Post-mortem automation: Opsgenie vs. JSM vs. AI-powered alternatives
April 21, 2026 — 19 min read
Updated Apr 21, 2026
TL;DR: Manual post-mortem reconstruction is a bottleneck, not a writing problem. Opsgenie and Jira Service Management (JSM) provide templates and ticket tracking, but your engineers still face significant effort reconstructing timelines from Slack and monitoring tools before typing a single word. We built incident.io to eliminate that reconstruction step entirely. Our Slack and Microsoft Teams-native platform auto-captures timelines during the incident, transcribes calls with Scribe AI, and generates an 80%-complete post-mortem draft in 10 minutes. With the Opsgenie sunset landing on April 5, 2027, migrating to JSM keeps the same manual workflow. Migrating to incident.io eliminates it.
Your engineering team skips most post-mortems because piecing together a coherent timeline from Slack scroll-back, monitoring dashboards, and engineer recollections is slow, manual work after the incident closes. Atlassian stopped new Opsgenie purchases and trials on June 4, 2025, and the April 5, 2027 end-of-support date forces a migration decision now. The default path is JSM, but if your core problem is documentation burden and post-mortem completion rates, moving to JSM carries that burden over unchanged. This article breaks down exactly where Opsgenie and JSM fall short on post-mortem automation and shows what an AI-native, chat-native platform does instead.
Automating post-mortems: cut manual burden
Post-mortem automation means capturing incident data continuously during response, then using that structured data to generate documentation without requiring engineers to reconstruct events after the fact. The quality of the output depends entirely on the quality of the captured input. If your incident workflow scatters context across Slack threads, call notes, Datadog dashboards, and Jira tickets, any template-filling tool still requires manual data collection before writing can begin.
Our post-mortem ROI calculator shows the documentation overhead adds up fast when your team runs double-digit incidents each month.
Why manual post-mortems lack insights
When your engineers reconstruct timelines days after an incident from memory and Slack search, important details can be lost and context may be incomplete. The precise sequence of alerts, role assignments, and remediation steps can collapse into a rough narrative. Contributing factors often get dropped from the narrative. The result is incomplete documentation that makes it harder to identify and address the root causes that drove the incident.
Principles of post-mortem automation
Post-mortem automation works when you follow three principles. First, capture data at the source in real time rather than attempting reconstruction after the fact. Second, structure that data automatically so AI can generate narrative from it without extensive manual preprocessing. Third, reduce the engineer's role from writer to reviewer, which takes minutes rather than an hour or more. When you meet these three conditions, your post-mortem completion rates rise because you've eliminated the friction. Teams that adopt automated post-incident workflows can achieve faster post-mortem publication as the documentation burden decreases.
Opsgenie vs JSM: post-mortem analysis
Atlassian owns both Opsgenie and JSM, and both tools reflect their ticket-first architecture. The differences between them matter for alerting and on-call scheduling. For post-mortems, both platforms require engineers to supply the data manually before any template or ticket workflow can produce useful output.
RCA: accurate incident timelines
Opsgenie maintains an incident timeline that serves as the source of truth throughout the lifecycle of an incident. It logs incident status, associated alerts, and activity from the Incident Command Center (ICC), and that data is automatically added to the incident post-mortem. JSM ties timeline data to the incident ticket. Both approaches capture structured event data but leave the conversational and diagnostic context that fills the gap between "alert fired" and "root cause identified" for engineers to fill in manually.
Automating accurate post-mortems
Opsgenie provides post-mortem templates that can include incident data. The template covers incident impact, actions taken, and root cause, all editable via a rich text editor. Contributing factors, the root cause narrative, and the timeline of human decisions typically require engineers to fill in manually. Opsgenie offers alert deduplication and grouping capabilities, but does not auto-generate post-mortem narrative from incident data.
JSM's approach is ticket-based. A post-incident review is created as a Jira issue linked to the incident ticket, with automation rules that can open the review automatically when a high-priority incident closes.
Both platforms support conferencing during incidents: Opsgenie through its ICC feature and JSM through its conference call integration. Neither platform automatically transcribes calls or feeds that transcript into the post-mortem draft.
