How our data team handles incidents
July 26, 2024 — 7 min read

Historically, data teams have not been closely involved in the incident management process (at least, not in the traditional “get woken up at 2 AM by a SEV0” sense). But with the growing involvement of data (and therefore data teams) in core business processes, decision-making, and user-facing products, data-related incidents are increasingly common, and more important than ever.
At incident.io, the Data team works across multiple areas of the business, enabling go-to-market and product teams alike to make data-driven decisions. Given our broad involvement, we’re no stranger to data incidents and are heavy users of our product to monitor, triage, and respond to them. Here’s a quick run-through of how we’ve set this up.
Getting the data team on-call
Earlier this year, we released our long-anticipated On-call, creating a true end-to-end incident management experience. Naturally, we decided to use this ourselves, and have arrived at an elegant and effective setup to help make our lives a whole lot easier.
Every week, one person on the Data team is a designated “Data Responder”, whose responsibilities include:
- Leading any data-related incidents (e.g. dbt pipeline failures/errors)
- Addressing dbt test warns (because if you ignore a warning for too long, then is it worth even having it in the first place?)
- Handling any ad-hoc queries or fixes from the wider company
We’re able to configure this schedule quite nicely in our product, setting the schedule duration to be working hours only, and rotating through each of the members of the Data team.
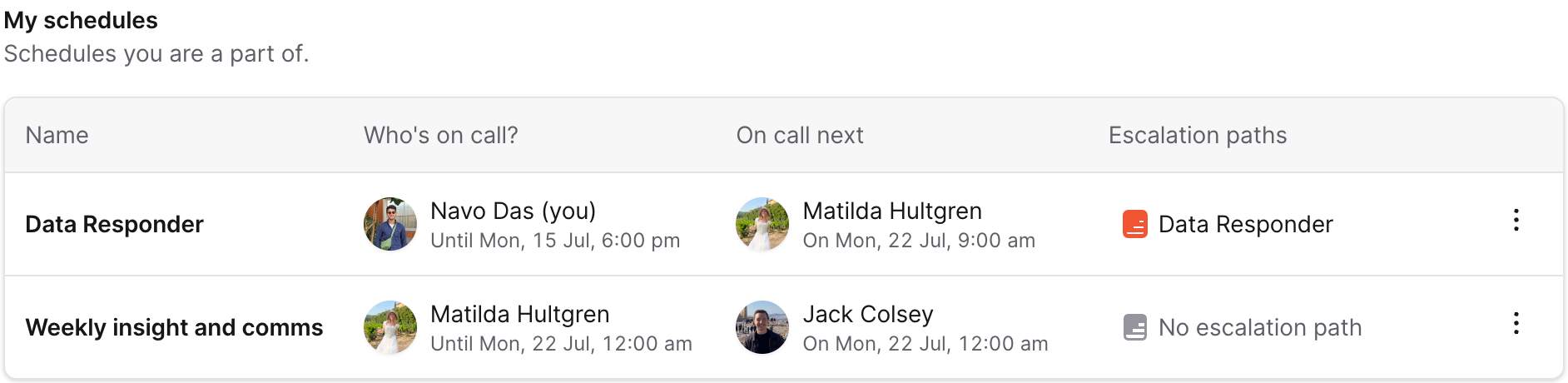
We also allow schedules to be synced to Slack user groups, which will automatically tag whoever is on-call at any given time. This means that both Slack alerts and end-users can use @data-responder to mention the team member on-call, rather than alerting the entire team.
