Incident management tools for startups: Cost-effective solutions under $500/month
January 19, 2026 — 19 min read
Updated January 19, 2026
TL;DR: Startups with 5-15 on-call engineers need incident management tools that consolidate coordination without enterprise pricing. Our Team plan delivers on-call scheduling, Slack-native coordination, status pages, and AI-powered post-mortems for $310/month for a 10-person team. PagerDuty offers sophisticated alerting but requires separate status page tools. Better Uptime provides straightforward monitoring at $170/month. Grafana OnCall's free tier caps at 3 users. Atlassian is sunsetting Opsgenie by April 5, 2027. Calculate true total cost of ownership, including add-ons for on-call, status pages, and SSO, while prioritizing tools that reduce coordination overhead instead of adding browser tabs during outages.
Manual incident coordination breaks down once you hit 5-10 engineers on-call. You're creating Slack channels by hand, hunting through spreadsheets to find who's paged, and copy-pasting alert links from three monitoring tools while customers flood support tickets. The first 15 minutes of every incident goes to assembling the team before anyone troubleshoots the actual problem.
This coordination overhead works when you're three engineers shipping fast. It fails catastrophically at 10-15 people handling 5-15 incidents monthly. PagerDuty's enterprise pricing feels excessive for a Series A startup watching burn rate, but you need something better than manual chaos.
This guide compares five incident management platforms under $500/month, analyzing true costs (including hidden add-ons), setup time, and scalability so you spend less time coordinating and more time fixing.
Why startups need dedicated incident management (beyond just Slack)
Ad-hoc Slack channels fail predictably once you scale past 5-10 people. Tribal knowledge breaks down when the "hero engineer" who knows everything takes vacation during a database failure. New on-call engineers panic during their first page because runbooks live in someone's head, not documentation.
Compliance requirements force investment earlier than expected. SOC 2 Type II certification requires complete audit trails with timestamped incident documentation showing who did what and when. ISO 27001 mandates log retention typically spanning 12 months. Manual Slack threads don't generate audit-ready documentation without reconstruction.
The tipping point arrives when coordination consumes more time than problem-solving. If incidents average 45 minutes end-to-end but only 20 minutes involve actual troubleshooting, your tools are failing you. Research shows downtime averages $5,600 per minute across industries. For startups handling 10 incidents monthly, saving 10 minutes per incident recovers 100 minutes of engineering time monthly.
Evaluation criteria: What to look for in budget-friendly tools
True Cost of Ownership (TCO) matters more than advertised base pricing. Tools listed at "$15/user/month" often hide costs in mandatory add-ons. On-call scheduling typically costs an extra $10-20/user monthly. Status pages add another $29-399/month if sold separately. SCIM provisioning can add $5,000 annually. Calculate total monthly cost for your actual team size with features you'll use, not the marketing page entry price.
Time-to-value separates startup-friendly tools from enterprise complexity. Can you integrate with Datadog, Prometheus, and Slack in under 2 days? Or does implementation require six weeks and dedicated engineering time? For early-stage teams, operational within a week beats feature-rich but complex.
Slack-native or Microsoft Teams-native architecture reduces context-switching during high-stress moments. Web-first tools that "integrate" with Slack send notifications but force responders to open browser tabs, log in, and navigate UIs under pressure. Native tools handle incident declaration, escalation, role assignment, and resolution via slash commands without leaving chat.
Integration depth with your existing stack determines adoption speed. Essential integrations include monitoring tools (Datadog, Prometheus, New Relic), ticketing systems (Jira, Linear), and documentation platforms (Confluence, Notion). Tools requiring custom webhook configuration add engineering maintenance burden.
