Best Opsgenie alternatives for customer success teams in 2026
February 20, 2026 — 15 min read
Updated February 20, 2026
TL;DR: Atlassian is shutting down Opsgenie by April 2027, forcing teams to migrate. The best alternatives automate customer communication during outages, not just alerting. incident.io unifies incident response and status page workflows in Slack, eliminating manual updates that create friction between engineering and customer success. PagerDuty offers robust enterprise alerting but adds complexity with subscriber-based status page pricing. Jira Service Management is Atlassian's default migration path but lacks real-time coordination optimized for incidents. Choose tools that automate the bridge between technical response and customer updates.
Engineers need to focus on fixing problems during incidents, not fielding "Is it fixed yet?" DMs from customer success, manually updating forgotten status pages, or losing debugging time to communication overhead.
Opsgenie handled alerting well for years, but it leaves customer success teams in the dark. Engineers become the middleman between the outage and the customer, manually bridging the gap while production burns. The best Opsgenie alternatives automate the updates your customers need, keeping customer success informed and your engineers focused.
Why Opsgenie creates friction between SRE and customer success
Opsgenie's architecture creates systematic silos between engineering response and customer communication. The platform routes alerts to engineers effectively but requires manual tagging workflows to update external status pages through Atlassian Statuspage integration.
The manual workflow is telling: you must add specially formatted tags like "cmp_API" to alerts, ensuring tags are case-sensitive and match component names exactly. During a production outage, this overhead distracts from troubleshooting. One missed tag means your status page shows "All systems operational" while customers experience downtime.
Customer support tools sit disconnected from your incident response. When customer success gets flooded with tickets during an outage, they have zero visibility into what engineering knows. They ping engineers for ETAs, engineers context-switch from debugging to write updates, and critical information degrades as it passes from engineering to customer success to customers.
The impact is real: customer trust erodes when status pages lag behind reality, support ticket volume spikes because customers can't see what's happening, and engineers lose debugging time to manual, repetitive communication tasks. With Atlassian sunsetting Opsgenie, this forced migration is an opportunity to fix the biggest broken process in your incident response stack.
Evaluation criteria: What customer success needs from your incident tool
Customer success teams need real-time visibility without becoming a bottleneck. Look for four critical capabilities that eliminate the engineering-to-customer communication gap.
Automated status page updates eliminate manual workflows. Updates should trigger directly from technical workflow. When an engineer identifies root cause in Slack, the status page updates without a separate dashboard login. No 15-minute lag between "we know what's wrong" and "customers know we're working on it." The automation should update both internal and external status pages, freeing engineers from administrative work.
Subscription and notification flexibility lets customers control what they hear about. Subscribers should choose to follow the entire status page or specific components, receiving notifications via email or SMS when incidents affecting their chosen services are declared or updated. A customer using only your API doesn't need alerts about dashboard downtime.
Support tool integration prevents duplicate work. The ideal setup displays incident status directly inside Zendesk or Intercom tickets, so support agents see ongoing incidents when viewing customer inquiries. Real-time synchronization between incident timelines and support tickets means customer success gets automatic updates without engineers manually writing summaries.
Private versus public updates solve the "what can we say externally" problem. Engineering needs detailed technical context, while customers need sanitized reassurance. Tools should support sending detailed notes to customer success internally and customer-appropriate updates externally simultaneously, without forcing engineers to write two versions.
Top Opsgenie alternatives for customer-facing incident response
The following tools represent different approaches to solving the communication problem, with varying levels of automation and integration depth.