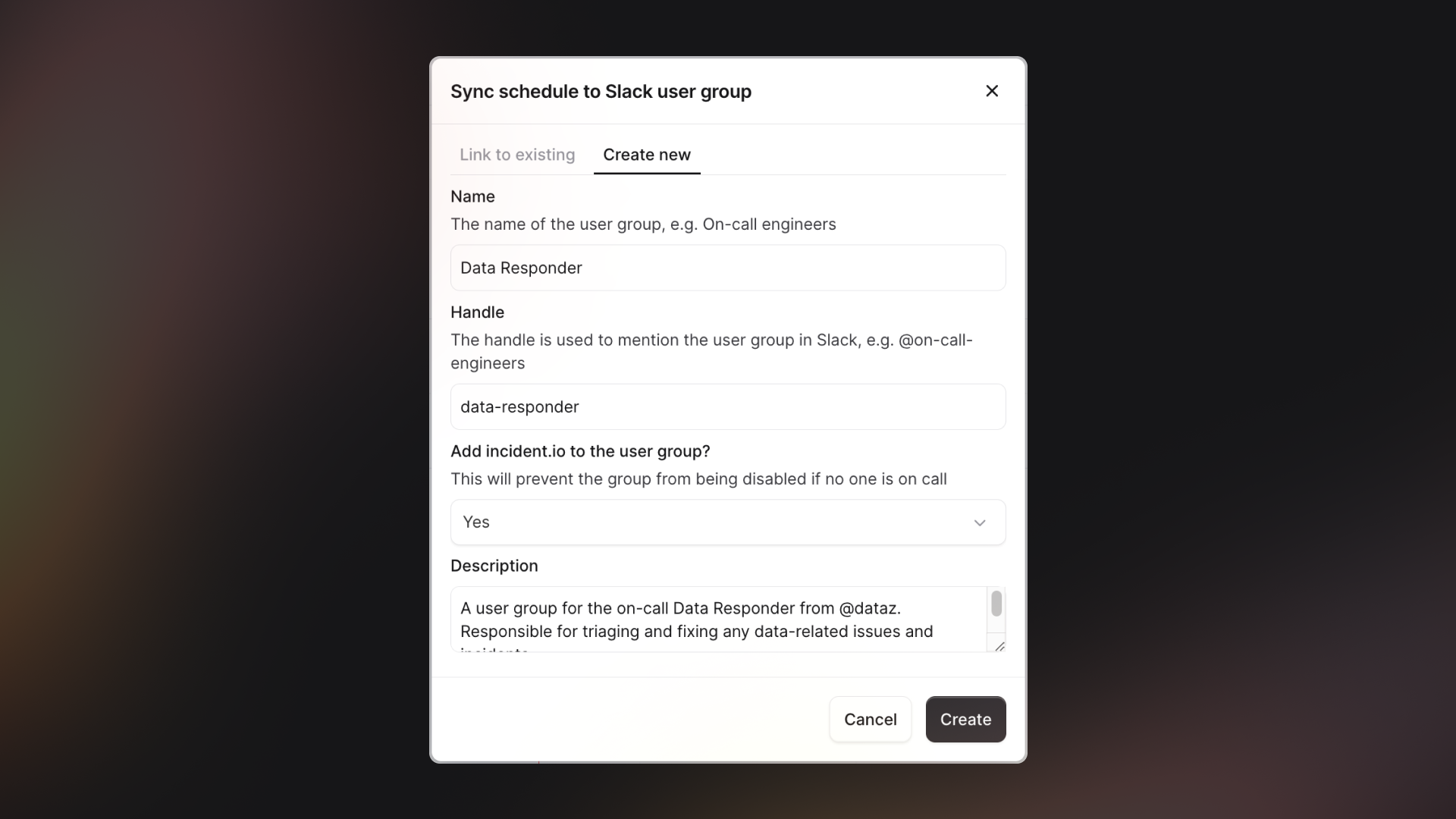
We’ve also recently added the ability to send cover requests from mobile, making it super easy to get a teammate to cover for you if you need.
How are alerts triggered?
We run our dbt pipeline hourly on CircleCI and have configured a workflow step to send an HTTP alert to the incident.io alerts API on model failures or test errors.
