Best incident management tools for retail and e-Commerce
January 26, 2026 — 25 min read
Updated January 26, 2026
TL;DR: E-commerce downtime during peak traffic means immediate revenue loss. A 10-minute Black Friday outage versus 45 minutes can cost hundreds of thousands of dollars. Success requires automating coordination so your team assembles in seconds, not minutes. Use Slack-native incident management to eliminate context-switching, integrate status pages into your response workflow to deflect support tickets, and focus on rapid mitigation over root cause analysis during events. Teams using this approach reduce MTTR by up to 80% by cutting coordination overhead from 15 minutes to under 2 minutes.
Why incident management is different for e-commerce and retail
When your checkout service fails at 2 PM on Black Friday, you're not just dealing with a technical problem. You're watching revenue evaporate in real-time while customers rage on Twitter and your support queue explodes. Mid-size retail firms lose $200,000 to $500,000 per hour during standard operations. During peak season, e-commerce platforms can lose $1 million to $2 million per hour.
For context, when Amazon experienced an outage during Prime Day 2018, the company lost an estimated $100 million in sales, roughly $1.2 million per minute. Your platform might not be Amazon-scale, but the principle holds: every minute of downtime equals measurable lost revenue, not abstract "user impact."
The customer-facing factor changes everything
Unlike internal B2B tools where outages affect your own team, retail incidents are public. Your customers don't file support tickets and wait patiently. They abandon carts, complain on social media, and shop with your competitors. Research shows 98% of organizations report that a single hour of downtime costs over $100,000, with 81% facing costs exceeding $300,000 per hour.
This means your incident response spans three simultaneous dimensions:
- Technical: Fix the broken service (checkout API, inventory sync, payment gateway)
- Customer communication: Update your status page to stop the flood of "is your site down?" tickets
- Business continuity: Implement workarounds fast (manual order processing, backup payment provider, feature flags to disable broken flows)
Traditional incident management tools handle the first dimension. They wake you up when something breaks. But they don't help you coordinate the complex response required when 50,000 customers are trying to check out simultaneously and your database connection pool just maxed out.
"incident.io brings calm to chaos... Incident.io is now the backbone of our response, making communication easier, the delegation of roles and responsibilities extremely clear, and follow-ups accounted for." - Braedon G on G2
Preparing for peak traffic: Black Friday and Cyber Monday strategies
Prevention is cheaper than response, but prevention alone won't save you. Shopify processed 90 petabytes of data during Black Friday Cyber Monday, peaking at 489 million requests per minute on their edge network. Even with perfect preparation, something will break at that scale.
Load testing and chaos engineering
Start load testing at least 6-8 weeks before Black Friday according to industry recommendations. Focus on critical user journeys: browse, add to cart, checkout, payment processing. Shopify runs bimonthly fire drills all year, simulating 150% of last year's BFCM load. Each test exposes bottlenecks in Kafka, memory limits, or timeout configurations that teams can fix and revalidate before the real event.
Don't just test happy paths. Use chaos engineering to simulate these failure scenarios:
- Database primary failover during checkout flow
- CDN degradation causing slow image loads
- Payment gateway timeout requiring fallback provider
- Inventory service returning stale data
These aren't theoretical. They're incidents that happened to other retailers during peak traffic. Test your team's response, not just your infrastructure's capacity.
Game Day exercises
Game Days are chaos engineering exercises that test both systems and people. Run cross-system disaster simulations that inject network failures, randomize navigation to mimic real users, and test search and product page endpoints under failure conditions.
The goal isn't proving your systems never fail. The goal is proving your team can coordinate response when they do. One engineering team runs "Critical Journey Game Days" where they deliberately break checkout while forcing responders to use their actual incident management process. If your process involves hunting through Confluence for runbooks or manually creating Slack channels, you'll discover that bottleneck in Game Days, not during Black Friday.
For a detailed walkthrough of running these simulations, watch this full platform walkthrough showing how teams coordinate response using automated workflows.
Code freeze and risk assessment
Implement a code freeze at least 30 days before Black Friday. No feature deployments, only critical security patches with explicit VP approval. Use "What Could Go Wrong" (WCGW) exercises to document failure scenarios, set escalation priorities, and generate Game Day test cases.
Your WCGW list must cover:
- Primary payment gateway fails: Do you have a backup gateway configured and tested?
