Build custom API integrations with incident.io

We’re building incident.io as the single place you turn to when things go wrong. When an issue is disrupting your business-as-usual, the last thing you want is to start opening ten different tools to diagnose and fix it!
As your central incident hub, we need to give you two powers:
- Replicating (and possibly automating) your existing processes in incident.io; and
- Keeping incident.io in sync with your existing tool stack.
Workflows cover the former. Workflows are like a mini incident.io Zapier. You can use them to tell us when to page teammates, send updates to your affected customers and other stakeholders, assign roles and to-dos, and infinitely more.
What about the latter? We already offer a catalogue of native integrations with on-call solutions (PagerDuty, OpsGenie), issue trackers (e.g. Jira, Linear, GitHub) and communications tools (Statuspage; Zoom; GMeet). We’ll continue adding more as we grow: from Datadog or Zendesk to let you declare incidents from those tools; to Backstage or Terraform to sync your service catalog into incident.io.
Today though, we are stepping up our connectedness game by launching the incident.io API!
Check out the API reference, or read on to see how our early-access customers have used it.
Why would I need the API?
Native integrations are a beautiful thing. They are easy to set up, even for non-technical teammates. Sales, Customer Support, BizOps - anyone can plug in their suite of tools without a line of code. They are faster to implement and reduce the need for maintenance on our customers’ side.
However, integrations also have their downfalls. Firstly, they must be built separately for every tool. We are known to ship at the speed of light, but there are a lot of tools that our customers use - in their engineering teams, and beyond. This means you might have to wait a few months before we integrate natively with that one tool you need.
Moreover, native integrations have a smaller surface area. They could cover 80% of use cases, and fall short on the outstanding 20%. You might be looking for a functionality that’s very specific to your team or company. Or that we simply haven’t got round to building yet.
The API is the answer to both those issues.
What does the incident.io API do?
At the highest level, our API lets you connect incident.io to any tool in your stack (or even to your own application), and give us instructions via that connection. No more waiting around for that one integration you need, and no more constraints on what you can do: the API world is your oyster!
It’s worth noting at this point that the first version of our API focuses on the three major use cases, namely:
- Automatically creating an incident from another system, such as a monitoring tool like Datadog or a ticketing system like Zendesk - see our step-by-step example below
- Exporting incidents and their to-dos (i.e. Actions and Follow-Ups) into a data warehouse or BI tool (Looker, Tableau etc.) to analyse.
- Configuring roles, severities, and custom fields from an external data source like Terraform or your service catalog
We picked these three because they were the most requested by our existing users, and we wanted to stay focussed on laying solid foundations while building quickly.
Needless to say though, we’ll be extending this over time, so we’d love to hear what you’d like to use our API for!
Step-by-step example: declaring an incident from Zendesk
Most of our users have a ticketing system like Zendesk to manage their customer support. Inbound tickets are triaged by customer support teammates, and escalated to the engineering teams based on specific criteria (e.g. a certain severity, or a particular incident type such as data breaches).
In a pre-API world, things could get a little painful to execute that escalation policy. Support team members would have to exit Zendesk. Then head to Slack to manually declare an incident (and remember to append the Zendesk ticket link). We’d work our magic at the point of declaration, and downstream of it.
In a post-API world, we can add value upstream of the declaration point too: a support agent can declare an incident with one click, straight from within Zendesk. We’ll take care of the rest, from declaring the incident in incident.io to pulling in the right teammates, notifying the relevant internal and external stakeholders, spinning up your public Statuspage and much more.
Here are the few key steps to bringing this flow to life.