Engineer hours saved per incident
Opsgenie's template pre-fills alert metadata, which removes some blank-field friction. JSM's automation creates the review ticket automatically, eliminating one manual step. But in both cases, your engineers still own the writing, the timeline reconstruction, and the root cause narrative.
Opsgenie: does it automate post-mortems?
Not meaningfully. Opsgenie focuses on alerting and on-call scheduling. While it captures incident timeline data throughout the incident lifecycle and can include this in post-mortem reports, the platform still requires significant manual effort from engineers to complete the narrative with conversational context and detailed root cause analysis.
Manual timeline reconstruction from alerts
When your engineers reconstruct a post-mortem from Opsgenie's timeline, they have access to incident timeline data that includes incident status, associated alerts, and ICC activity throughout the incident lifecycle. However, the gap between "alert fired at 02:47" and "root cause identified at 03:12" contains the diagnostic steps, tool queries, and decisions your engineers made during triage context that rarely appears in alert logs and typically requires manual reconstruction from memory and Slack scroll-back.
What happens after Opsgenie sunset on April 5, 2027
Atlassian stopped new Opsgenie purchases and trials on June 4, 2025. Opsgenie reaches end of support on April 5, 2027. Teams should plan their migration well in advance to ensure adequate time for testing and validation. Starting early allows for a transition period where systems can be validated without risking operational disruptions.
The incident.io migration guide for Opsgenie documents the steps for teams evaluating AI-native platforms.
JSM's post-incident review workflow
Of the two Atlassian tools, JSM provides a structured post-incident review workflow. Its ticket-based approach integrates with the broader Jira ecosystem, and its native Jira integration makes follow-up task tracking genuinely useful for teams already running Jira for development work.
JSM tickets and workflow automation
JSM creates post-incident review issues that live inside the Jira project, each linked to the original incident ticket and traceable for audit purposes. Automation rules can trigger the creation of this review ticket when a major incident resolves, streamlining the workflow. This solves the "nobody created the post-mortem issue" failure mode, and for teams already in the Atlassian ecosystem it's genuinely useful. The limitation is scope: the automation triggers the ticket but does not write the content. Engineers still supply the timeline narrative, root cause analysis, and contributing factors manually.
Atlassian Intelligence (available on JSM Premium and Enterprise plans) can draft a post-incident review from incident record data in seconds, which reduces some writing burden. Rovo, a separate Atlassian add-on, extends AI capabilities further but is not included in Premium by default. However, the draft draws from ticket fields and structured metadata rather than a continuously captured real-time record of everything that happened in Slack, on the call, and across your monitoring tools.
JSM for post-mortem action tracking
JSM tracks follow-up actions as standard Jira issues with assignees and due dates, and Rovo AI can auto-create these tasks. For teams where development work already lives in Jira, this creates a clean loop from incident to action item to development backlog. This works well when your post-mortem content is complete. When timeline reconstruction takes too long and engineers skip details, the action items address incomplete root causes.
We built incident.io with a different architectural approach. Rather than providing a template for engineers to fill in after the incident, the platform captures the entire incident lifecycle as it happens inside Slack and Microsoft Teams. When the incident resolves, the AI uses that captured data to generate a complete first draft, pulling from Slack channel messages, /inc command history, call transcriptions from Scribe, pull requests, and custom fields. Our AI generates a real write-up specific to your incident, not a template with fields to complete.
Auto-capturing Slack activity for post-mortems
incident.io captures incident activity automatically through /inc commands. Commands like /inc assign @sarah-sre and /inc severity high record actions with timestamps. Every message pinned in the channel appends to the structured record. Engineers don't need a dedicated note-taker because the platform captures their coordination work as they do it. The platform's AI capabilities help generate summaries and context from incident channel activity.
AI-generated post-mortem drafts in 10 minutes
When an engineer runs /inc resolve, incident.io generates the post-mortem. Our post-mortems product launch post explains how the AI consolidates context from Slack and Teams channels, the incident timeline, and custom fields to produce a full first draft. Engineers spend 10 minutes reviewing and refining rather than 90 minutes writing from scratch.