- CDN degradation: Do you have a backup CDN ready to activate?
- Database connection pool exhaustion: Do you have automatic scaling configured? Is your manual runbook ready?
- Inventory API returns incorrect stock counts: Do you have a circuit breaker to fail safely?
For each scenario, document the mitigation steps and assign owners. Then test those mitigations during Game Days so they're muscle memory, not theory.
Third-party dependencies
You control your infrastructure. You don't control Stripe, Shopify Payments, or UPS shipping APIs. Identify every external dependency in your checkout flow and document fallback options:
- Payment processing: Secondary gateway configured and tested
- Fraud detection: Manual review queue ready if service degrades
- Shipping calculation: Static rate tables if API fails
- Tax calculation: Pre-calculated rates by region
Draft customer communication templates in advance. Pre-approve the exact wording with legal and marketing so when your payment gateway goes down, you're updating your status page in 60 seconds, not scheduling an approval meeting.
Managing customer-facing outages when every second costs revenue
When production breaks during a flash sale, your team has one job: restore service. Not find root cause. Not write perfect post-mortems. Restore service, then learn.
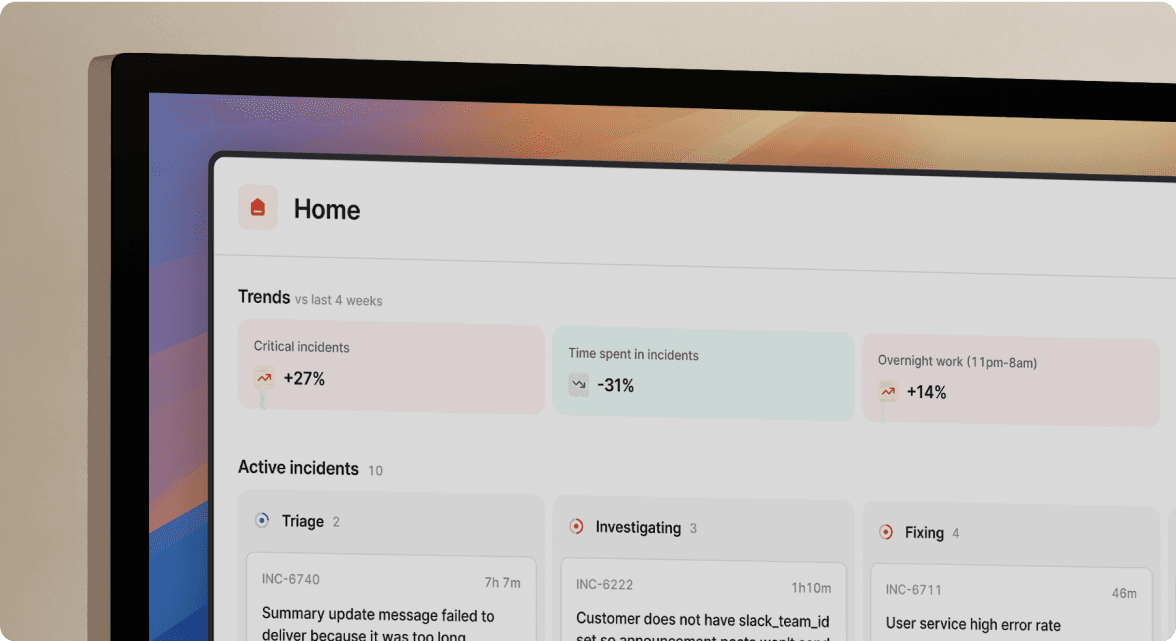
Detection to assembly in under 2 minutes
The typical incident response creates massive coordination overhead: checking PagerDuty to find who's on-call, opening Datadog for metrics, coordinating in Slack, taking notes in Google Docs, creating Jira tickets, and updating your status page. That's five tools and twelve minutes of logistics before troubleshooting starts.
Research on incident response shows that often the slowest part isn't the technical fix, it's coordination: getting approval to take action, informing stakeholders, or involving another team.
How we eliminate assembly time
When your Datadog alert fires for "Checkout API 95th percentile latency >3000ms," our Workflows automatically:
- Create dedicated Slack channel
#inc-2847-checkout-latency - Page on-call engineers from "Checkout Team" schedule
- Pull service context from our Catalog (owners, runbooks, recent deployments)
- Start timeline recording every message, role assignment, and decision
We assemble your team for troubleshooting in under 2 minutes. No manual channel creation. No hunting for on-call schedules. No asking "who owns this service?"
