Services are not special: Why Catalog is not just another service catalog
June 29, 2023 — 6 min read

As you may have already seen, we’ve recently released a Catalog feature at incident.io. While designing and building it, we took an approach that’s a tangible departure from a traditional service catalog.
Here’s how we’re different, and why.
What is a traditional service catalog, and what’s in it?
A service catalog enumerates the various services your organization provides. It also houses some auxiliary information that categorizes them (for example, which team owns each service or whether it has upstream dependencies). The way we see it, this approach misses some key things we wanted from our Catalog.
Service catalogs have a limited scope
Traditional service catalogs tend to be engineering-focused and are often used to power an internal developer platform.
Services are the first-class entity, and the catalog typically enumerates the APIs and infrastructure associated with each of them. This makes for quite a narrow view of your organization. Your customers and the people responsible for them are notably absent, despite being critical components of both your business and your approach to incident response.
Service catalogs are often rigidly structured
Most service catalogs depend on a pre-existing idea of what the data they will be housing will look like. If you think about your organization differently, you’re stuck with a best-effort mapping from your abstractions to those defined by the system.
How is Catalog different?
Our catalog is a connected, navigable map of things. It diverges from a traditional service catalog in three ways:
More than just services
When we say everything, we mean all facets of your organization: teams, groups of teams, software services, product functionalities, infrastructure components, customers, escalation policies, or ticketing systems. Anything.
To facilitate this, Catalog makes zero assumptions about how you model your organization: you're never going to run into the painful experience of trying to fit the square-shaped model of your org into the triangular-shaped template of your service catalog.
