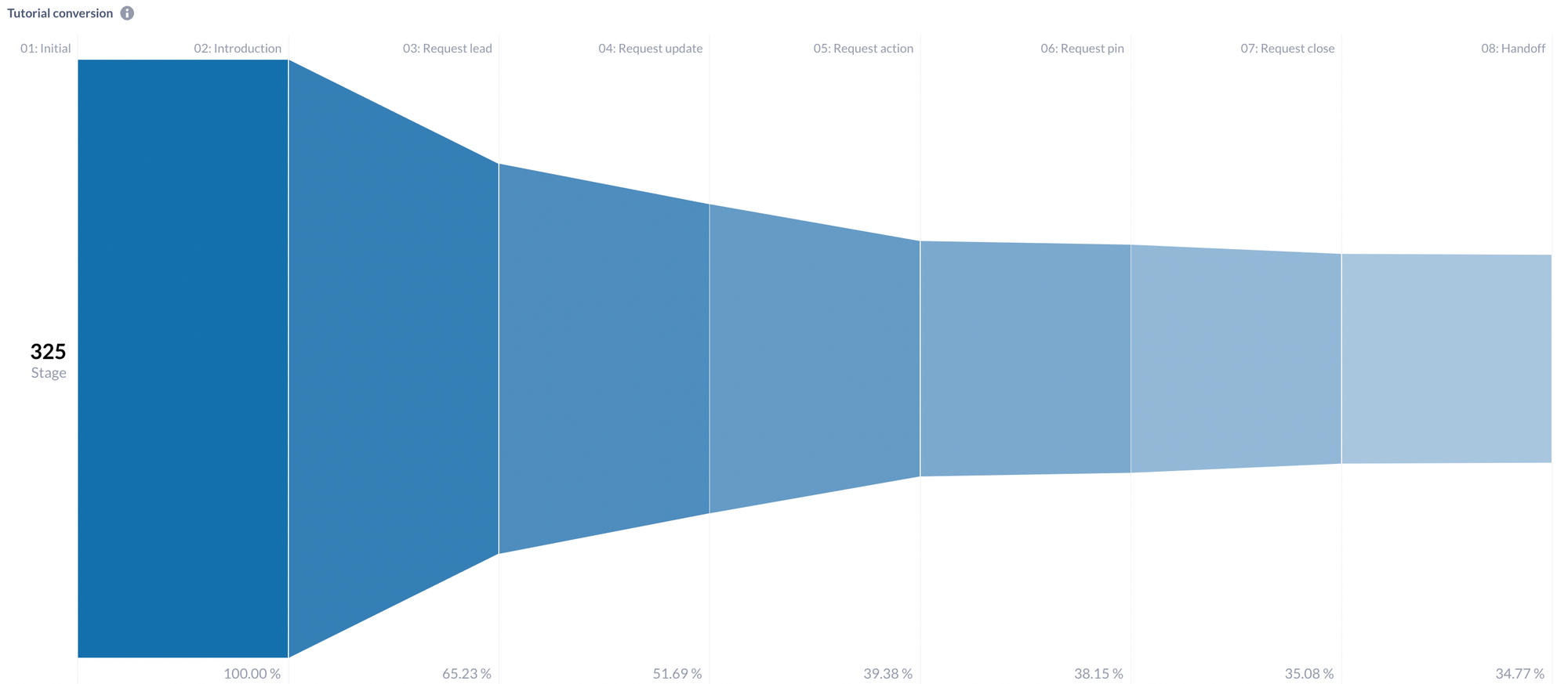
I know, I know: being at such an early stage means it is arguably easier to hit customer needs on the head. Regardless, we’ve built a tight feedback loop with customers that works for us, and has contributed to these above-par results.
In this post, we walk through how we work through customer requests at incident.io today, and a couple of things we’d like to do next to improve further.
Feedback channels
We receive feedback via 4 main channels, ranked by how contextualised and detailed the feedback is:
- Customer calls - We have at least 5 a week, and want to do even more because it is where the most detailed and nuanced insights are tapped into.
- Slack Connect channels - These are direct channels we have between the customer and the entire incident.io team (including engineers).
- Slack Community - Our incident.io community has over 350 members who drop great ad-hoc pointers for us to pick up.
- Intercom - Users mostly reach out on Intercom to highlight discoverability issues (’I couldn’t find...’, ‘is there a way to...’), which are less feature requests, but more fantastic feedback to improve our usability.
Tooling stack
From most to least client-facing:
- Grain: it automatically transcribes customer calls and grabs visual snippets from them. Being able to capture an “aha!” or “what?” moment is so powerful, especially when you can show the product team exactly what you mean.
