Overhauling PagerDuty’s data model: a better way to route alerts
January 20, 2025 — 12 min read

Since its launch in 2009, PagerDuty has been the go-to tool for organizations looking for a reliable paging and on-call management system. It’s been the operational backbone for anyone running an ‘always-on’ service, and it’s done the job well. Ask anyone about the product, and you’re all-but-guaranteed to hear the phrase “it’s incredibly reliable.” I agree.
But reliability isn’t everything. Many users feel PagerDuty has neglected innovation in its core on-call product, focusing instead on expanding into areas like AIOps and “the Operations Cloud”—whatever that is. Meanwhile, as teams increasingly manage incidents within communication tools like Slack and Microsoft Teams, PagerDuty has struggled to keep pace with the evolving market.
But innovation aside, many teams face a more fundamental challenge with PagerDuty: its core experience and data model for routing alerts—from the systems that generate them to the right person’s phone.
In this post, we’ll explore the core experience of setting up alerting systems and ensuring the right people get paged. We’ll compare PagerDuty’s data and routing model to how we’ve reimagined it with incident.io On-call, providing a markedly improved way to set up and operate on-call.
Finally, we’ll walk through two ways companies are successfully migrating from PagerDuty to incident.io. Let’s dive in!
The PagerDuty data model and its limitations
If you’re reading this, you’re likely familiar with PagerDuty’s data model for routing alerts to on-callers. In the interest of getting everyone on the same page though, here’s a quick primer:
- Services: The core building blocks for aggregating alerts, and used to represent teams, systems, or services. Many customers use Services to represent a combination of all three.
- Integrations: A sub-component of a Service that connect external systems like Datadog or Prometheus, or enable features like inbound email connections.
- Escalation Policies: Define the order and timing of notifications until an issue is acknowledged or resolved; each Service links to one Escalation Policy.
For visual learners, here’s how it looks:
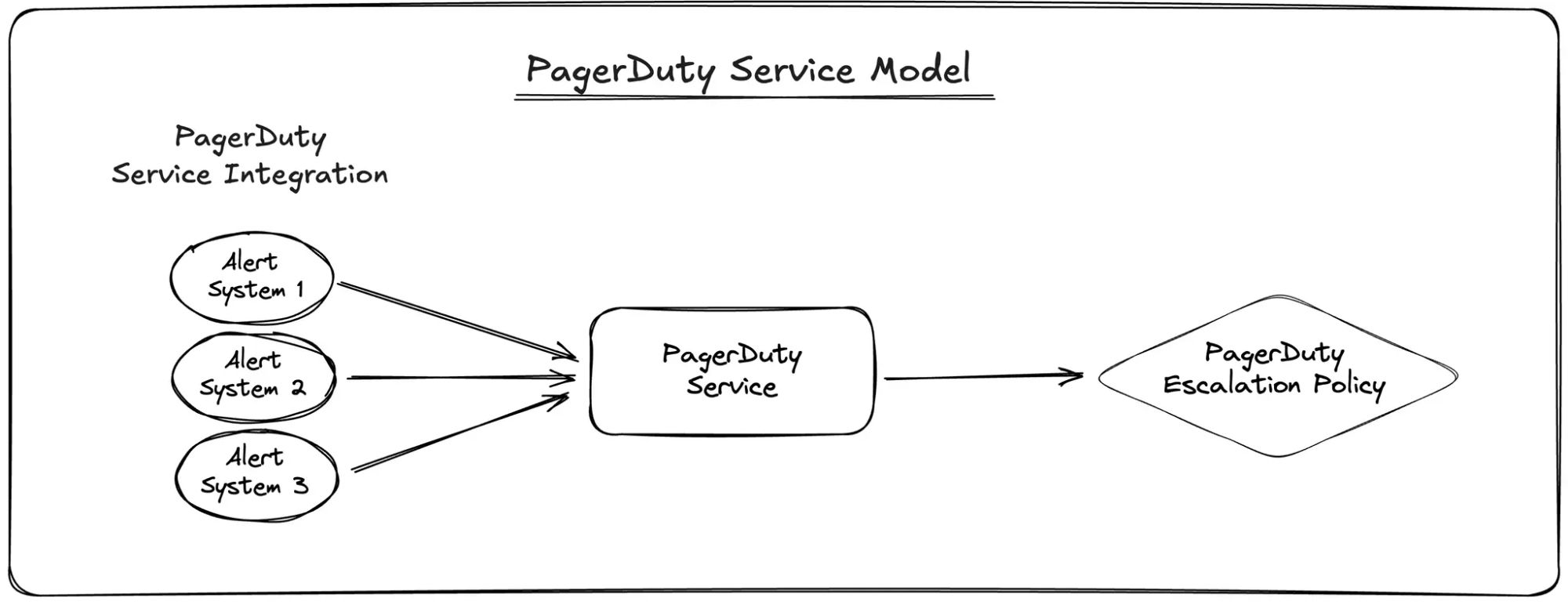
There’s a lot to like about PagerDuty’s approach, particularly its simplicity when starting out—create a Service, connect monitoring systems, and forward alerts to an escalation policy. However, this simplicity comes with significant challenges:
- Configuration sprawl: The "everything is a Service" approach often leads to an account filled with overlapping Services representing teams, systems, applications, and more. As the account grows, understanding and updating configurations becomes increasingly difficult.