"incident.io is very easy to pick up and use out of the box... One of our pain points before we implemented incident.io was having to navigate multiple tools, however incident.io has solved that for us thanks to how well it integrates with other products." - Matthew B on G2
Triage and mitigation over investigation
During the active incident, Google SRE teams encourage a mitigation-first response. Your goal is stabilizing the service, not understanding why it broke. That comes later in the post-mortem.
Mitigation hierarchy for e-commerce:
- Roll back your last deployment (2-5 minutes if automated)
- Use feature flags to disable broken flows (1-3 minutes)
- Scale up infrastructure (3-10 minutes depending on auto-scaling)
- Implement manual overrides or workarounds (variable)
- Conduct full investigation and deploy proper fix (after you restore service)
During Black Friday, if rolling back the last deployment restores checkout functionality, do it. Don't spend 20 minutes debugging why the new code broke. Restore revenue flow, then investigate during the post-mortem.
As NIST incident response guidelines document, containment comes first, then eradication (finding root cause), then recovery (full restoration). The recovery phase can wait until after Black Friday if your mitigation is stable.
Communication is mitigation
Every minute your checkout is down, customers are opening support tickets: "Is your site working?" "My payment failed!" "Where's my order?" Support teams get overwhelmed, response times spike, and customer satisfaction plummets even after you fix the technical issue.
Updating your status page isn't an afterthought. It's active mitigation that stops thousands of duplicate tickets.
How our Status Pages work
From your incident Slack channel, you can update your public status page within seconds. Our customer status pages integrate directly into your incident workflow, so updating customers happens from Slack, not a separate login to another tool.
When you publish an incident to your status page, customers see:
- Acknowledgment that you're aware of the issue
- Current status (Investigating / Identified / Monitoring / Resolved)
- Affected services (Checkout / Account Login / Order History)
- Estimated resolution time (if known)
This transparency reduces support ticket volume by 40-60% during active incidents because customers can self-serve status information rather than contacting support.
For detailed setup, review the go-live checklist for your new status page to ensure you're ready before peak season.
Legal and compliance considerations
If your incident involves customer data (credit cards exposed, PII leaked, database breach), you're now in regulatory territory. GDPR Article 33 requires notification within 72 hours of becoming aware of a breach that risks individuals' rights. CCPA requires 30-day notification for consumers and 15 days for the Attorney General if 500+ California residents are affected.
Your incident response must include immediate containment to stop data exposure, evidence preservation by capturing logs for investigation, notification triggers with legal and security teams looped in immediately, and pre-approved breach notification language.
These timelines don't pause for Black Friday. Pre-document your compliance response process and assign explicit ownership to Security/CISO during peak season.
Key performance indicators for e-commerce reliability
Generic uptime percentages don't tell the story. A checkout service that's "99.9% available" sounds great until you realize that 0.1% downtime happened entirely during your Black Friday flash sale.
Revenue impact metrics
Track downtime cost per minute by calculating:
Average revenue per minute = (Q4 daily revenue) / (1440 minutes)
For example, if you do $500,000 in daily revenue during Q4, that's $347 per minute. A 30-minute checkout outage during Black Friday (when traffic is 10x normal) costs approximately $104,000 in lost revenue.
Use this number to justify reliability investments. If spending $50,000 on better incident management tooling reduces your average MTTR from 45 minutes to 28 minutes, you've saved 17 minutes per incident. That's $5,899 saved per incident during peak season.
Customer-centric incident KPIs
Cart abandonment rate spike: Your normal cart abandonment rate might be 65-70%. During a checkout incident, it spikes significantly. Track the abandonment rate increase specifically during the incident window to quantify customer impact.
Failed checkout attempts: Customers who reach the payment step but cannot complete. This is more precise than total cart abandonment because it isolates customers who intended to buy but couldn't.
Support ticket volume spike: Correlate support ticket timestamps with incident timelines. If tickets spike by 300% during the incident, that's quantifiable impact on support teams and customer satisfaction.
Post-incident conversion recovery: How long does it take for checkout conversion rate to return to baseline after resolution? If customers are still hesitant 2 hours after you fix the issue, your status page communication wasn't effective.
