2026 buyer’s guide: Top on‑call scheduling tools every team needs
January 5, 2026 — 12 min read
Choosing the right on-call software comes down to fit: your stack, your coverage model, and how much automation you need to reduce alert fatigue and speed response. In 2026, top tools pair reliable alerting with flexible on-call rotation models, clear escalation policies, and deep integrations across chat, monitoring, and ticketing. This guide compares leading options, explains what really matters in evaluation, and offers a step-by-step buying process. Short answer to “What’s the best on-call tool?” It depends: incident.io is a standout for engineering teams living in Slack or Teams and wanting AI-driven workflows; Grafana OnCall shines if you’re all-in on Grafana; Better Stack is great for startups; and sector-specific tools like Hypercare serve clinical environments.
incident.io
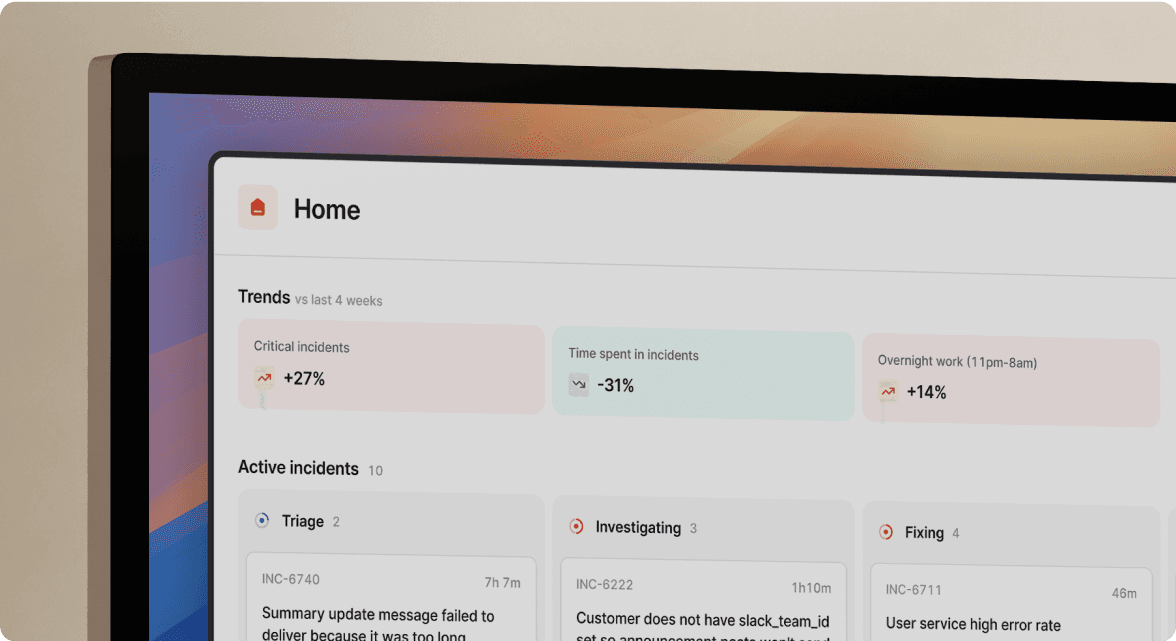
incident.io is a Slack-native incident management and on-call scheduling platform built for engineering teams that want streamlined workflows where they already collaborate. It combines on-call scheduling, incident response, and AI-driven automation in Slack and Microsoft Teams, with 50+ integrations across monitoring, ticketing, and cloud. “On-call scheduling software automates the assignment of primary and secondary responders for incidents, ensuring predictable coverage and fast response across time zones.”
Why engineering orgs choose incident.io:
- AI depth out of the box: catalog-driven alert routing, an SRE assistant for triage, automated post-mortems, and continuous learning that improves with every incident.
- Flexible configuration without heavy setup: policy-driven rotations, overrides, and multi-team schedules that adapt as you scale.
- Alert fatigue reduction: intelligent routing, noise suppression, and escalation logic tuned to your SLAs.
- Broad ecosystem fit: webhook-friendly, supporting key tools used by SRE, DevOps, and platform teams.
Explore on-call in detail and see schedule examples in the incident.io On-Call guide: incident.io On-Call. For program design, our field-tested playbook covers patterns that prevent burnout: The ultimate guide to on-call schedules.
Better Stack
Better Stack is a lightweight, monitoring-forward on-call solution suited to startups and small teams that prioritize simplicity and quick setup. It works well for basic alerting and rotations, but teams often outgrow its policy customization, advanced escalation, and reporting.
Comparison at a glance:
| Option | Best for | Pros | Cons | Rough pricing signal |
|---|---|---|---|---|
| Better Stack | Startups, small teams | Easy setup, built-in uptime/monitoring, clean UI | Limited advanced policies and analytics vs. enterprise tools | Transparent, startup-friendly; free tier often available |
| Full-featured alternatives (e.g., incident.io, Splunk OnCall) | Mid-size to enterprise | Deep policies, automation, analytics, wide integrations | More configuration, higher per-seat cost | Mid-to-high per-user, varies by tier |
Grafana OnCall
Grafana OnCall is the natural choice for teams already invested in Grafana dashboards and alerting. Its data-native approach links alert details, visualization, and on-call handoff so responders can move from signal to action quickly. For SRE and DevOps workflows, this tight coupling reduces context switching and shortens triage. The trade-off: if your stack isn’t Grafana-centric, you may find less flexibility and more lift to integrate equivalent context from other observability tools.