- run:
name: "Building alert payload"
when: on_fail
command: |
STATUS=$(cat /tmp/alert-status)
REPO="${CIRCLE_PROJECT_USERNAME}/${CIRCLE_PROJECT_REPONAME}"
TEAM=$(cat /tmp/alert-team)
FEATURES=$(cat /tmp/alert-features)
echo """
{
\"title\": \"${REPO} ${CIRCLE_JOB} failure\",
\"description\": \"${CIRCLE_JOB} failed on ${CIRCLE_BRANCH}\",
\"status\": \"${STATUS}\",
\"metadata\": {
\"source_url\": \"${CIRCLE_BUILD_URL}\",
\"repository\": \"${REPO}\",
\"branch\": \"${CIRCLE_BRANCH}\",
\"github_commit_url\": \"https://github.com/incident-io/dbt/commit/${CIRCLE_SHA1}\",
\"github_commit_message\": \"${GIT_COMMIT_MESSAGE}\",
}
}""" > /tmp/alert-payload.json
cat /tmp/alert-payload.jsonThe alert JSON payload contains useful information such as the link to the failed build in CircleCI, the most recent commit in the repo, etc. We’re also able to create custom attributes for the alert through the web app UI, using our nifty expressions builder:
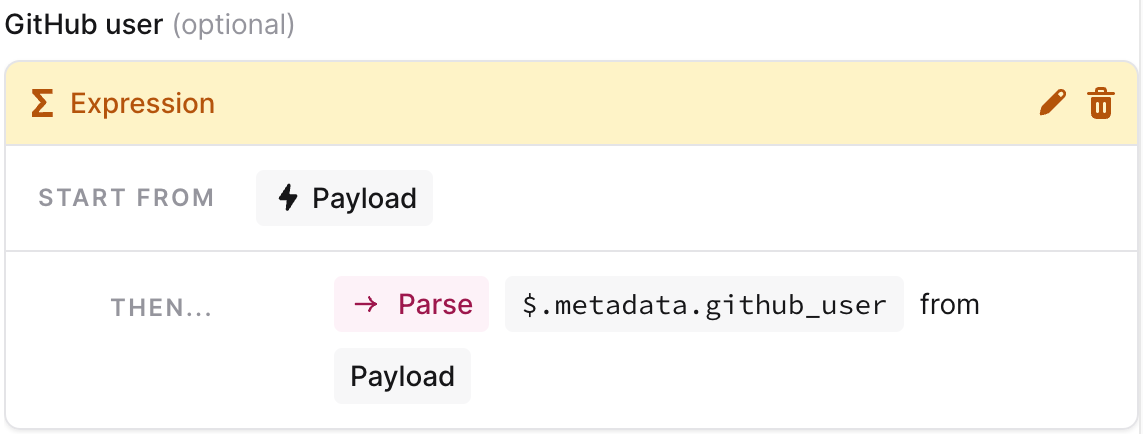
Being able to set these variable-based workflows is particularly valuable because our in-app analytics (e.g. Insights) are also powered by the same parent dbt run job. This means we’re able to route