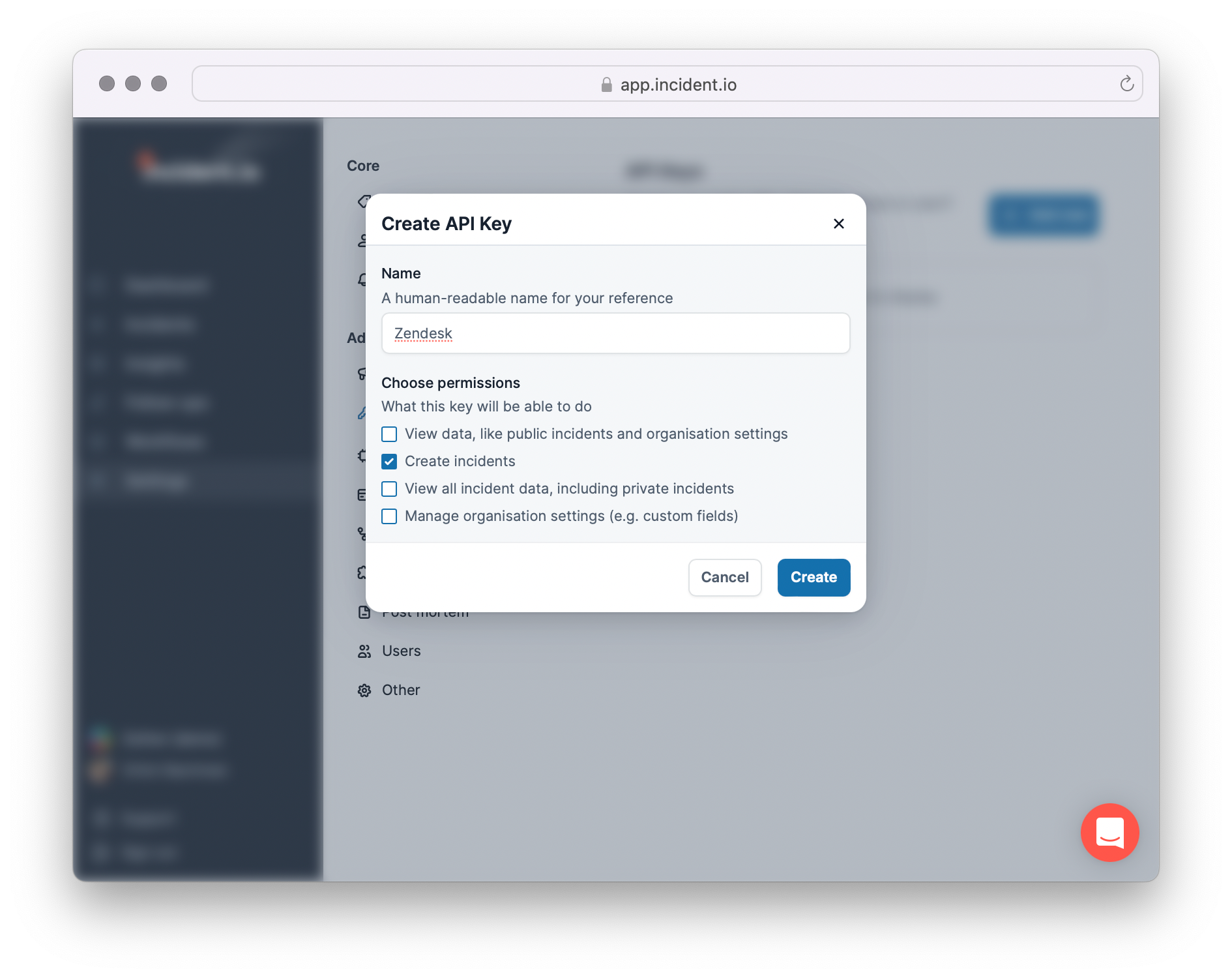
1️⃣ Generate an API Key in incident.io
You’ll want to generate a key with Create incidents enabled. Keep this safe - we’ll need it in a minute.
2️⃣ Configure a Zendesk Support trigger
This lets you choose when Zendesk should escalate a ticket. In this case, we might use a checkbox custom field, which will declare an incident when it’s ticked.
