How our product team use Catalog
June 29, 2023 — 11 min read

We recently introduced Catalog: the connected map of everything in your organization.
In the process of building Catalog as a feature, we’ve also been building out the content of our own catalog. We'd flipped on the feature flag to give ourselves early access, and as we went along, we used this to test out the various features that Catalog powers.
Perhaps you’re in a similar position to us, and you don’t have an existing catalog, but you do have a handful of disparate systems which contain data about your business.
In this post, I’ll explain how we took data about our features, integrations, and teams, imported them into our catalog, and used that to make our incident response process faster and smoother.
By the end, you'll have seen the various ways we import our data, and how we've used that data to create powerful new workflows.
Our use-case
Before we started, we actually didn’t have a catalog. That isn't particularly unusual for a company of our size, but it doesn't mean we didn't need one. By allowing us to join together all of these different systems and data sources, our catalog has allowed us to create some smart new Workflows and get a richer picture of our incidents within Insights.
Starting out, we knew that we had plenty of data that we could make better use of when responding to incidents. However, that data lived in various places outside of incident.io and wasn't always easy to connect.
But what kind of data are we talking about? Let's think about a few things we care about as a product engineering team:
- As a group shipping a product, it'd be good to know which parts are more failure-prone or which of our third-party integrations cause us the most trouble.
- We're also growing in size, so how do we ensure that our escalation paths end up in the right place and that we're pulling the right people into our incidents?
- How does someone in customer service know which PagerDuty escalation policy they want to escalate to?
- We're split into four teams now, and we'd also like to know how our humans are doing. Which teams experience the most pager load?
Until now, fixing these problems often meant adding more Custom Fields, each with a hand-crafted list of options. That's not ideal because it's a lot of manual work for the people maintaining the fields and the responders filling them in.
Getting our data in
The first step to solving these problems is to populate Catalog with the data we need. The main building blog of the catalog is types — let's walk through how we got all this data imported, type by type.
Our Importer tool is the easiest and most flexible way to import data into Catalog. It's powered by a configuration file that uses the Jsonnet syntax, and it's able to consume data in both JSON and YAML formats.
The importer works on the concept of pipelines, where each pipeline consists of sources and outputs, resulting in entries and types that appear within Catalog.
Features
Often, the first thing an engineering organization like ours wants to put into Catalog is its services. You might have read that we run a monolith, so we don't have a particularly strong concept of what a 'service' is.