- Slack (Connect) + Intercom: both great for meeting our users where they are, and capturing that in-the-moment feedback. We spin up Slack Connect channel with our customers for faster turnaround, on top of our Slack community. We also take advantage of Intercom’s integration with Segment to get a good sense of who our customers are and how they’ve been using the product. Additionally, every Intercom message is routed to our Slack
#supportchannel. We use our own product, but it’s invaluable to be able to see how everyone else uses it, and how this differs across different customers. - ProductBoard + Linear: we use ProductBoard to host our public roadmap, and centralise and organise feature requests. We use Linear to log small improvements or ‘polish’, and track our day-to-day work. The line is often thin, but the rule of thumb is ‘anything that is low-ish effort and doesn’t require an in-depth product discussion goes to Linear, larger pieces go to ProductBoard’.
- Metabase: brings all our analytics together. Our users are nice people: they won’t always give constructive criticism, so we also make sure we keep objectivity by looking at indirect feedback signals hidden in product usage data. More on our data stack here.
5 things that have worked really well for us
Digging into the "why"
This is a well-known must-do, but we try to be extremely thorough in digging into the use cases and contexts around feature requests. Jobs-to-be-done and customer segmentation are key to delivering the right solution. Here are some examples of how we surface deeper customer needs:
...[W]e see test incidents as a useful way for people to upskill themselves on the product in private. Can you help me understand why you'd want to prevent people from creating them? Thanks!
What's the value this provides over a standard Slack channel. Is it just that it's communicated widely that maintenance is going on, or the ability to flip quickly into incident mode, or something else? Not trying to grill you, but curious as to your motivations and ideal scenario here 🙂
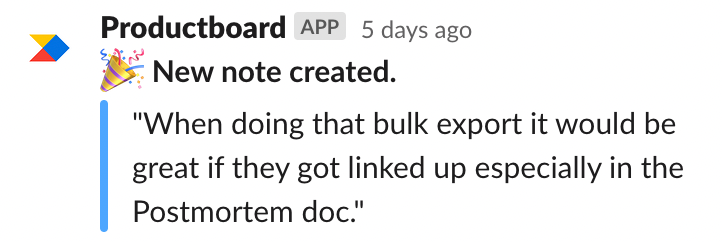
Using the Slack <> Productboard integration as a visual ‘we heard you’
When we push a Slack Connect message from a customer into Productboard, the app pings the channel in a thread to say someone at incident.io took note of the customer’s feedback. It’s a small detail, but it’s proven really powerful to make our customers (duly) feel heard. We’ve had quite a few users say things like ‘Thank you for listening’ off the back of those.
Sharing new feature proposals
It’s often easier for users to feedback on something concrete. Thus, we write out a short proposal to our users for any new feature. This helps cement (double-combo pun!) what the feature will look like, and match that to the mental model of their use case and organization.
We’ve been able to quickly shift the scope and look of a feature in days, based on those proposals.
Keeping customer success and engineering close and united
Though we will eventually hire a Product Manager, the fact that Customer Success (CS) and Engineering work hand-in-hand on product without a middle(wo)man has been incredibly powerful.
The role of CS is: to make sure we collect as much feedback as possible; to document that feedback; to groom and broadcast it via ProductBoard/Linear and the internal #product Slack channel.
This way, engineers have 1) a very clear picture of how many and what type of users request what feature, and 2) rich context and use cases to work from on (vs already-interpreted solutions).
Conscious separation of Customer vs Prospect feedback
All things being equal, we prioritise making existing customers happier over winning over new customers (Prospects).
This means we need to reflect consistently if a feature request would help us win a deal, or make an existing customer’s life easier. In reality, life is messy and there’s overlap — they often want the same things!
What’s next?
We’re less than a year old as a company and highly capacity-constrained. There’s lots we still want to experiment with to have an even tighter customer <> product loop.
A couple of things we’re mulling on and will hopefully implement soon (come give us a hand!).
- Finding a Customer Success CRM: no affordable solution we’ve looked at so far seems to centralise 1) external customer data (Intercom chats, emails, Slack Connect, calls etc.) and 2) internal customer data (product usage) all under one roof - that makes us really sad and less efficient, so if you have a tip here let me know at esther@incident.io!
- Scaling customer calls: we’d like a more systematic process to reach out to more users for in-depth feedback calls.
- Consistent NPS: we request feedback on a very ad-hoc basis, but would love to be more intentional in gathering and tracking NPS data.
- Gathering feedback post-trial: we currently don’t have a methodical way to chat to users that didn’t convert to paid after the end of our trial period, which is a lost opportunity to get very valuable feedback.

Esther Delignat
Sales Engineer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