Understanding the abandoned cart value gives you the full picture of revenue impact, showing whether you have a small number of high-value carts abandoned or many low-value carts.
Operational metrics
Mean Time To Resolution (MTTR): Total time from alert firing to incident resolved. Target: reduce quarter-over-quarter by tracking in your insights dashboard.
Mean Time To Assembly: Time from alert firing to all required responders present in incident channel. This isolates coordination overhead from technical troubleshooting. Target: under 2 minutes.
Timeline capture completeness: Percentage of incidents with complete, automated timelines requiring minimal manual reconstruction. Target: 100% for SEV1/SEV2 incidents.
Post-mortem publishing speed: Days from incident resolution to published post-mortem with action items. Target: under 24 hours for customer-facing incidents.
Best incident management tools for e-commerce and retail
Your incident management stack should optimize for speed and cognitive load reduction, not feature counts. When your checkout service is down and you're losing $10,000 per minute, you need tools that disappear into your workflow.
Evaluation criteria for retail incident management
Slack or Microsoft Teams native: Your team already lives in Slack. Tools that bolt chat onto a web UI add context-switching overhead. Look for platforms where the incident entirely happens in chat using slash commands.
Automated coordination: Creating channels, paging on-call, pulling in service owners, starting timelines should require zero manual steps. Every manual step is cognitive load during high-stress moments.
Integrated status pages: Updating customers shouldn't require logging into a separate tool. Status updates should be simple commands in your incident channel.
Service catalog awareness: The tool should know who owns the "Checkout API" and surface runbooks, on-call schedules, and recent deployments automatically.
Timeline auto-capture: Every Slack message, role assignment, and decision should record automatically, not require a dedicated note-taker.
incident.io for e-commerce coordination
We position as the coordination and communication layer, not a replacement for monitoring. You keep Datadog, Prometheus, or New Relic for observability. We handle what happens after the alert fires.
Our key capabilities:
- Workflows that automate incident declaration, channel creation, and team assembly based on which service is affected
- Catalog integration surfacing service owners, dependencies, and runbooks instantly
- Status pages updated from Slack directly from your incident channel
- AI Scribe transcribing incident calls and auto-drafting post-mortems from captured timelines
Intercom migrated from PagerDuty and Atlassian Status Page to incident.io in a matter of weeks, consolidating their incident stack into a single Slack-native platform.
"When we were looking for a tool to improve the experience for both our incident response teams as well as for communicating effectively with management, incident.io came through on both counts... Integrating with the multiple other cloud services that we use was straightforward and intuitive." - Verified User on G2
Pricing: Pro plan at $45/user/month total ($25 base + $20 on-call) adds Microsoft Teams support, unlimited workflows, and AI-powered post-mortem generation.
How PagerDuty fits
PagerDuty excels at alerting, on-call scheduling, and escalation policies. It's battle-tested for waking up the right person. Where it struggles is coordination. PagerDuty sends a Slack notification with a link. Clicking opens PagerDuty's web UI. You manage the incident there, then manually update Slack, Jira, and your status page.
For retail teams, this means:
- Strengths: Reliable alerting, robust escalation policies, mature mobile app
- Weaknesses: Coordination happens outside Slack, timelines live in PagerDuty while conversation lives in Slack (two sources of truth), status page updates require separate tool
Many teams use both: PagerDuty for alerting, incident.io for coordination. Netflix uses incident.io to power their incident management while maintaining integrations with their existing monitoring stack.
Comparison table
| Capability | incident.io | PagerDuty | Jira Service Management |
|---|---|---|---|
| Slack-native workflow | ✓ Entire incident in Slack | ✗ Web UI with Slack notifications | ✗ Ticket-based, minimal Slack |
| Automated timeline capture | ✓ Every message, decision recorded | ~ Timeline in web UI only | ✗ Manual ticket updates |
| Status page integration | ✓ Update from incident channel | Separate Statuspage.io login | ✗ No native status pages |
| Pricing transparency | ✓ $31-45/user/month all-in | ~ Complex tier + add-ons | ~ Quote-based enterprise |
| Best for | Coordination & communication | Alerting & escalation | Enterprise ITSM workflows |
Building a resilient e-commerce incident response team
Tools enable speed. People determine whether your team handles Black Friday incidents with confidence or panic.