Top incident management tools under $500/month
1. incident.io: Best for Slack-native coordination and rapid setup
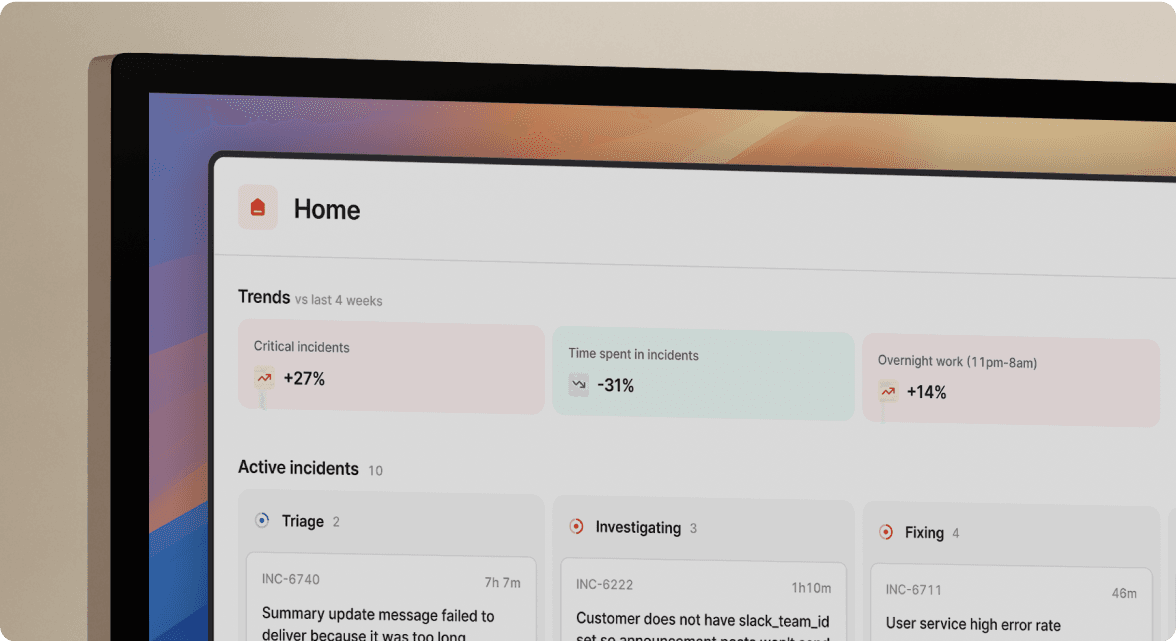
We consolidate on-call scheduling, incident response coordination, status pages, and AI-powered post-mortems into one Slack-native platform, eliminating the need to buy separate tools or context-switch during incidents.
Pricing for 10-person team:
Our Team plan costs $19/user/month for incident response with on-call scheduling adding $12/user/month. Total: $310/month for 10 engineers with full on-call capabilities, one status page, unlimited integrations, and Slack-native workflows.
Key strengths:
Setup completes in 1-2 days for full integration. Alerts from monitoring tools automatically create dedicated incident channels. We page on-call engineers, pull in service owners from the Service Catalog, and start capturing timelines without manual channel creation.
As one verified user explains:
"incident.io brings calm to chaos. We've been running incidents in slack for a few years, however, our process and tooling were limiting and made incident response a challenge. Incident.io is now the backbone of our response, making communication easier, the delegation of roles and responsibilities extremely clear, and follow-ups accounted for." - Braedon G. on G2
Our AI SRE capabilities automate up to 80% of incident response by identifying likely root causes from deployment history and suggesting fixes based on past incidents. Post-mortems generate automatically from captured timeline data, call transcriptions, and Slack messages. Teams spend 10 minutes refining instead of 90 minutes writing from scratch.
Watch how our on-call scheduling works for startups, see response coordination in action, and explore status page capabilities.
Limitations:
The Team plan includes 3 workflows, which most startups find sufficient initially. One small company user noted that pricing increases when needing more workflows or custom fields.
Best for: Teams that live in Slack, need rapid deployment (operational within days), and want to eliminate tool sprawl by consolidating on-call, response, and status pages.
2. PagerDuty (Free/Starter): Best for pure alerting needs
PagerDuty excels at alert routing, deduplication, and on-call scheduling with 700+ integrations across monitoring tools, but focuses on alerting rather than incident coordination.
Pricing for 10-person team:
Industry analysis estimates PagerDuty costs approximately $20/user/month for basic alerting and on-call, totaling around $200/month for 10 users. However, PagerDuty doesn't include status pages. You must purchase Atlassian's Statuspage.io separately, starting at $29/month for basic tiers or up to $399/month for branded pages.
The bundled cost for PagerDuty + Pingdom + Statuspage.io reaches $673/month for 6 team members, exceeding startup budgets once you add monitoring and status page requirements.
Key strengths:
Battle-tested alerting with sophisticated routing rules and escalation policies. Organizations already using PagerDuty for monitoring get reliable paging without changing vendors. Integration catalog covers virtually every monitoring tool startups use.
Learn about AI capabilities in PagerDuty's incident management and understand how PagerDuty handles major incident communications.