errors that have customer-facing impact to the team of on-call engineers (e.g. if the failure occurs overnight), and to the data team should it be an internal error, within working hours.
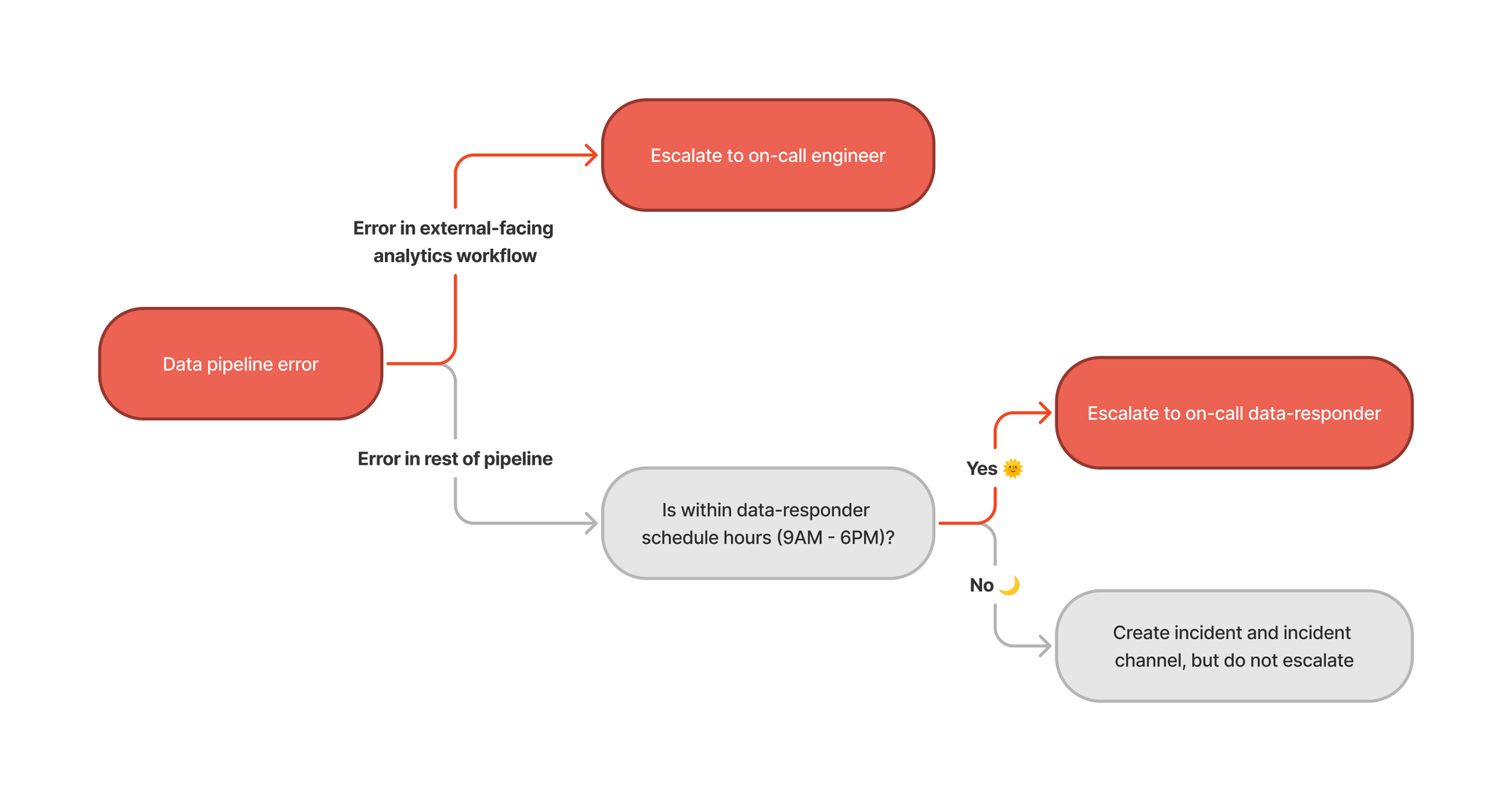
While there is a risk of “noise” when data incidents are auto-created off of alerts, at incident.io we have intentionally lowered the barrier to declaring incidents (data or otherwise), and often even create them preemptively for things that are likely to cause issues.
The way I like to think about it is that when it comes to the impact of incidents, false negatives are much more problematic than false positives, so the tradeoff here is well worth it. Even if the error does end up being transient, falling into the trap of normalizing failures as a one-off or flake is a dangerous path to go down.
Responding to the incident
Okay, you’ve gotten ahold of the right person and have joined the newly-created incident channel as the lead. While there isn’t really a one-size-fits-all approach to dealing with data-related incidents, a structured and well-documented incident management process goes a long way in making the process smoother and more effective.