- Distributed alert routing: Routing logic is most commonly handled outside of PagerDuty, requiring configurations in monitoring tools. For example, if two teams share a monitoring system like Prometheus, alerts must be routed separately within Prometheus itself, creating a complex web of configurations.
- Complexity at scale: Managing hundreds of Services and integrations becomes cumbersome, requiring additional tools like Terraform to maintain control, which can lead to brittle, hard-to-maintain setups.
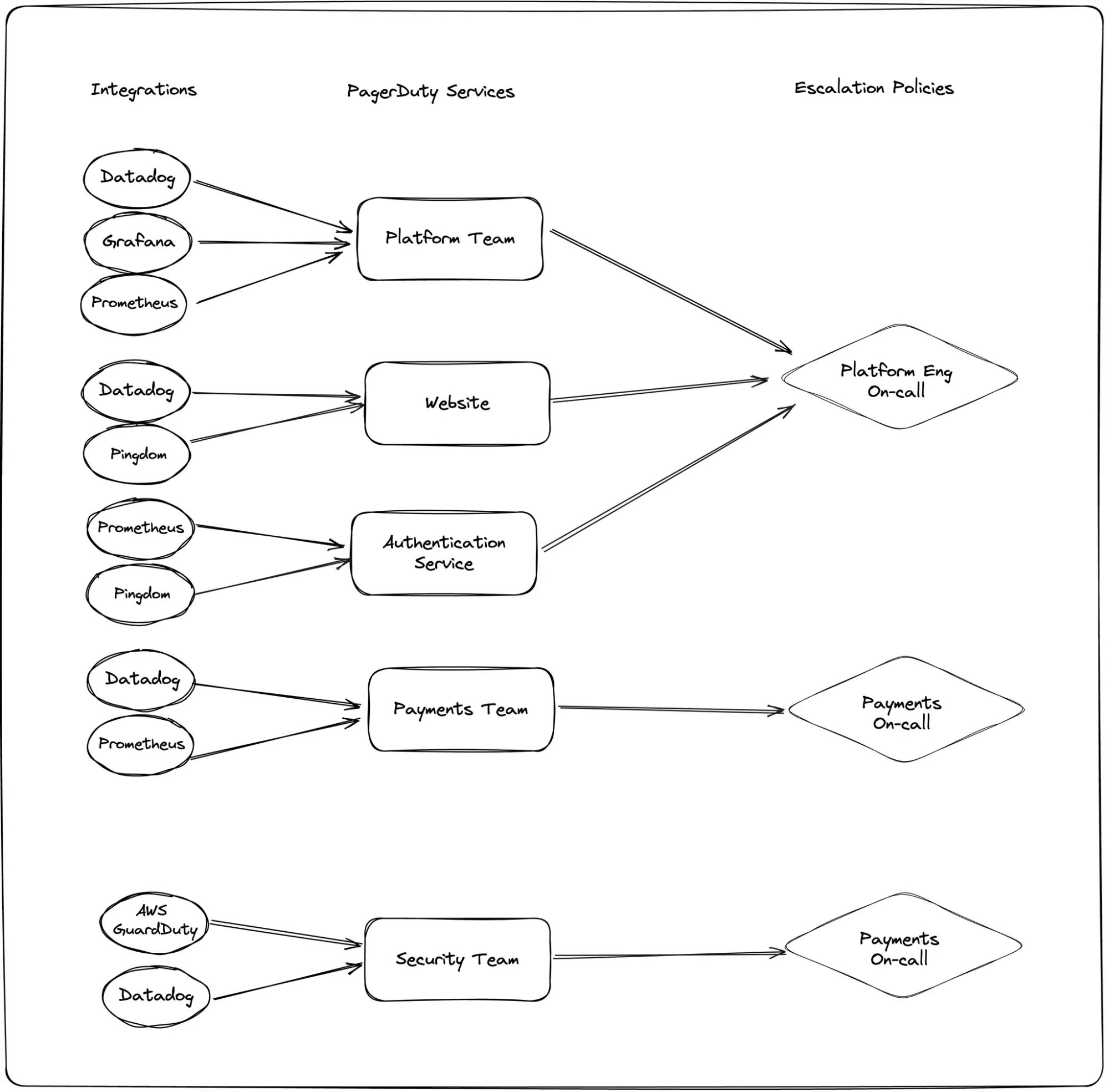
In the interest of transparency, PagerDuty does offer more routing flexibility through Event Orchestration. However, it’s complex to configure and only available on higher-cost pricing tiers, like AIOps or Advanced Event Orchestration.
How we’ve simplified things with incident.io
When designing incident.io On-call, we focused on solving the common pain points of the PagerDuty model while keeping the elements that work well. Our goal was to offer a system that could replicate a PagerDuty configuration without requiring a complete overhaul, while also enabling teams to simplify and improve their setup over time.
Our guiding principles
- Flexible routing: Move beyond the concept of “Services” and allow routing based on teams, applications, systems, or other entities—ensuring clarity and flexibility.