3️⃣ Add a Zendesk webhook as the action to take when the trigger fires
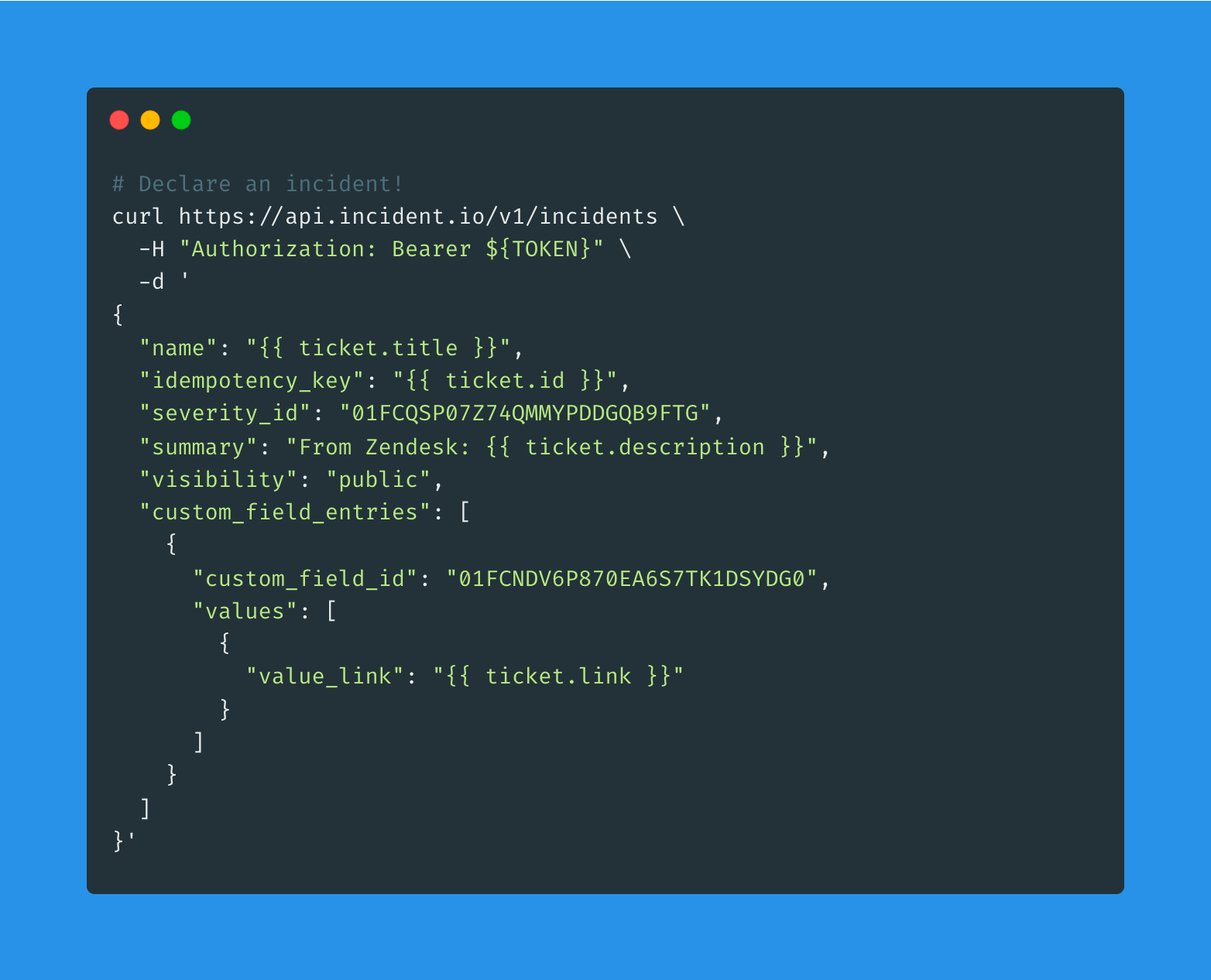
Configure it to make an HTTP POST request to https://api.incident.io/v1/incidents. The API Key we generated earlier is used for Bearer token authentication. The request body needs to be JSON that looks like:
{
"name": "{{ ticket.title }}",
"idempotency_key": "{{ ticket.id }}",
"severity_id": "01FCQSP07Z74QMMYPDDGQB9FTG",
"summary": "From Zendesk: {{ ticket.description }}",
"visibility": "public",
"custom_field_entries": [
{
"custom_field_id": "01FCNDV6P870EA6S7TK1DSYDG0",
"values": [
{
"value_link": "{{ ticket.link }}"
}
]
}
]
}
There’s a couple of special IDs in there you’ll need:
- The
custom_field_idreferences a “Zendesk Ticket Link” custom field we’ve configured. You can find the IDs of your custom fields using the List Custom Fields API. - The
severity_idreferences our “Minor” severity. You can find the IDs of your severities using the List Severities API.
That’s it! 🎉 Whenever that trigger fires, you’ll get a new incident declared in incident.io. Nice.