Splunk OnCall
Splunk OnCall (the evolution of VictorOps) blends incident collaboration with observability context, making it strong for teams with a heavy monitoring footprint.
Core features:
- Alert aggregation and routing with rich context
- Real-time collaboration, timelines, and incident channels
- Robust reporting and analytics, alongside post-incident insights
- Broad integrations across monitoring, chat, and ticketing
Best fit for teams that want contextual timelines and triage workflows closely tied to observability platforms.
Zenduty
Zenduty offers advanced escalation logic and conditional routing at a budget-friendly entry point, making it attractive to engineering teams that need power without enterprise pricing. Entry tiers start around $5 per user per month, with flexible workflows and customized handoffs via conditional policies (as summarized in Connecteam’s comparative roundup).
Feature and price snapshot:
| Platform | Standout strengths | Best for | Entry-level pricing signal |
|---|---|---|---|
| Zenduty | Advanced escalation logic, conditional routing, affordable tiers | Cost-conscious engineering teams | ~$5/user/mo |
| incident.io | Slack/Teams-native, AI-driven workflows, end-to-end incident management | High-velocity engineering orgs | Varies by tier |
| Grafana OnCall | Deep Grafana integration, data-native alerting | Teams on Grafana Cloud | Included in Grafana tiers/free for small teams |
| Splunk OnCall | Collaboration + observability context, analytics | Monitoring-heavy orgs | Quote-based |
OnPage
OnPage focuses on guaranteed alert delivery—ideal when missed pages are unacceptable. Alert delivery guarantees mean reliable notifications with confirmations and persistent reminders until acknowledgment. It’s a strong fit for IT operations and regulated environments needing coverage guarantees and delivery metrics. Expect major integrations like Slack and Jira, and pricing around $13.99 per user per month in entry tiers (based on comparative listings from Connecteam’s 2024 roundup).
Connecteam
Connecteam is a top-rated, all-in-one scheduling platform whose capabilities extend beyond incidents—think PTO, shift swaps, team chat, and a polished mobile-first experience. It’s frequently ranked at or near the top in on-call tool roundups and remains a strong generalist option in 2026, with a free plan and flexible paid tiers geared toward broader workforce management. See pricing signals and comparisons in Connecteam’s 2024 roundup.
Hypercare / Amtelco
Healthcare and other regulated industries often need HIPAA-compliant clinical scheduling with guarded messaging and complex department coverage. Hypercare emphasizes secure team notifications and earns high user ratings (around 4.7/5 in public roundups), while Amtelco focuses on large, multi-department clinical operations. These tools are purpose-built for clinical settings; most tech and SRE teams will be better served by platforms designed for engineering workflows.
Key features to look for in on-call scheduling tools
Across industry comparisons, five weighted factors consistently determine the best on-call scheduling software for engineering teams: core scheduling, escalation logic, integrations, security and compliance, and performance and reliability, according to a cross-vendor feature comparison.
Must-have checklist for technical operations:
| Capability | Why it matters | What “good” looks like |
|---|---|---|
| Scheduling & rotations | Ensures predictable, fair coverage across time zones | Templates, overrides, PTO handling, calendar export, mobile management |
| Escalation logic | Gets the right responder quickly, reduces MTTA | Conditional routing, time-based & severity-based policies, fallback chains |
| Integrations | Brings context into the responder’s flow | Slack/Teams, Grafana/Datadog, Jira/ServiceNow, cloud/webhooks |
| Security & compliance | Protects sensitive data and meets regulatory needs | SSO/SAML, RBAC, audit logs, data residency options |
| Performance & reliability | Delivers alerts promptly and persistently | Delivery receipts, multi-channel notifications, SLA metrics |
| Reporting & analytics | Drives continuous improvement | MTTA/MTTR, alert volume/noise ratio, team load reports |
Scheduling and rotation management essentials
On-call scheduling is the backbone of on-call. You need rotational templates, one-click PTO/shift swaps, calendar export, and straightforward override management—especially for globally distributed teams. Flexible, policy-driven engines prevent last-minute gaps and burnout.
Example: setting up a rotation
- Add responders and define time zones and working hours.
- Create a weekly rotation with primary and secondary engineers.
- Configure escalation logic for unacknowledged alerts at 5 and 10 minutes.
- Connect PTO calendars; set auto-backfill and approve shift swaps in-app.
- Add temporary overrides for holidays, with auto-revert after the period.
- Export to Google/Outlook calendars and confirm mobile push/SMS availability.
For deeper patterns and fairness models, see our field guide: The ultimate guide to on-call schedules.
Reliable alerting and escalation policies
Alert reliability is the system’s ability to deliver notifications promptly and persistently to assigned staff, with confirmations and fallback channels. Fast, automated escalation chains preserve on-call SLAs and reduce mean time to acknowledge.