- Separation of static and dynamic data: Make organizational changes easier to manage by separating frequently changing data (like team ownership) from static alerting configurations like “route alerts based on the team or service”.
- Smooth migration: Provide an easy path to migrate from PagerDuty while introducing improvements at your own pace.
Our core model
- Alert sources: Connect external systems like Datadog or Prometheus just once, rather than for every service.
- Alert routes: Process incoming alerts and determine escalation paths efficiently using our Catalog.
- Escalation paths: Define notification sequences similar to PagerDuty's escalation policies, but with added flexibility (a story for another time!)
Here's how our data model works:
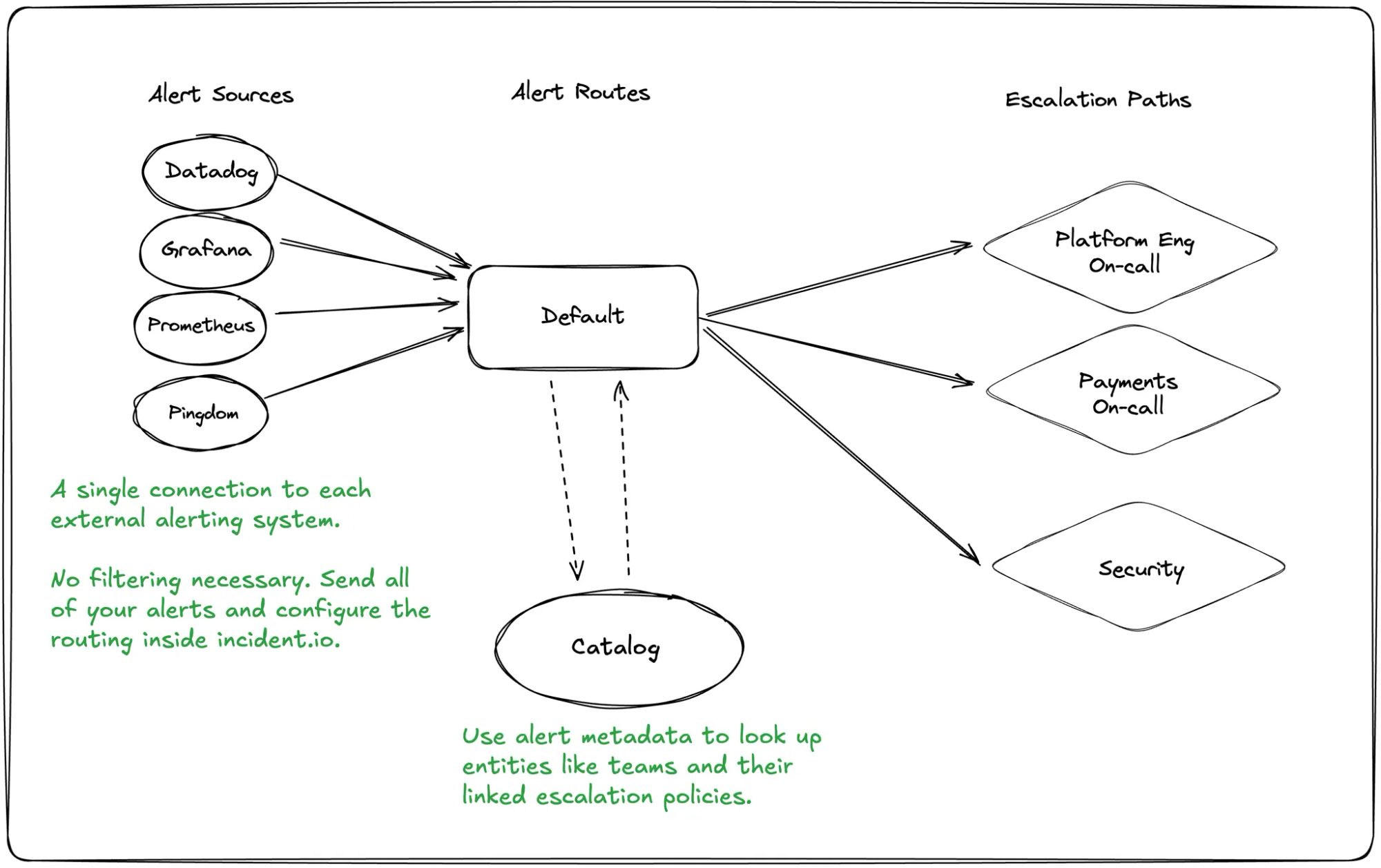
Catalog: the major unlock
The eagle-eyed among you will notice the introduction of “Catalog” in the diagram above.
PagerDuty’s configuration is largely static and changes to teams or ownership require updates across multiple systems. With incident.io's Catalog, routing logic is centralized and dynamically linked to organizational data.
Catalog-based routing example
Best explained through example, let’s imagine our alert route logic is configured as follows:
if the alert has a team:
escalate to the team's linked escalation path
else if the alert has a service:
find the service's owning team and escalate to their escalation path
otherwise:
escalate to a default escalation path And our (simplified!) Catalog looks like this:
| Name | Escalation Path |
|---|---|
| Platform Team | Platform |
| Security Team | Security |
| Name | Owner |
|---|---|
| Deploy Service | Platform Team |
| Auth Service | Security Team |
Now, if an alert arrives that looks like this:
{
"name": "AuthServiceOffline",
"team": "security_team"
}
We’d unpack it, find Security Team and return the Security escalation path to the Alert Route so the escalation arrived with the security team on-caller.
And if we received an alert like this:
{
"name": "DeployHighErrorRate",
"service": "deploy_service"
}We’d unpack it, find Deploy Service then navigate to the owning team Platform Team and return the Platform escalation path to the Alert Route so the escalation arrived with the platform team on-caller.
Now if we need to make a change to add a new Service Payments whilst also changing the ownership of the Deploy Service to Security Team, we just update Catalog entries, leaving our routing logic entirely untouched. It’s all data.
Obviously, this is a simplified example, but in an organization where there’s hundreds of teams and thousands of services, and Catalog is synchronized with your source of truth (like Backstage, ServiceNow CMDB or your home-built solution), it’s a huge time saving and peace of mind improvement to know on-call escalations aren’t a thing you need to concern yourself with.