Essential roles during high-stakes incidents
Incident Commander (Incident Lead): The only essential role for all incidents, set as soon as possible. The commander directs response, sets objectives, and makes final decisions. During Black Friday, this person should ask questions and prioritize, not type commands.
As Rootly's guide to incident commanders notes, this is the single accountable leader who ensures safe and timely return to normal operations.
Communications Lead: For high-severity incidents affecting customers, handling communications must be delegated away from the Incident Commander. Responsibilities include deciding update cadence, monitoring who knows what, and writing status page updates while the commander focuses on technical response.
Scribe: Documentation is critical, and the scribe records information as incidents unfold, helping generate post-mortem reports. For teams using incident.io, our AI Scribe feature automates this by transcribing incident calls and capturing key decisions without requiring a human dedicated to note-taking.
Why these matter during Black Friday: When 50,000 customers are trying to check out and your database is timing out, resist co-leadership. Clear role delegation prevents engineers from trying to code, communicate, and document simultaneously. One person troubleshoots, one person updates executives, one person captures decisions.
"incident.io helps promote a blameless incident culture by promoting clearly defined roles and helping show that dealing with an incident is a collective responsibility. We have also started using it to conduct game days, so that we can better prepare for a catastrophic scenario." - Saurav C on G2
Training and onboarding for on-call
New engineers need to participate in incidents without weeks of runbook memorization. Slash commands like /inc escalate or /inc role are intuitive. Service context surfaces automatically. This reduces on-call readiness significantly compared to traditional tools.
Run training game days monthly, not just before Black Friday. Simulate incidents where junior engineers take Incident Commander role with senior engineers observing. The goal is building muscle memory so response feels natural during actual incidents.
Post-mortems and the learning loop
Post-mortems identify root causes beyond what happened to understand why it happened. For retail incidents, focus on:
- What was the customer impact? (lost revenue, failed transactions, support tickets)
- What was the mitigation? (rollback, feature flag, scale-up)
- Why did detection take X minutes? (alert tuning needed?)
- Why did assembly take X minutes? (coordination overhead?)
- What prevents recurrence? (architectural change, better testing, improved runbooks)
Our AI auto-drafts post-mortems using captured timeline data, call transcriptions, and key decisions. This significantly reduces the time spent on post-incident documentation compared to manual reconstruction.
Surviving peak traffic requires coordination, not just infrastructure
Black Friday will break something. Maybe it's a database connection pool exhaustion. Maybe it's a third-party payment gateway timing out. Maybe it's traffic 15x higher than your load tests predicted.
The difference between a 10-minute outage and a 45-minute outage isn't usually the technical fix. It's how fast you assembled the team, made decisions, and communicated with customers. Research shows coordination overhead often consumes more time than the actual repair work.
Use the months before peak season to:
- Test your incident response process with Game Days that simulate Black Friday pressure
- Eliminate manual coordination steps by automating channel creation, on-call paging, and status updates
- Pre-document failure scenarios with WCGW exercises and assign clear ownership
- Consolidate tools so your team isn't toggling between five tabs during incidents
We built incident.io to solve the coordination tax problem. Reliability is a feature, and the tools you choose determine whether Black Friday becomes a revenue record or a post-mortem filled with "we couldn't find the runbook" explanations.
Ready to test your incident response before Black Friday? Book incident.io for a free demo and set up your first automated workflow, or book a free demo to see how teams handle peak traffic incidents in Slack.
Key terminology
MTTR (Mean Time To Resolution): Total elapsed time from when an incident is detected until it's fully resolved and normal service is restored. Measured in minutes for high-severity customer-facing incidents.
Game Day: Controlled chaos engineering exercise where teams intentionally inject failures into production-like environments to test both system resilience and team coordination under realistic incident pressure.
Code Freeze: Predetermined period before high-traffic events where teams prohibit feature deployments and limit changes to critical security patches only. Reduces risk of introducing bugs during peak revenue periods.
Incident Commander: Single accountable leader who directs incident response, sets priorities, makes decisions, and ensures coordination across technical and communication teams. Does not personally perform hands-on troubleshooting.
Mitigation-First Response: Incident management approach prioritizing rapid service restoration through rollbacks or workarounds over thorough root cause investigation. Defers detailed analysis to post-incident review after customer impact is eliminated.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