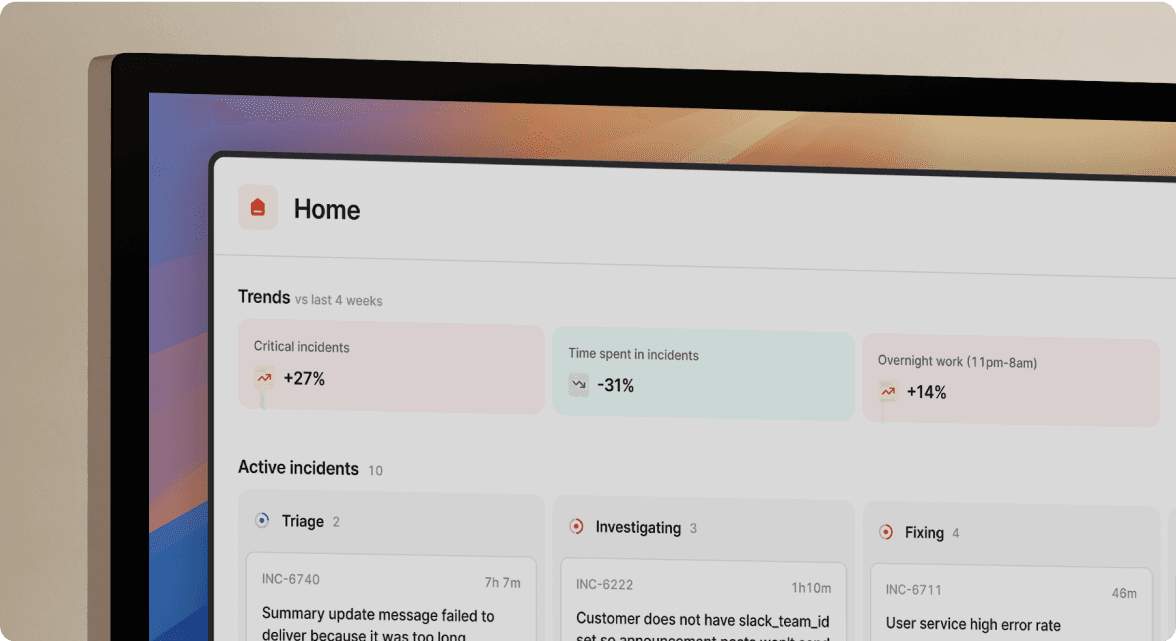
1. incident.io: Best for automating customer communication
incident.io replaces both Opsgenie's alerting coordination and Statuspage's customer communication in a single Slack-native platform. When a Datadog alert fires, incident.io auto-creates a dedicated Slack channel, pages on-call engineers, and starts capturing the incident timeline automatically. Engineers update customers directly from the incident channel using workflows, no separate dashboard login required.
Native Zendesk integration with bi-directional sync means when support agents view incoming tickets, they see snapshots of ongoing incidents automatically. Updates on the incident appear as internal notes on Zendesk tickets. The Intercom app for status pages provides similar capabilities, surfacing incident status directly where support teams work.
"External and internal status pages integrate nicely with custom fields and flows; and incident.io integrates nicely with our existing monitoring, alerting, and communications stack." - Verified user review of incident.io
Configure workflows once to define which incident types update which status page components, then automation handles the rest. Multiple status pages support different customer segments without multiplying manual work.
Pricing: Pro plan costs $25/user/month for incidents plus $20/user/month for on-call ($45 total). The migration from Opsgenie is straightforward with dedicated import tools.
2. PagerDuty: Best for enterprise alerting and legacy integrations
PagerDuty dominates enterprise incident alerting with battle-tested reliability and deep integration ecosystem. The platform excels at routing complex alert patterns across large organizations.
For customer communication, PagerDuty's Business plan includes external status pages up to 500 subscribers. Status pages are sold in 1,000-subscriber packs with additional costs beyond base licensing. The essential add-ons package costs $14,436 annually, combining AIOps, PagerDuty Advance, and Status Page features.
Status page updates typically happen through a separate web interface, not directly from the incident coordination channel. Customer success teams need separate access provisioning, and the integration between incident management and status page communication feels bolted-on rather than unified.
PagerDuty fits enterprises standardized on the platform with dedicated teams managing complex on-call rotations. The reliability is proven, but mid-sized teams seeking automated customer communication often find the cost and complexity outweigh benefits.
3. FireHydrant: Strong service catalog and runbooks
FireHydrant emphasizes service catalog depth and runbook automation. Automated and customizable status pages offer both public and authenticated options. Runbook automation can update status pages automatically based on workflow triggers.
The Zendesk integration allows support staff to create incidents and link existing incidents to support tickets, with incident status updates automatically posted back as internal notes. The workflow feels more runbook-driven than real-time conversational compared to Slack-native alternatives.
FireHydrant works well for mid-sized engineering organizations with mature service catalog practices who want runbook-driven consistency.
4. Jira Service Management (JSM): The default Opsgenie migration path
Atlassian is pushing Opsgenie users toward Jira Service Management. For organizations standardized on Atlassian products, JSM offers tight integration within that ecosystem.
The challenge for real-time incident response: JSM is fundamentally a service desk tool. The workflow feels ticketing-focused rather than optimized for fast-paced coordination during production outages. Status pages cost extra, and many essential features are locked behind Premium or Enterprise plans.
JSM makes sense if you're deeply invested in Atlassian's ecosystem and willing to accept a service desk workflow for incident management. For teams prioritizing real-time coordination and automated customer communication, dedicated incident platforms provide clearer advantages.