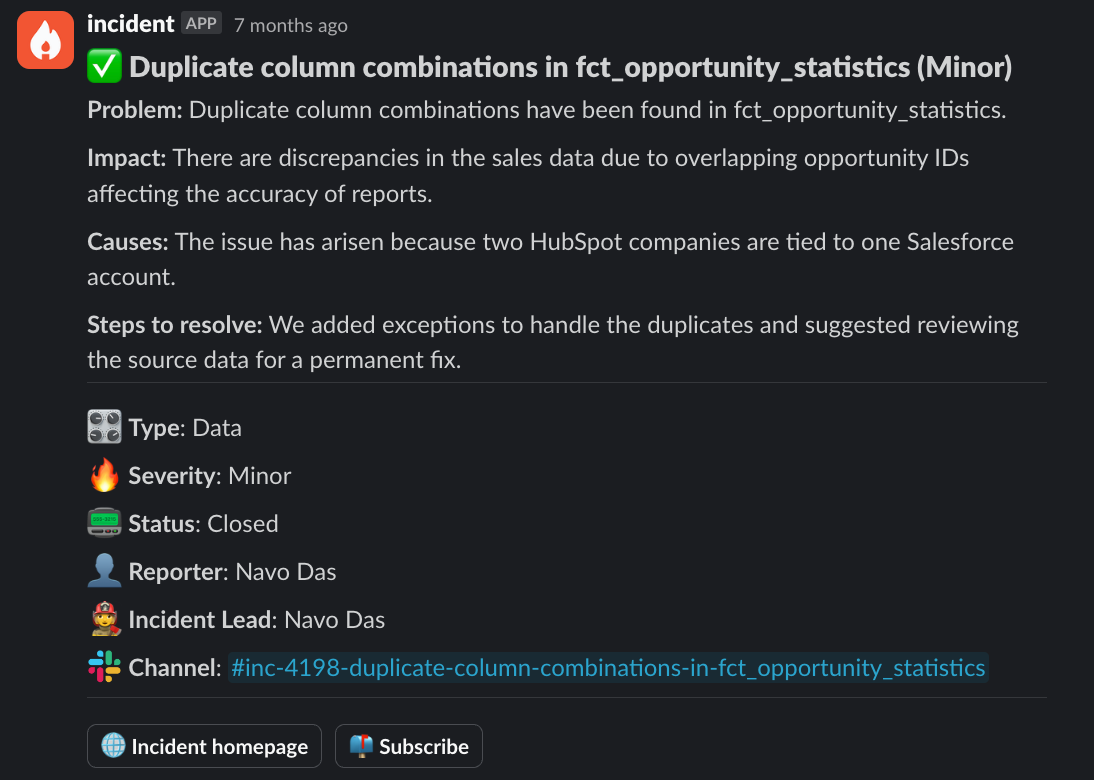
Creating a dedicated space for communication (such as a Slack channel) ensures that stakeholders are kept in the loop and avoids having to switch between multiple apps and tabs, allowing you to focus your efforts on identifying and resolving the root cause of the issue. Our product further enables that through useful features like:
- Attaching GitHub PRs to keep track of what fixes were shipped and their current deployment status
- AI-generated incident summaries, that analyze messages in the channel to create a succinct overview of the problem, impact, causes, and steps to resolve the issue
- Identifying similar incidents to see if a related incident has been previously created, and how it was dealt with last time
Closing the loop
It’s all too easy to brush an incident under the carpet once it’s resolved, but you risk losing valuable learnings from what you’ve just gone through, and not having the right processes or knowledge in place to avoid the incident from happening again (or worse, having someone else get stuck trying to fix it!).
For lower severity incidents (e.g. a test failure), follow-ups are a great way to keep a checklist of tasks with owners assigned, ensuring that appropriate guardrails are put in place to avoid the issue cropping up again. For bigger incidents (e.g. a data privacy issue), you might consider having a postmortem to reflect closer on the incident, and come up with process-based improvements.