Limitations:
Web-first interface requires opening browser tabs during incidents instead of handling coordination in Slack where teams naturally communicate. This migration case study from Intercom shows engineering teams preferring platforms where the entire incident lifecycle lives in one communication tool rather than bouncing between PagerDuty's web UI and Slack threads.
Best for: Teams needing sophisticated alert routing and already using PagerDuty for monitoring, or organizations with complex multi-tier escalation requirements where PagerDuty's routing sophistication justifies higher costs.
3. Opsgenie (Essentials): Best for existing Atlassian users
Opsgenie provides alerting, on-call management, and escalation policies with tight coupling to Atlassian's ecosystem, including Jira Service Management, Confluence, and Statuspage.io.
Pricing for 10-person team:
Opsgenie offers competitive entry-level pricing for small teams. However, like PagerDuty, you must purchase Statuspage.io separately at $29-399/month depending on tier for customer-facing status pages.
Critical limitation:
Atlassian announced Opsgenie will sunset April 5, 2027, forcing migration to Jira Service Management or Compass using an automated migration tool. Organizations adopting Opsgenie today face mandatory platform migration within 15 months, introducing risk and engineering overhead.
This analysis of top Opsgenie alternatives shows DevOps teams proactively switching incident tools rather than waiting for forced migration.
Key strengths:
For organizations already standardized on Atlassian products (Jira, Confluence, Bitbucket), Opsgenie provides native integration and SSO convenience. The alert management rules engine offers sophisticated routing refined over years of enterprise deployments.
See an honest review of Opsgenie's user experience and understand the platform's current state before the sunset deadline.
Best for: Teams locked into Atlassian's ecosystem who plan to migrate to Jira Service Management before April 2027. For startups evaluating fresh incident management tooling, choosing a platform being deprecated within 15 months introduces unnecessary migration risk.
4. Grafana OnCall: Best for open-source monitoring stacks
Grafana OnCall integrates tightly with Grafana Cloud IRM for teams already using Grafana for observability, offering on-call scheduling and alert routing within the Grafana ecosystem.
Pricing for 10-person team:
The free tier limits usage to 3 users, making it insufficient for a 10-person team. Grafana Cloud IRM paid plans require Enterprise Plugins access, with Enterprise plans requiring $25,000 annual minimum commitments that price out early-stage startups.
Key strengths:
Native integration with Grafana dashboards means alerts trigger on-call workflows without leaving the Grafana interface. Teams already standardized on Grafana for metrics, logs, and traces benefit from unified observability and incident response tooling.
Limitations:
Grafana OnCall OSS entered maintenance mode on March 11, 2025, with full archival planned for March 24, 2026. While existing installations continue working, no new features or updates are planned. The 3-user free tier doesn't support teams with 5-15 on-call engineers.
Best for: Teams heavily invested in Grafana Cloud who value tight integration with their existing observability stack and can accept the limitations of a 3-user free tier or afford Enterprise pricing.
5. Better Uptime: Best for simple status pages and call routing
Better Uptime (part of Better Stack) focuses on uptime monitoring, basic on-call scheduling, and status pages with straightforward pricing and fast setup.
Pricing for 10-person team:
The Business plan costs $170/month for 1,000 monitors, 25 status pages, and 5 members per team. Better Stack bundles monitoring with Datadog, New Relic, and Prometheus integrations.
Key strengths:
Better Uptime claims setup completes quickly with straightforward configuration. All paid plans include unlimited email, phone, and SMS alerts with 30-second check intervals and SSL monitoring. The status page feature is built-in rather than sold separately.
Watch how Opsgenie users are switching to alternatives like Better Uptime as the April 2027 sunset approaches.
Limitations:
Better Uptime integrates with many tools including customer support platforms, though the platform emphasizes uptime monitoring over deep incident management workflows. It lacks features like AI-powered root cause analysis, automated post-mortem generation, or advanced incident coordination capabilities.
Best for: Small teams (5-10 engineers) needing reliable uptime monitoring, basic on-call rotation, and status pages without complex incident coordination requirements or post-mortem automation.
Comparison table: Features, pricing, and scalability
| Tool | Monthly Cost (10 users) | On-Call Included? | Status Page Included? | Slack-Native? | Setup Time |
|---|---|---|---|---|---|
| incident.io Team | $310/month | Yes (+$12/user) | Yes (1 page) | Yes | 1-2 days |
| PagerDuty Base | $200/month + status page | Yes | No (buy separate) | No (web-first) | ~1 week |
| Opsgenie Essentials | Varies (sunsetting 4/5/27) | Yes | No (buy separate) | No | 1-2 days |
| Grafana OnCall Free | $0 (3 users max) | Yes | No | No | Varies |
| Better Uptime Business | $170/month | Yes | Yes | No | Fast setup |
The table shows we include on-call scheduling and status pages within the $310 monthly cost while competitors either exclude essential features or require separate purchases that push total costs higher.