So what do you do with your existing service catalog? Fear not. We’ve got you covered. We can import your existing data from almost anywhere, so you won’t lose your carefully configured services and components. We’re not trying to be another source of truth. On the contrary…
We are the glue between all of your other tools
You can connect incident.io to your observability tools, escalators, bug and issue trackers, post-mortem document providers, and status pages. When you install any of these integrations, we will automatically import the data from these tools into Catalog.
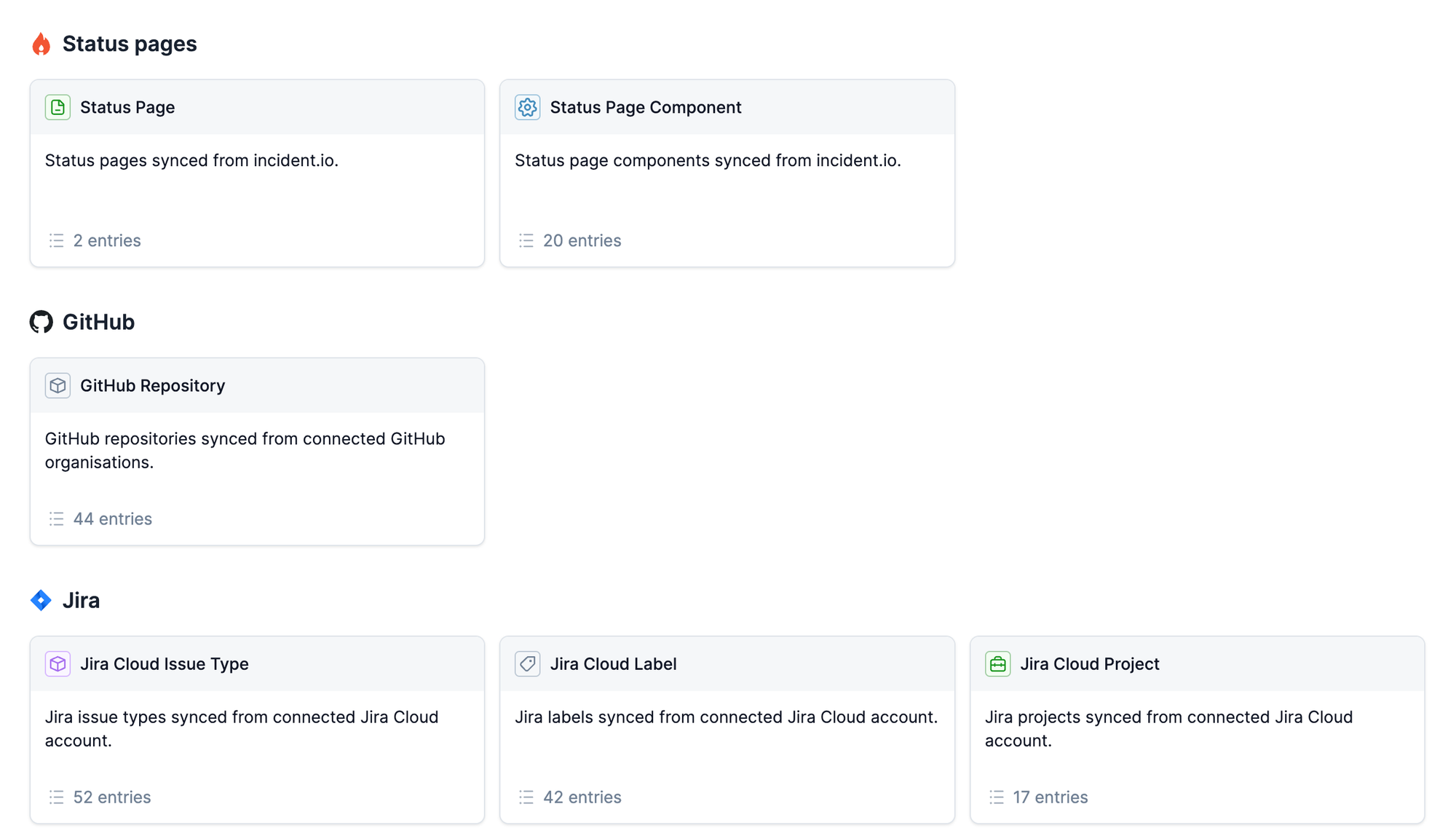
Your Catalog now contains escalation policies you can link to services, Slack channels you can assign to teams, and status page components for your features, without you lifting a finger.
You can model all the relationships between the components of your organization
Not only can Catalog be populated with completely custom types, allowing you to model your organization however you like, but those types can also be connected in arbitrary ways: any type, custom or otherwise, can reference any other.
This results in an incredibly rich, interconnected view of your organization, which becomes even more powerful because...
Catalog is deeply connected to every other part of incident.io
In isolation, the catalog is an insightful birds-eye view of how every facet of your organization fits together. Plugged into the rest of the app, it's rocket fuel for your automations. Let’s start by looking at how it can improve your use of custom fields.
Catalog-backed Custom Field options
Custom Fields provide triggers for workflows while an incident is active, and insights into your organization’s health when incidents are closed. To facilitate this, they need to be set consistently and accurately, which is only possible if they have consistent and accurate options.
When creating a Custom Field, you can populate its options using a catalog type. This ensures its options will always be correct, consistent, and up-to-date; if your entries change, they will too.