Accurate call notes for post-mortems
Scribe joins incident calls on Google Meet or Zoom automatically, transcribes the conversation, and extracts key decisions and action items directly into the incident channel and post-mortem draft. The moment an engineer says "this correlates with the 02:51 deploy, let's roll it back," Scribe captures that as a decision with the timestamp attached. While Opsgenie and JSM both offer in-incident conferencing features, neither platform automatically joins the call, transcribes the conversation, and feeds that transcript directly into the post-mortem draft. This is where the context gap opens, and where manual reconstruction becomes unavoidable.
The full Scribe documentation details how transcription integrates with the post-mortem generation workflow.
Post-mortem tasks auto-synced to Jira
When engineers identify follow-up tasks during the incident, entering them in the incident channel creates tracked action items automatically. incident.io's AI capabilities can help surface likely action items based on incident context. These tasks can sync to Jira or Linear, so the development team sees corrective actions alongside sprint work.
Reduce post-mortem work: choosing your platform
The right platform depends on your primary constraint. If your team's main challenge is Jira integration and action item visibility in the Atlassian ecosystem, JSM's ticket-based approach has real value. If your main challenge is documentation burden and completion rates, JSM solves a different problem.
Cutting post-incident documentation overhead
The table below compares the four capabilities that determine post-mortem automation quality.
| Capability | Opsgenie | JSM | incident.io |
|---|---|---|---|
| Timeline capture | Incident timeline with status, alerts, and ICC activity throughout incident lifecycle | Ticket-based incident tracking | Automatic capture from Slack and Teams channels with /inc commands |
| AI drafting | Post-mortem templates available; extent of automated narrative generation may be limited | Post-incident review workflow | AI generates 80%-complete first draft from captured timeline, Slack/Teams messages, and Scribe call transcriptions |
| Call transcription | ICC conferencing available | Conference call features available | Scribe auto-joins calls, transcribes, extracts decisions into post-mortem |
| Task syncing | Integration capabilities available | Native Jira integration with automated review ticket creation | Task creation from channel entries with Jira and Linear sync |
Why completion rates depend on friction
Post-mortem completion rates vary widely across organizations, with high-performing engineering teams commonly targeting 80–90% or above for major and critical incidents. Teams running manual documentation workflows consistently fall short because the time cost is too high relative to the perceived benefit after the service is back online.
When your post-mortem is 80% complete the moment an engineer opens it, the remaining 10-minute review becomes straightforward. When it's a blank template with 60–90 minutes of reconstruction ahead, the time cost competes directly with the next incident, the next sprint, the next on-call shift. The takeaway: completion rates correlate with friction. The ROI analysis helps you quantify what your current friction costs you.
"incident.io saves us hours per incident when considering the need for us to write up the incident, root cause and actions, communicate it to wider stakeholders and overall reporting." - Pablo P. on G2
Migration paths and implementation effort
Engineering leaders facing the Opsgenie sunset reasonably worry about migration effort. Both paths below run continuously with no gaps in on-call coverage.
Opsgenie to AI for automated post-mortems
The incident.io migration tooling for Opsgenie helps teams transition from Opsgenie, including migrating users, on-call schedules, and other configuration data before end-of-support.
A practical migration runs in three phases:
- Setup (Week 1): Connect Slack, wire up your alert sources (Datadog, Prometheus, PagerDuty), set up Jira or Linear for task syncing, and recreate on-call rotations.
- Parallel run (Weeks 2-4): Run both platforms in parallel where feasible. Run real incidents through incident.io while your existing system remains active. Validate channel auto-creation, on-call paging, and timeline capture on live incidents before committing to full cutover.
- Cutover: Transition fully to incident.io. Export historical Opsgenie data before end-of-support.
Using JSM for post-mortems
For teams that migrate to JSM within the Atlassian ecosystem, the official tooling automatically syncs users, teams, and on-call schedules. Escalation policies, action policies, and chat integrations require manual recreation.
The honest trade-off: JSM's native Jira integration is genuinely valuable for action item tracking, and teams fully invested in the Atlassian suite gain consolidation benefits. The post-mortem documentation burden remains largely manual with standard JSM workflows. If your primary goal is eliminating documentation overhead, evaluate carefully whether JSM's capabilities close that gap for your team.