Hidden costs to watch out for in "cheap" plans
The "add-on trap" inflates advertised pricing once you enable essential features. Vendors charge an additional $10-20/user/month for on-call scheduling beyond base incident management pricing. For a 10-person team, that's $100-200/month in mandatory costs hidden from marketing pages.
Status pages force you to buy separate tools or premium tiers. PagerDuty and Opsgenie customers must purchase Atlassian Statuspage.io separately at $29-399/month depending on subscriber limits and branding. A bundled example shows PagerDuty + Pingdom + Statuspage.io costing $673/month for 6 team members.
SCIM provisioning can add $5,000 annually at some vendors. While early-stage startups may defer enterprise authentication, Series B companies pursuing SOC 2 compliance face surprise costs when security requirements mandate centralized access control.
AI and automation features increasingly gate behind premium tiers. Vendors offer "AI-powered" capabilities in marketing materials but limit them to Enterprise plans or charge per-usage fees. We include AI SRE in the Team plan without additional charges.
Maintenance costs for open-source or custom solutions consume engineering time. Teams building internal incident bots face ongoing maintenance when Slack APIs change, integration failures require debugging, and feature requests create scope creep. At $150 loaded hourly cost per engineer, 10 hours of quarterly maintenance ($1,500 annually) exceeds paying for a commercial tool.
How to calculate ROI for your incident management tool
Monthly Savings = (Time Saved Per Incident × Monthly Incident Count × Loaded Engineer Cost) + Tool Consolidation Savings - Monthly Tool Cost
Example for 10-person team:
Your team averages 15 minutes of coordination overhead per incident across 10 incidents monthly.
- Time saved: 15 minutes × 10 incidents = 150 minutes monthly
- Loaded engineer cost: $150/hour
- Value of time saved: 2.5 hours × $150 = $375/month
- Tool consolidation: Eliminating separate status page ($50/month)
- Total monthly value: $425
- Tool cost: $310/month for our Team plan
- Net monthly savings: $115 ($1,380 annually)
Research shows downtime averages $5,600 per minute across industries. Reducing MTTR by 10 minutes per incident generates substantial downtime avoidance value beyond the subscription expense.
Factor in compliance value for startups pursuing SOC 2 or ISO 27001. Complete audit trails with timestamped documentation eliminate manual evidence collection during certification cycles.
Consolidate your incident management stack
Startups operating under $500 monthly budgets have viable options beyond manual Slack chaos. We deliver complete incident coordination (on-call, response, status pages, AI post-mortems) in our Team plan for $310/month with setup completing in 1-2 days. Better Uptime costs $170/month for straightforward monitoring and basic on-call. PagerDuty and Grafana OnCall serve specific use cases but require careful TCO analysis.
Avoid platforms Atlassian is sunsetting like Opsgenie, which faces forced migration by April 5, 2027. Calculate true costs including on-call add-ons, status pages, and engineering maintenance time. Prioritize Slack-native tools that reduce context-switching during high-stress incidents.
Try incident.io free for 14 days and run your first incident in Slack to see if our workflow fits your team. For teams needing advanced capabilities, schedule a demo to discuss our Pro plan while staying within startup budgets.
Learn about our migration tools from PagerDuty or Opsgenie if you're switching platforms. Watch how teams are migrating their on-call from PagerDuty to see real-world migration experiences.
Key terminology
MTTR (Mean Time To Resolution): Average time from incident detection to full resolution, measured in minutes. Effective incident management tools aim to reduce coordination overhead that extends resolution time.
On-call rotation: Scheduled assignments determining which engineer receives alerts during specific time periods (daily, weekly, or custom shifts). Effective rotations balance coverage with engineer wellbeing to prevent burnout.
Slack-native: Tools architected to function entirely within Slack using slash commands and channel interactions, not web applications that merely send Slack notifications. This architectural distinction eliminates context-switching during incidents.
Runbook: Step-by-step documentation for responding to specific incident types, including diagnostic commands, escalation procedures, and resolution steps. Effective runbooks reduce cognitive load during high-stress incidents.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