Instead, we organize our codebase around features: these are aspects of our product that customers will recognize, like Insights or Workflows. These features act a lot like services: each one is owned by a team and powers some specific functionality.
We associate our incidents with features, and "Affected features" is one of our longest-standing Custom Fields. Before Catalog, it was a multi-select field to which anyone could add options. Over time, this list grew organically and became quite messy.
We'd have entries in there like "Slack" (which isn't a feature) or duplicates, like "Follow ups" and "Follow-ups."
We have strong structures and patterns in place for features in our codebase. Each feature gets a Go module in the app directory. Each of these modules contains a module.jsonnet file that describes which team owns that module.
We're going to end up with two pipelines for the catalog-importer: one for features and one for modules. Our features come from a static list, whereas modules come from the module.jsonnet files.
In our static list of features, we assign them a name, description, and owner, as well as a stable external ID. Part of our configuration file for the importer ends up looking like this:
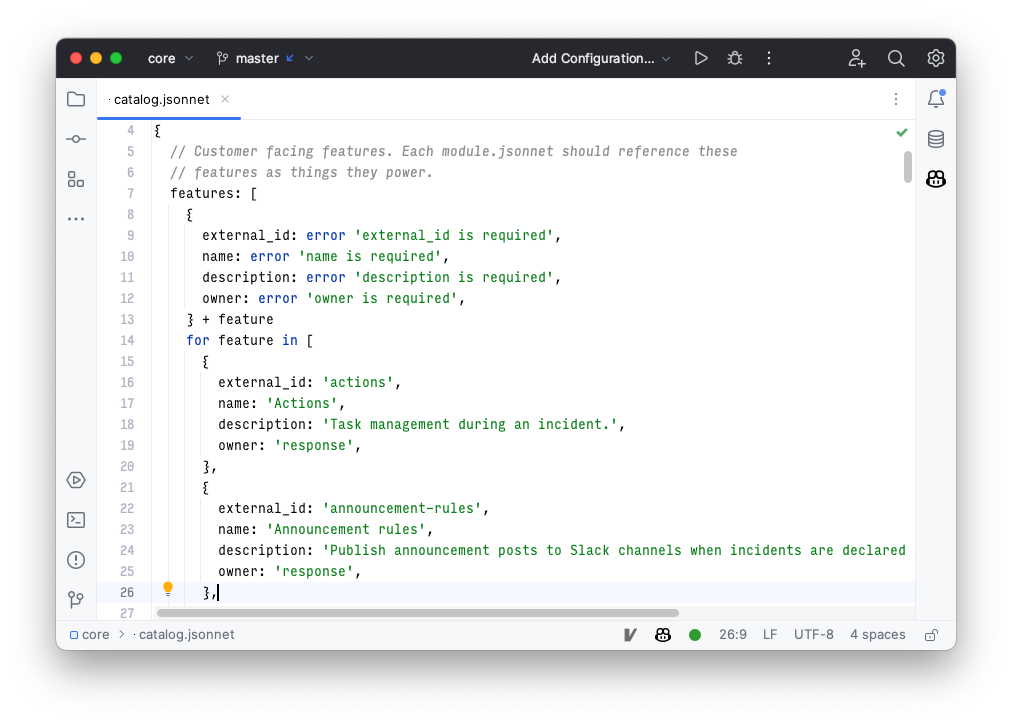
By having the features in Catalog tied to the features in the codebase, our data becomes much cleaner — and it stays in sync. We've eliminated the world where we have to keep custom field options up to date manually, saving us time and increasing the quality of our incident data.
We run the importer as part of our CI process: more on that later.
Integrations
Features are helpful, but we also care about our third-party integrations, such as the ones we have with products like PagerDuty, OpsGenie, Jira, and many others. Integrations are a little different from features and also simpler. There are fewer of them, and the abstractions in our codebase aren't quite as strong.
They suffer from some of the same problems as our features: our old custom field for this was also manually-curated, which we'd have to keep in sync. Release a new integration? Don't forget to update the options.
This also means that our catalog data is a little simpler.
For now, we maintain a static list in a catalog.jsonnet file, which contains a list of those integrations, each with a title, description, and owner. We can write static analysis checks to make sure that list is complete.
As a nice bonus, we've also written a script to automatically generate our CODEOWNERS file, and check that each feature and integration has an owner associated with it. Populating Catalog from the same place your code lives means you can use any existing tooling you have in place, such as linters, to enforce consistency within Catalog.
Teams
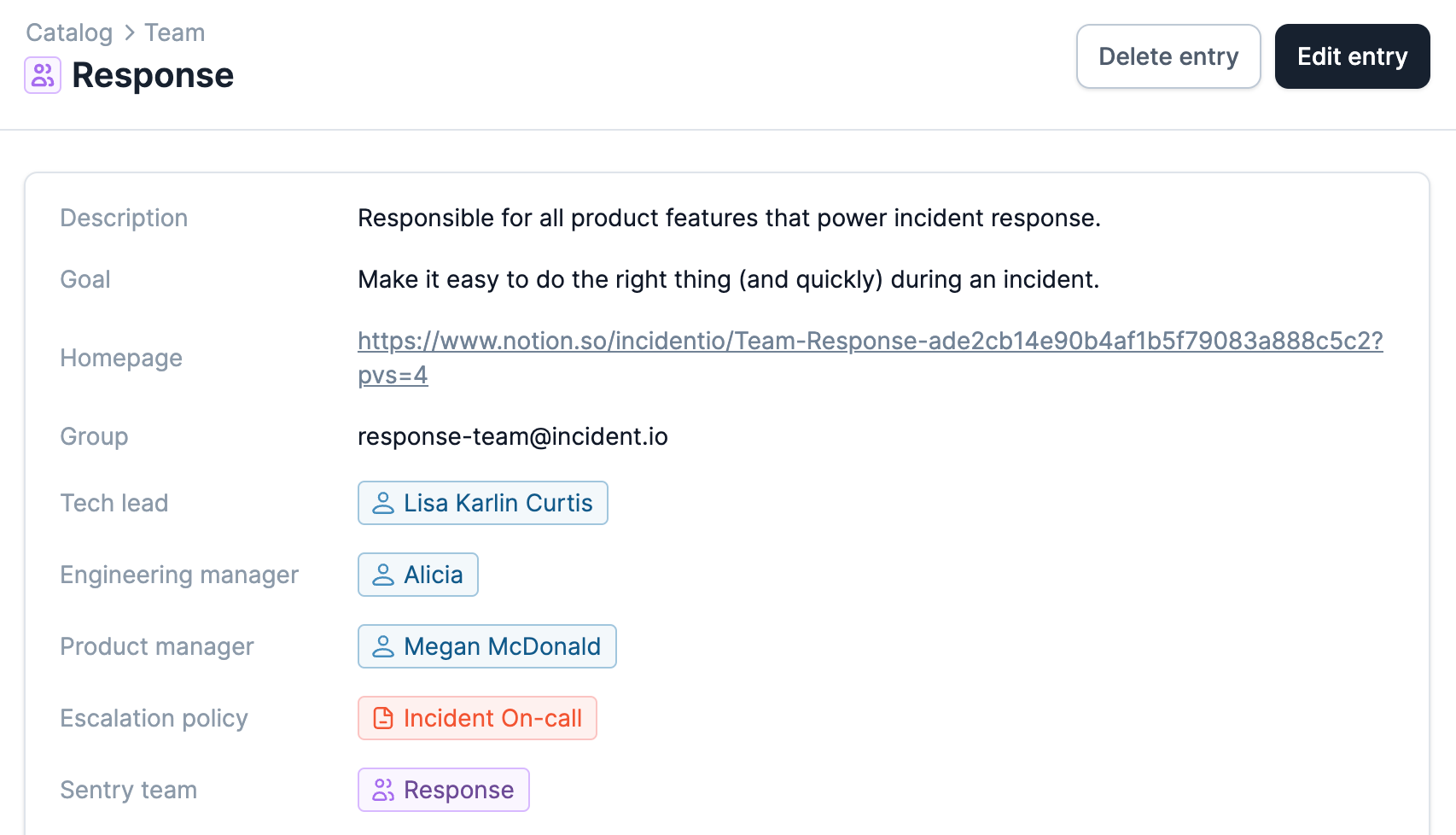
Both types we've created above relate to teams, and this is where we feel Catalog becomes really powerful for us. This screenshot of the "Response" team shows you what our end goal is:
Our features, modules, and integrations all live in our codebase—but what about groups of humans? They tend to live in the real world and in places like Google Workspace. How do we handle that?
We use Terraform within our infrastructure repository to manage our Google accounts and groups, as well as per-team Sentry projects and alerts. We use our catalog as a source of truth for teams and use Terraform to provision everything a team needs: Google Groups, Sentry projects, and much more.