Comparing the models
At first glance, the data models of PagerDuty and incident.io might seem similar. This is intentional—our goal is to provide a smooth migration experience. However, the subtle differences in our approach lead to significant improvements in managing on-call operations.
- Simplified alert system setup: Instead of adding configuration to each and every alert system to ensure alerts are routed to the right place, add one piece of configuration to forward all of your alerts to us.
- Centralized routing logic: Rather than managing routing decisions across multiple tools like Datadog and Prometheus, everything is controlled within incident.io, making it easier to answer questions like, “Why was I paged?”
- Scalability and flexibility: With the Catalog feature, changes to teams and services no longer require extensive reconfiguration—updates can be made dynamically and centrally.
This approach not only reduces operational complexity but also makes scaling and adapting to organizational changes much easier.
The two ways organizations are migrating from PagerDuty to incident.io
We’ve helped hundreds of companies migrate, and while the specifics vary, most follow one of two paths:
Replicate your existing setup
Why choose this approach?
If you’re happy with your current alert routing and want to leverage incident.io’s advanced features without major changes, this is the best option.
Steps to migrate:
In a straight replication, the process is very straightforward, and looks broadly like this:
- Configure Escalation Paths to efficiently match your existing Escalation Policies.
- We have a migration tool for this within the product that makes it as simple as a few clicks. We’ll copy over your Escalation Policies, the linked Schedules, and any referenced users.
- For each of the Services in your PagerDuty account:
- Create an Alert Source for each of the integrations, and replicate the logic within the alerting system configuration.
- Create an Alert Route that connects to the Alert Source on one side, and the relevant Escalation Path on the other.
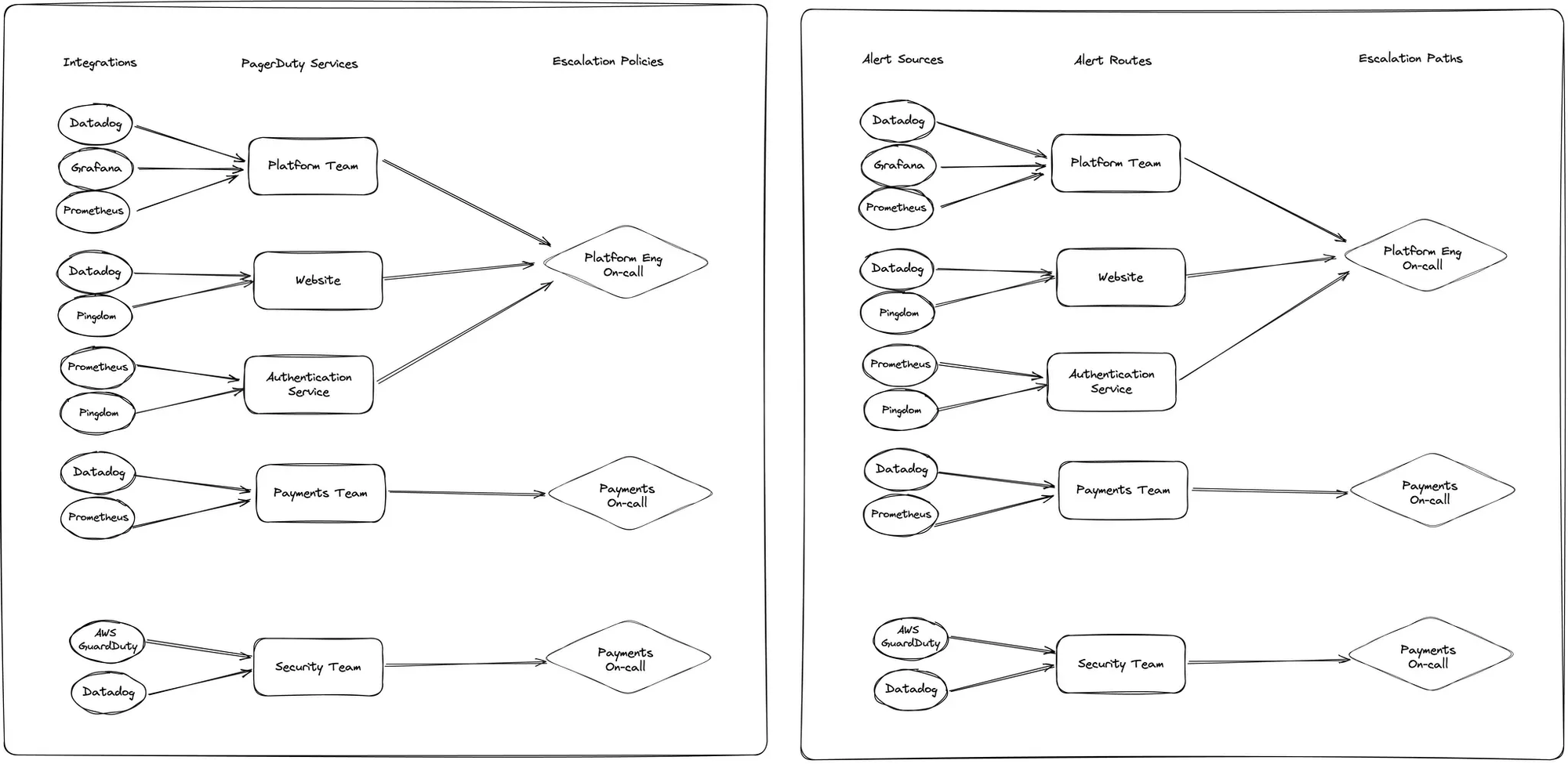
It’s a little time consuming, granted, but with no changes to the routing model, it becomes a very straightforward task. This is the before and after of this migration:
Adopt incident.io’s routing model
Why choose this approach?
If you're looking to simplify and optimize your on-call setup, this approach centralizes routing logic and streamlines your configuration.
Steps to migrate:
This approach revolves around populating data in Catalog to map alerts to teams, and centralizing all routing logic within an Alert Route. The specifics will vary depending on how alerts route to teams, but in broad strokes it can be broken down as below:
- Configure Escalation Paths to match your existing Escalation Policies.
- We have a migration tool for this within the product that makes it as simple as a few clicks. We’ll copy over your Escalation Policies, the linked Schedules, and any referenced users.