A typical flow:
- Initial alert: route to primary on-call with push/SMS/call.
- Escalation: re-page primary, then route to secondary or duty manager on timeout.
- Acknowledgment: capture who/when, lock further escalation.
- Resolution: track status changes, incident notes, and timelines for post-incident review.
- Delivery metrics: monitor success/latency per channel to tune policies.
Integrations with collaboration and monitoring platforms
Integration breadth — a key dimension in any on-call tool selection framework — determines how seamlessly alerts, statuses, and context flow across your stack. In-platform context accelerates triage and supports alert fatigue prevention: pairing monitoring alerts with chat-first incident coordination reduces switches between dashboards and communications.
Critical integrations to verify:
- Monitoring/observability: Grafana, Datadog, Prometheus, CloudWatch
- Chat/collaboration: Slack, Microsoft Teams
- Ticketing/ITSM: Jira, ServiceNow, GitHub/GitLab issues
- Calendars/identity: Google/Outlook, Okta/Azure AD
- Cloud/webhooks: AWS, GCP, Azure, generic webhooks
Compliance and industry-specific requirements
In sensitive sectors, compliance is non-negotiable. For healthcare, HIPAA-compliant scheduling ensures protected health information is accessible only to authorized staff, with encryption and audited access. Financial services may emphasize data residency, audit trails, and granular RBAC.
Industry fit matrix:
| Platform | Best-fit industries | Compliance focus (typical) |
|---|---|---|
| incident.io | Tech/SaaS, platform/SRE | SSO/SAML, RBAC, audit logs; evaluate SOC 2/ISO controls per tier |
| Better Stack | Startups, SMB tech | Basic security, cloud hosting controls |
| Grafana OnCall | Teams on Grafana Cloud | Cloud security controls aligned to Grafana tiers |
| Splunk OnCall | Enterprises with observability programs | Enterprise identity, audit, integrations |
| Zenduty | Cost-conscious engineering teams | SSO options, audit logs on higher tiers |
| OnPage | Regulated IT ops | Delivery assurance, auditability |
| Hypercare / Amtelco | Healthcare/clinical | HIPAA-ready clinical messaging and scheduling |
Pricing models and cost considerations
Most on-call platforms use per-user or per-seat pricing with features bundled by tier; that’s broadly consistent with scheduling software patterns summarized in Workyard’s pricing primers on scheduling platforms. Real-world signals from comparative roundups show entry tiers like Zenduty at roughly $5/user/month, OnPage at $13.99/user/month, and Hypercare from $7/user/month; free plans or trials are common for smaller teams (see Connecteam’s 2024 roundup).
Sample pricing snapshot:
| Platform | Pricing signal | Free plan/trial | Entry-tier highlights |
|---|---|---|---|
| incident.io | Varies by tier | Trial available | On-call + incident management, Slack/Teams native |
| Better Stack | Startup-friendly | Often available | Basic rotations, monitoring + alerting |
| Grafana OnCall | Included in Grafana tiers; free for small teams | Yes | Data-native alerting with Grafana dashboards |
| Splunk OnCall | Quote-based | Trial available | Collaboration timelines, analytics |
| Zenduty | ~$5/user/month | Trial available | Advanced escalation, conditional routing |
| OnPage | $13.99/user/month | Trial available | Guaranteed delivery, audit trails |
| Hypercare | From ~$7/user/month | Trial available | HIPAA-compliant clinical scheduling |
| Connecteam | Free plan + paid tiers | Yes | Broad workforce scheduling, mobile-first |
How to choose the right on-call scheduling tool for your team
- Define your on-call SLAs: acknowledgment and response targets, coverage hours, and on-call load limits.
- Map coverage needs: teams, rotations, time zones, holidays, and escalation ownership.
- Validate alert delivery: guarantees, channel redundancy, delivery metrics, and latency under load.
- Check integration fit: chat, monitoring, ticketing, identity, and calendars you rely on.
- Assess policy flexibility: conditional routing, multi-team escalations, overrides, and failover.
- Evaluate onboarding complexity: setup effort, role-based access, mobile readiness, and training needs.
- Pilot with real alerts: measure setup time, alert latency, MTTA, and stakeholder satisfaction; pressure-test for future growth.
Industry comparisons tend to weight scheduling, escalation, integrations, security, and performance most heavily—use that as your scoring backbone (see the cotocus feature comparison linked earlier).
Quick buying checklist for effective on-call management
- Reliable, multi-channel alert delivery with metrics and receipts
- Policy-driven escalations, conditional routing, and clear fallbacks
- Integrations: Slack/Teams, Grafana/Datadog, Jira/ServiceNow, calendars
- Security: SSO/SAML, RBAC, audit logs; industry compliance needs
- Cost fit: per-user tiers, included features, free plan/trial availability
- Onboarding: intuitive UI, mobile app quality, schedule/override ease
- Reporting: MTTA/MTTR, noise reduction, team load and coverage gaps
- Run a time-boxed pilot; verify incident timelines, handoffs, and post-mortems
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