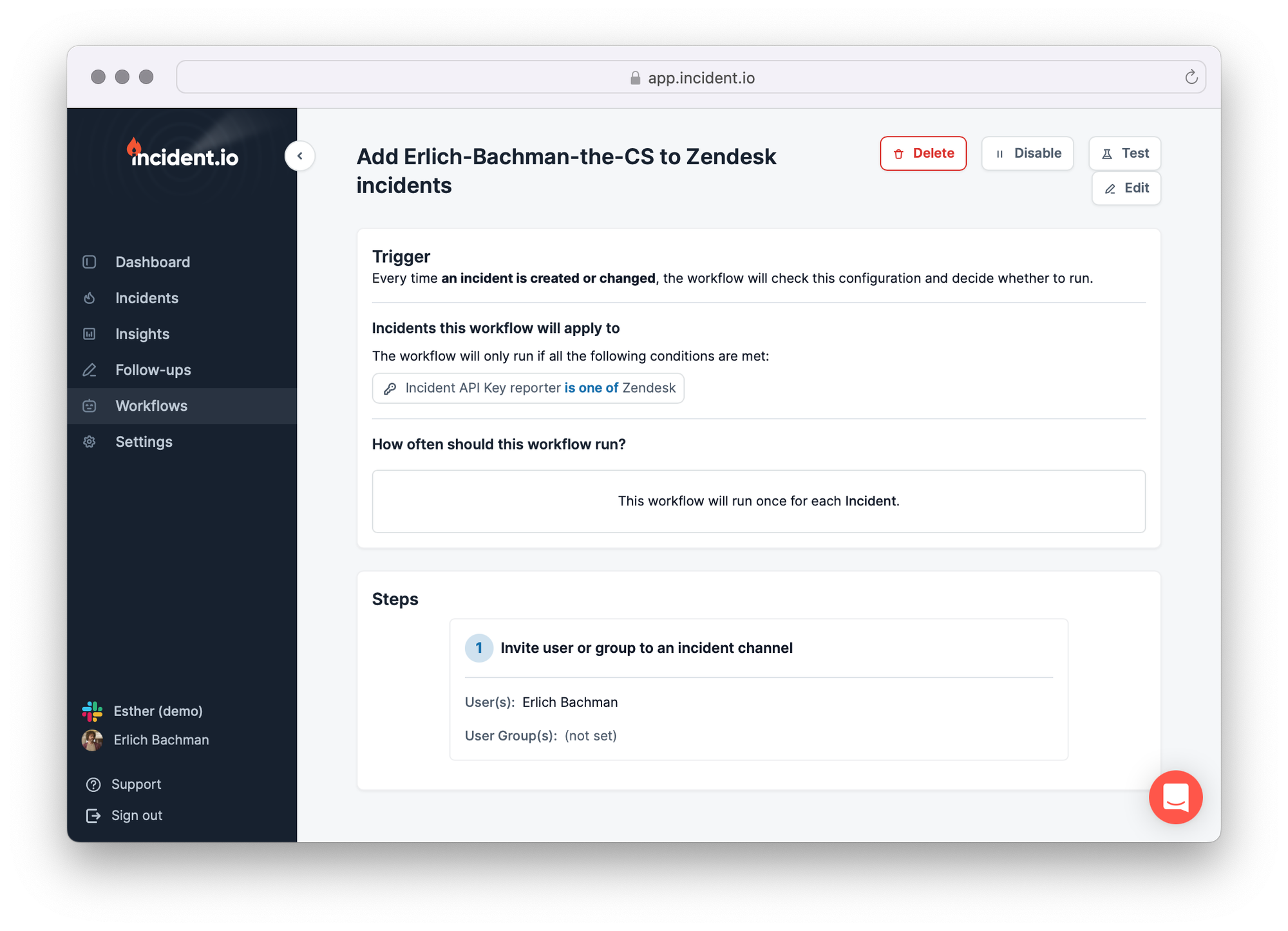
As a bonus: you can configure workflows that only run on your API-generated incidents. For example, you could build a workflow that automatically adds the support agent that declared the incident in Zendesk to the incident’s Slack channel.
To do that, add a Condition based on the API Key that reported the incident. This would look like:
How we built the API
The API for declaring an incident is as permissive as possible: if something’s going wrong, it’s better that an incident is declared with some missing context than not declared at all. This means that required custom fields won’t be enforced, for example.
We also wanted to avoid accidental spam. If things are going wrong in the middle of the night, the last thing you need is 5 incidents with reminders pinging around. To create an incident with the API, you must specify a unique key which we can deduplicate on. That might be the ID of an alert firing, or the reference for a support ticket. We’ll only create one incident for each key, so you don’t have to worry about waking up to more incident channels than necessary.
Over to you!
We built our API around these three use-cases for now, but we’ll keep expanding it over the coming weeks.
We’d absolutely love to hear what you build with it, and how you’d like us to extend it.
There’s an #api channel in the incident.io Community. See you there 👀

See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom Wentworth
De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn Carman
Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherSo good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