In our screenshot above, our teams have attributes that are Slack users, such as the "Tech lead" and "Engineering manager." This means that if an incident is associated with a team, we can ping the EM to make them aware or automatically invite the tech lead to the channel if the incident is major.
Remaining in sync
We run the Importer as part of our continuous integration pipeline, and feed it all of the configuration it needs to sync features and integrations. We use Circle CI, and the entire process takes around 20 seconds. Because it runs in parallel with our build and tests, it does not affect the speed at which we deploy.
Having this process live alongside the rest of our deployment pipeline also gives us visibility over any failures, and we treat it just like we'd treat any other build failure.
Putting it in action
We've got our data into Catalog — but what do we do with it? Catalog allows you to navigate and query this data in various ways.
We've imported our features and integrations, the teams they're owned by, and the structure of those teams. This unlocks some powerful Workflows that we're finding really useful:
- We announce incidents into team's channels based on the affected services. Each service has a team, and each team has an associated Slack channel. We can bridge the gap: our Workflow contains a query expression, which navigates from services to their teams' Slack channels and then sends an announcement to each.
- We create derived Custom Fields to split our insights by team, which lets us see which team is experiencing the most pager load. Until now, you've been unable to roll up insights to this higher-level grouping without adding an additional custom field, which is another manual step. Derived Custom Fields mean less work for responders: you select the features, and we calculate the teams.
- We automatically export follow-ups to the right Linear project. Our teams in Catalog each have an associated Linear project. This means we can configure our Linear integration to choose a default project based on the affected services.
We're just getting started with using Catalog — we expect that we'll be able to add many more examples to our list over time. We're already finding that we can automate more processes with fewer Custom Fields, giving us more time to focus on fixing incidents.
Wrapping up
Hopefully, you can now see how this might map to your organization, and what you'd find helpful to access within Catalog.
What data do you find valuable to have associated with incidents? Where is that data stored?
Our Importer is designed to make it quick and easy to bring that data into Catalog, and to keep it up to date. It acts as a bridge between your organization's existing data sources and Catalog.
That's allowed us to condense our processes into fewer, more powerful Workflows. It also means we can achieve more with fewer Custom Fields — meaning less manual input when responding to an incident.
We'd love to hear how you'd use Catalog to improve your incident response. Get in touch with us if you have any questions.

Sam Starling
Product Engineer
See related articles


So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