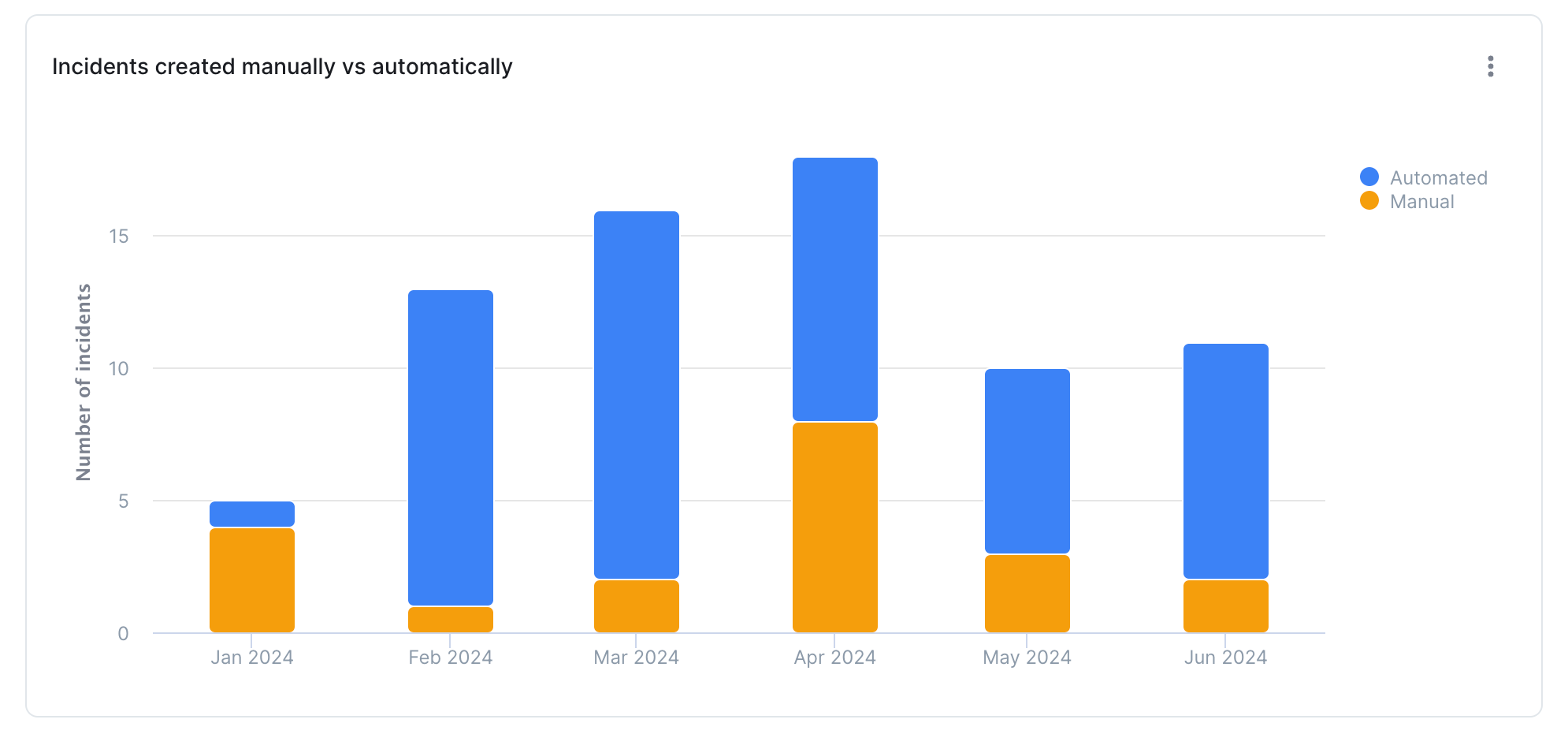
It’s also worth noting that conducting a meta-review of incident frequency/trends can help you identify common patterns in your data incidents (is it the same set of dbt models constantly erroring?), or even your incident response setup (is one person having to respond to significantly more requests than others?).
Conclusion
At the end of the day, data incidents are just like any other type of incident: they require prompt attention, clear ownership, and proactive communication of updates to stakeholders. Having a well defined data incident management process in place makes it a lot less stressful for our team when things inevitably break. Hopefully, with some of the ideas in this post, you can empower your data team to handle incidents more effectively too.

Navo Das
Data Analyst
See related articles

Pager fatigue: Making the invisible work visible
We developed The Fatigue Score to make sure our On-call responders’ efforts are visible. Here's how we did it, and how you can too.
 Matilda Hultgren
Matilda HultgrenApril 25, 2025

Going beyond MTTx and measuring “good” incident management
What does "good" incident management look like? MTTx metrics track speed, but speed alone doesn’t mean success. So, we decided to analyze 100,000+ incident from companies of all sizes to identify a set of new benchmarks for every stage of the incident lifecycle.
 Chris Evans
Chris EvansMarch 25, 2025

How we handle sensitive data in BigQuery
We take handling sensitive customer data seriously. This blog explains how we manage PII and confidential data in BigQuery through default masking, automated tagging, and strict access controls.
 Lambert Le Manh
Lambert Le ManhNovember 14, 2024
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