5. Rootly: Slack-based alternative for startups
Rootly offers a Slack-native approach, positioning itself for cross-functional incident response. The platform automates updating status pages and emphasizes accessibility for customer success teams and non-technical stakeholders.
Built to be simple so even non-engineers can use it, Rootly provides over 70 integrations covering most common tool stacks. The platform uses AI-driven insights to identify patterns across incidents.
Rootly fits teams wanting Slack-native incident management with AI pattern recognition and cross-functional accessibility.
Comparison: Status page capabilities and customer success workflows
| Platform | Automated status updates | CS tool integrations | Ease of use for CS teams | Pricing model |
|---|---|---|---|---|
| incident.io | Workflow-based automation | Native Zendesk and Intercom with bi-directional sync | Support agents get incident snapshots in tickets automatically | $25/user/month base (Pro), on-call add-on $20/user/month ($45 total) |
| PagerDuty | Yes, subscriber limits in Business plan (up to 500) | Limited integrations requiring separate configuration | Separate dashboard login required | Subscriber-based status page packs, essential add-ons $14,436 annually |
| FireHydrant | Yes, runbook automation updates pages | Zendesk integration for ticket linking and status updates | Runbook-driven interface | Annual and monthly payment options available |
| JSM | Limited, status pages cost extra on Premium/Enterprise | Strong ITSM integrations within Atlassian ecosystem | Ticket-focused interface | Tiered with add-ons, many features locked behind higher tiers |
| Rootly | Yes, automates internal and external pages | 70+ integrations including support tools | Built for non-engineers and cross-functional teams | Bundled pricing starting at $20/user/month |
The key differentiator: which platforms treat customer communication as a first-class feature versus an afterthought add-on.
Making the switch: How to migrate from Opsgenie without breaking trust
The right migration strategy runs both systems in parallel, validates routing rules, and trains teams before cutting over completely.
Audit your services and map ownership. Export your Opsgenie teams and services. Map each team to customer-facing service components, which services affect which customers? incident.io can pull through organizations from Zendesk into Catalog, allowing you to tag which customers are affected by each incident.
Run parallel systems for validation. The safest migration approach runs both systems simultaneously for a validation period, recommended between one day and two weeks. Configure monitoring tools to send alerts to both platforms. You can connect Opsgenie directly to incident.io as an alert source to test on-call features without moving alert providers immediately.
Pre-approve communication templates with customer success. Work with customer success to create templates for common incident types: "API degraded performance," "Database connectivity issues," "Scheduled maintenance." Workflows can automate when and how to update customers based on incident severity and affected services.
Train customer success on the new status page. Show customer success where to look when customers ask questions during outages. Create internal status pages that provide more technical detail than public pages. Walk through status page subscriptions so customer success understands how customers opt-in to component-specific updates.
Migration checklist:
- Audit services, map to status page components, document ownership
- Import Opsgenie users, teams, and schedules using dedicated import tools
- Configure parallel alert routing from monitoring tools to both systems
- Run 5-10 real incidents through both platforms, validate routing
- Create communication templates with customer success input, configure workflows
- Train customer success team on status pages and support tool integrations
- Cut over primary alerting to new platform
Choose the tool that keeps customers in the loop automatically
Atlassian's Opsgenie shutdown forces a migration decision, but it's also an opportunity to fix the broken communication workflows that erode customer trust during outages.
Don't just replace alerting, upgrade your communication. Choose platforms where status page updates happen as a natural byproduct of incident response workflow, not as a separate manual task. Verify that customer support tool integrations are native and bi-directional, not third-party middleware requiring custom configuration. Compare whether pricing bundles communication features or charges separately for status pages and subscriber counts.
Schedule a demo to see how automated status page workflows and native Zendesk integration work with your actual incident response stack.
Key terminology for incident communication
Status page: A public or private web page that displays real-time information about system availability and performance, allowing teams to communicate service status to customers and stakeholders during incidents and maintenance windows.
Incident subscriber: Users who receive secure service status updates via email or SMS. Subscribers can follow the entire status page or specific components, receiving notifications only when incidents affecting their chosen services are declared or updated.
Communication playbook: A pre-defined set of rules, templates, and automated workflows that guide incident responders on what to communicate, when, and to whom during an incident. Playbooks outline clear roles and responsibilities so individuals know what they're accountable for during high-pressure moments.
Alert route: A configuration that determines where an incoming alert should be sent based on attributes like severity, service, team, or custom fields, equivalent to Opsgenie's routing rules but with more flexible catalog-based routing in modern platforms.
Escalation path: A multi-level notification sequence defining who gets paged and when if an alert is not acknowledged, controlling notification urgency and ensuring critical alerts reach the right responders.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