Launching your first automated post-mortem
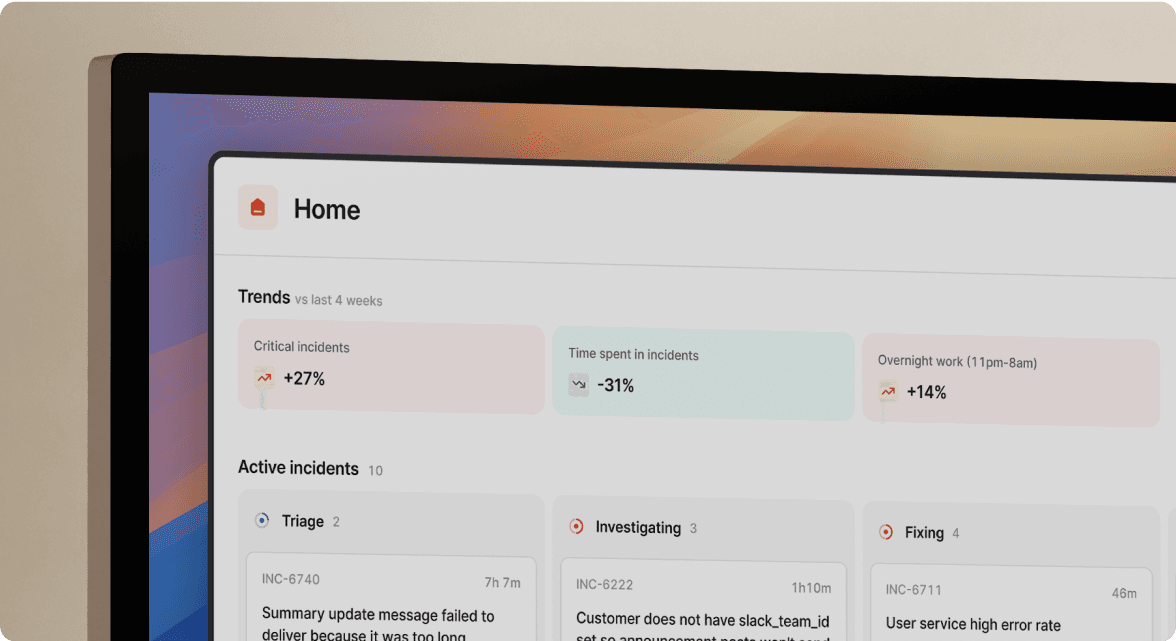
incident.io is designed to get your team operational quickly. New engineers can participate in incidents using /inc commands with minimal onboarding, though effective on-call participation still requires understanding your incident response process and having appropriate context and experience. The commands integrate naturally with Slack, which helps teams build familiarity through real incidents. Your Insights dashboard shows MTTR, resolution times, follow-up status, and team-level breakdowns all populated automatically from the incident data captured during response.
"Incident.io is extremely easy to use. The platform is easy to set up and integrates well with several tools... It helps both during an incident and the post-incident/post-mortem process by allowing users with little training to manage incidents like pros." - Roro O. on G2
To see AI post-mortem generation in a real P1 scenario, Schedule a demo of incident.io and we'll walk through the full lifecycle from alert to published post-mortem.
Key terms glossary
MTTR (Mean Time To Resolution): The average time from alert firing to service restored. Engineering leaders use MTTR to benchmark reliability and track improvement over time. Incident management platform data gives you accurate numbers without manual reporting.
Post-mortem completion rate: The percentage of qualifying incidents (typically P0, your most critical outages causing full service failure, and P1, high-severity incidents causing significant degradation or partial outages) that receive a written post-mortem within a defined time window. High-performing teams commonly target completion rates of 80–90% or above.
Timeline capture: The automated recording of all incident events, decisions, role assignments, and communications in chronological order during response. Manual timeline reconstruction from chat logs and memory typically takes 60-90 minutes per incident.
Scribe: incident.io's AI assistant that joins incident calls on Google Meet or Zoom, transcribes conversations in real time, and extracts key decisions and action items directly into the incident channel and post-mortem draft.
RCA (Root Cause Analysis): The process of identifying the fundamental reason an incident occurred, not just the presenting symptoms. Accurate RCA requires a complete chronological record of everything that happened during the incident, including call discussions and observational context that don't appear in alert logs.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