- For each of your monitoring tools, set up an Alert Source in incident.io, and configure it to send all alerts to us, unfiltered.
- Since the routing logic will move within the platform, there’s no need for multiple separate connections.
- Configure Catalog with the data required to make efficient routing decisions.
- This part depends most heavily on your environment. In our experience, most organizations include metadata in their alerts that allow ownership to be inferred. That might be that the alert is tagged with the service so you can jump from service to team, or it might have the team tagged directly.
- In setting up your Catalog, you simply need to ensure there’s some mapping from the data you have in your alerts, to the team you want to escalate to. And it really can be anything: if nothing else exists, a mapping from alert name to team can suffice.
- Create an Alert Route, and configure the rules based to match your desired logic.
- Lots of options here but any organizations configure versions of routing logic like this:
if the alert has a team:
escalate to the team's escalation path
else if the alert has a service:
find the service's owner team and escalate to their escalation path
else:
escalate to a default escalation path
Overall, this approach takes more effort to set up, but vastly simplifies ongoing management, making it more efficient to adapt to organizational changes.
Ready to make the switch?
From our own experience and the feedback we've had from our customers, we're confident incident.io On-call offers a significant step forward for managing on-call alert routing. Whether you choose to replicate your current setup or optimize it, we've got the tools and flexibility to support your needs.
And, honestly, this post skipped over all of the really good stuff! Things like cover requests, smart escalation paths, multi-rota schedules that support things like shadow on-call natively, and a mobile app that feels like it was built in this century.
In today's fast-paced world, having integrated solutions is crucial for success. These systems allow for smooth operations and effective communication across various platforms.
Integrated systems ensure that all components work together in a unified manner, providing a smooth experience for users.
FAQs on Integrated Technology

Chris Evans
Co-Founder & Field CTO
I'm one of the co-founders, and Field CTO here at incident.io.
See related articles

We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete HamiltonMarch 17, 2026

Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherNovember 14, 2025

My first three months at incident.io
Hear from Edd - one of our recent joiners in the On-Call team - how have they found their first three months and what's it been like working here.
 Edd Sowden
Edd SowdenSeptember 1, 2025
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