Automatically populated Custom Fields
Requiring responders to correctly set custom fields in the heat of the moment introduces cognitive load at the worst possible time, not to mention the incident reporter may not know what the values ought to be:
Which CSM is responsible for this customer? Who owns this affected feature?
Derived Custom Fields leverage the navigability of Catalog to automate this entirely. An incident reporter can set a field like affected customers, and have the correct values cascade to responsible CSMs without any further action on their part.
This automation also has the affect of lowering the barrier to entry, having confidence fields like affected services and responsible team are going to be set correctly makes declaring incidents a much less daunting prospect for non-technical folks.
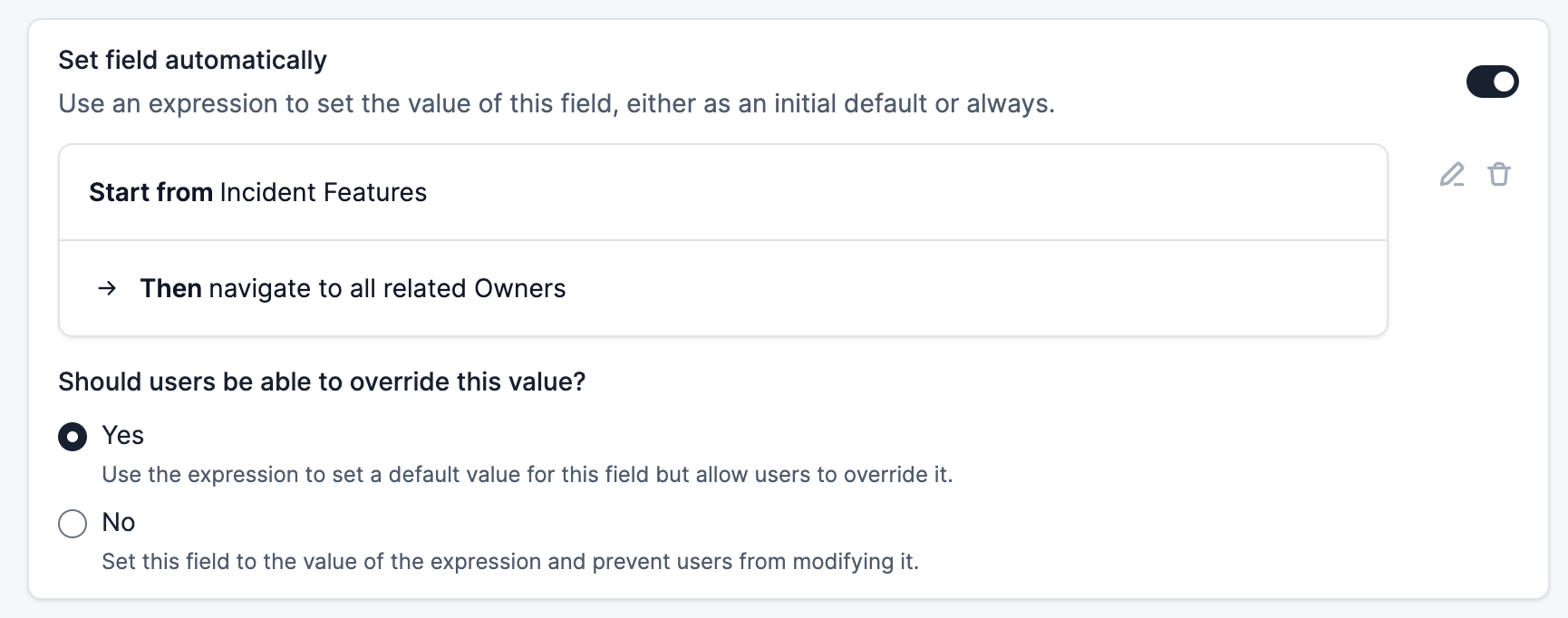
More powerful Workflows
The navigability of Catalog allows these custom fields to drive a variety of powerful automations that would be impossible otherwise. For instance, you could start from an incident’s affected customers, filter them to a specific support tier, find all the relevant CSMs and then send them a message notifying them one of their customers had been affected.

Wrapping up
If you’re already using a service catalog solution, we’re not trying to convince you to abandon it: far from it!
But a service catalog is just one piece of the puzzle. Catalog is built to be a mirror of your existing sources of truth, from service catalogs to CRMs, and combine them to produce magic ✨.

Benji Sidi
Product Engineer
See related articles

Announcing Catalog – the connected map of everything in your organization
Build a connected map of everything that exists in your organization that you can easily navigate and which is available across features like Workflows, Insights, and Triggers to level up your incident response.
 Chris Evans
Chris EvansJune 29, 2023

How our product team use Catalog
In the process of building Catalog, we’ve also been building out the content of our own catalog. This post explains how our product team uses our catalog to store features, integrations, and teams and the powerful Workflows that unlock them all for us.
 Sam Starling
Sam StarlingJune 29, 2023
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


